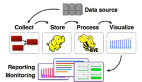
服務架構:大數據架構

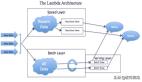
大數據架構是為處理超大數據量或復雜計算而設計的,流程上包括數據的獲取、處理和分析。
大數據,可以簡單理解為傳統數據庫無法處理的數據量,比如主從模式的MySQL在簡單場景下可以存儲和處理上億條數據,但涉及到分析場景,能處理的數據量可能遠遠小于1億。利用大數據架構,可以輕松處理上億到千億數據的分析需求。
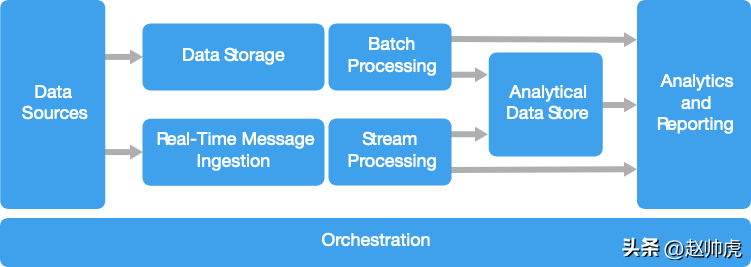
大數據架構通常支持這些使用方式:
- 離線靜態數據的批處理
- 實時動態數據的流式處理
- 大數據的交互式查詢(ad hoc query)
- 機器學習訓練和推理
多數大數據架構會包含下面這些組件:
數據源
所有大數據解決方案都必須從數據源開始,數據源有很多種,比如:
- 應用的數據存儲,比如傳統關系型數據庫MySQL等
- 應用產生的靜態文件,比如用戶行為日志
- 實時數據源,比如IoT設備
這些數據均來自于大數據系統外部,經過數據清洗等流程存儲到大數據系統。
數據存儲
離線批處理的數據通常存儲在分布式文件系統里,這些文件系統可以以不同的格式存儲大量的大文件,比如塊存儲HDFS上單個block的大小可以是256MB,總體可存儲PB量級的數據。當然,存儲也分為對象存儲和塊存儲,比如AWS S3是Amazon閉源的對象存儲方案,在擴展性和小文件支持上有一些優勢。
最近幾年,這類分布式塊存儲或文件存儲有一個更時髦的名字:數據湖。
批處理
由于數據量特別大,體現在數據條數多和占用磁盤空間大,大數據架構在應對分析場景時,通常采用耗時的批處理作業去處理數據,處理邏輯包括但不限于轉換、過濾、聚合等。這些批處理任務通常會 1)讀取源文件,2)處理數據,3)將結果寫入新文件。可選的技術有基于MapReduce/Spark的SQL,或使用Java/Scala/Python等編寫的MapReduce/Spark任務。
實時消息采集
如果數據源是實時的,那么架構上必須支持捕獲并存儲實時消息,以方便后面進行流式處理。使用的存儲可以非常簡單,比如直接append到一個目錄下的文件里。但現實中并不會采用這個方案,而是使用一個消息存儲充當buffer。這樣就能支持多個下游子系統進行獨立處理、保障數據不丟失、并獲取消息排隊的能力。
可選的技術有:Kafka、RocketMQ、RabbitMQ 等。
流式處理
從Source采集到實時消息以后,還需要對消息進行過濾、聚合等操作,用于后續的分析場景。流式數據被處理以后寫入Sink。
在這個領域,Flink是名副其實的第一,Flink SQL也是阿里最近幾年推行的重點方向,除此之外還有 Spark Structured Streaming,Storm 等技術方案。對比而言,Flink的生態更為完善,Streaming Warehouse也是基于Flink構建的。
分析型數據庫
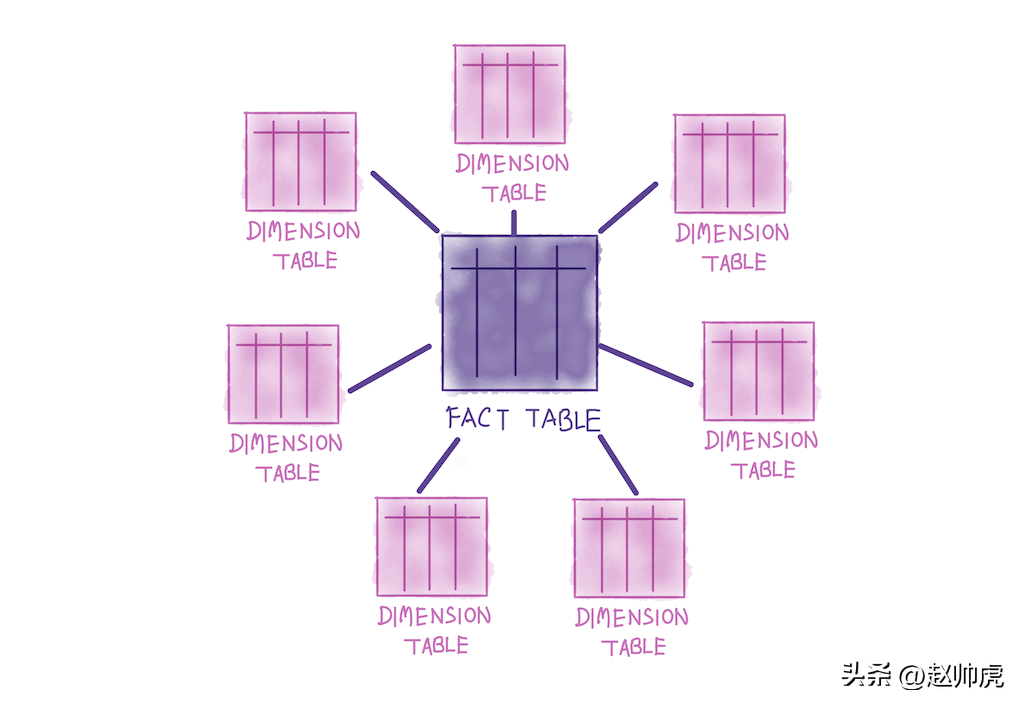
大數據系統的數據源通常是半結構化的數據,分析場景下為了保證性能,通常查詢的是結構化的數據表。在傳統商業BI系統中,數倉通常以Kimball維度數據倉庫理念進行建模,分析型數據庫支持在這種數據關系上的查詢。相對于Inmon理念,Kimball偏向于保持source不變,中間層做join,最終給業務提供一張大寬表,以滿足復雜多樣的分析需求。Kimball理念下的數據表關系呈現出典型的星型結構:
除了存算一體的分析型數據庫,還有其他方式,比如:
- 通過一個低延遲的NoSQL數據庫去管理和展現數據,比如HBase
- 基于分布式存儲(HDFS、S3等)管理數據+ Hive metastore 管理結構化信息,支持交互式的查詢
可選的技術有:交互式Hive、HBase、Spark SQL,目前流行的也有clickhouse、doris等能夠榨干機器性能的報表工具。
數據分析和報表
大數據方案的目標多數是通過分析和報表提供對數據的洞察能力。為了增強分析功能,我們通常在架構中會包含一個數據建模層,比如一個多維OLAP cube表。基于Clickhouse 或 Excel,用戶自己通過簡單的拖拽或點點點,就能做報表。對于懂一些技術的數據科學家和分析師而言,Jupyter Notebook提供了更強大和彈性的交互式分析能力,使用Python或R 可以更自由地訪問更大的數據集,可以更好地支持JOIN操作,也能將結果非常輕松地喂tensorflow/pytorch實現更高級的建模分析。
任務調度與編排
多數大數據方案都包含大量的重復計算。一個經典的工作流會包含:1)transform source 數據;2)在多個source和sink之間轉移數據;3)將處理過的數據寫入分析型數據庫;4)將結果寫入報表或儀表盤。為了把這些工作流自動化,我們可以使用一些編排工具,比如 Oozie、Sqoop 或大廠自研的那種。這些編排工具可以很好地處理任務的依賴關系,并嚴格按照依賴關系進行調度,通常也支持延遲報警、數據質量報警等功能。
上面討論的這些功能組件,目前有很多開源的技術來支持,比如 Hadoop 系列中的 HDFS、HBase、Hive、Spark、Oozie、Sqoop、Kafka,向量分析數據庫Clickhouse、Doris等。目前主流的云平臺基本都支持這些開源組件,但也基本上都會自研一些,比如阿里的Max Compute等等。
應用場景
- 存儲和處理的數據量遠遠超過了傳統數據庫的上限;
- 需要處理非結構化的數據,用于分析和報表;
- 采集、處理、分析實時流數據,或要求低延遲的場景;
架構優勢
- 技術選型比較多:可以采用Apache開源技術,也可以使用云服務商的閉源技術,或者混用;
- 并行帶來的極致性能:大數據架構充分利用了并行計算技術,能夠高性能地處理大批量數據;
- 彈性擴容:大數據的絕大多數組件都支持擴容,可以根據數據量和業務要求選擇物理資源,數據量增長時擴容的成本也不高;
- 與現存方案的兼容性:大數據組件既可以用于原始數據的采集,也可以用于頂層業務的數據分析,資源可以混合部署。
有哪些挑戰
- 架構復雜度高:大數據架構需要采集多個數據源的大量數據,包含了很多組件,非常復雜。一方面構建、測試和調試大數據處理任務比較麻煩;另一方面,由于組件太多,多個組件的配置需要協同更改,才能達到優化性能的目的;
- 技術棧多:很多大數據技術比較專,使用的框架和語言也多種多樣。好的一點是,大數據技術構建新的API時,采用了業界廣泛推行的語言,比如SQL;
- 技術成熟度不夠高:大數據技術仍然在不斷演進。隨著Hadoop的核心技術逐漸穩定下來,比如Hive、Pig、HDFS。新技術又不斷產生,比如Spark每次迭代都發布了大量的新特性。隨著Spark逐漸穩定,Flink、Clickhouse、Doris又崛起成為新的熱點;
- 安全性:大數據架構中,數據通常被存儲在一個中心化的數據湖里。安全合規地訪問這些數據卻愈發重要,在多個應用或平臺生產和消費數據的場景下尤其重要。
最佳實踐
- 充分利用并行計算。大數據架構通常會充分利用多臺機器的多核特點,將計算任務并行化,以提升性能。并行計算對數據的存儲格式有一定的要求,比如數據必須以能夠分隔的格式存儲。分布式文件系統(比如HDFS)能夠優化讀寫性能,在實際數據處理中由多個計算節點并行執行,減少了作業的整體運行時長。
- 利用分區。離線數據處理通常按照固定的周期,比如天/周/月級定期執行。把數據文件放到不同的日期分區里,用分區表把數據管理起來,分區的粒度可以與任務執行的時間頻率保持一致。這種模式簡化了數據采集和作業調度,問題排查也會比較簡單。目前主流的框架都支持分區概念,比如Hive分區表,分區作為過濾條件也可以大大縮減計算時掃描的數據量。現在流行的數據湖技術,在分區維度也做了很多優化,比如隱藏分區、bloomfilter索引、hash索引等。另外,在分區的基礎上,Spark 3 通過 bucket 優化shuffle數據量。
- 使用 schema-on-read 語義:數據湖概念出現以后,我們可以給文件定義不同的數據格式,數據格式是結構化、半結構化,或非結構化的。通過 schema-on-read 語義,我們可以在處理數據時,動態地給數據賦予格式,而不是在存儲時使用定義好的格式。這給我們的架構帶來了很多彈性,數據采集這一環,一定程度上避免了數據校驗或類型校驗帶來的問題。業界主流的方式仍然是在Hive提前創建好表結構,數據寫入時必須滿足結構限制,這樣下游的理解和接入成本比較低;另外,metadata使用中心化地存儲,還是去中心化,有很多考量因素,選擇schema-on-read模式前一定要慎重考慮。
- 就地處理數據。傳統的BI解決方案通常會通過extract-transform-load(ETL)任務將數據寫入數倉。對于數據量特別大、格式多種多樣的數據而言,通常會使用ETL的變種,比如 transform-extract-load (TEL)。使用這種方式,數據在分布式存儲內部被轉換為目標格式,這個過程可以存在多個任務,產出多個中間表。我們一般用數倉分層理論來規范表的名字和屬性,比如ODS、DWS、DWD、APP等。APP層的數據表符合分析場景的格式要求,可以將其數據拷貝到分析型數據庫(Clickhouse、ElasticSearch等)。
- 資源使用率 vs 運行時間。在創建批處理任務時,通常要考慮兩個方面:1)計算節點上每個計算單元(CPU核)的價格,2)完成一個作業使用的計算節點一分鐘花多少錢。舉個例子,一個批處理任務,用4個計算節點需要執行8小時。但仔細觀察發現,這4個節點在頭2個小時滿負荷運行,之后只有2個節點滿負荷運行。這種情況下,如果使用2個計算節點,作業總的執行時間變成10個小時,并沒有加倍;但花的錢變少了。為了緩解這個問題,多個用戶/業務共用一個隊列是一個簡單但不完美的方案,但從更高的層面上,離線/在線資源混合調度才是更大的全局最優解。
- 獨占資源。為了保障業務的正常運行,我們可以給不同類型的任務或業務分配獨占資源,包括計算和存儲。比如,對于離線處理,Spark/MapReduce 可以使用獨立的yarn隊列;對于Flink/Structured Streaming 任務,也使用獨立的yarn隊列;對于工作日上班時間的ad-hoc查詢,也可以分配獨立的隊列。當然,業務穩定運行、開發/調試方便和省錢有天然的沖突,要解決這個問題,需要付諸很多努力。
- 對數據采集任務進行編排。在一些簡單場景中,業務應用可以直接把文件寫入分布式存儲,然后供分析工具使用。但在大型互聯網公司中,通常不會這么干,而是把外部數據源的數據落到數據湖里,然后使用編排工具把作業統一管理起來,依賴關系同時被管理起來,以便穩定產出、高效地復用在下游復雜的業務場景里。任務開發、定期調度、依賴管理、延遲報警、失敗debug,這一切通常被維護在一個有Web頁面的公司級平臺里。
- 及早清理敏感數據。數據采集過程中,我們可以及早清理掉敏感數據,避免落庫。