云上大數(shù)據(jù)架構(gòu)是什么?
構(gòu)建大數(shù)據(jù)解決方案時(shí)應(yīng)使用哪個(gè)云提供商?
下圖展示了 AWS、Google Cloud 和 Microsoft Azure 的詳細(xì)比較。
解決方案的共同部分:
 圖片
圖片
構(gòu)建大數(shù)據(jù)解決方案時(shí)應(yīng)使用哪個(gè)云提供商?
下圖展示了 AWS、Google Cloud 和 Microsoft Azure 的詳細(xì)比較。
 圖片
圖片
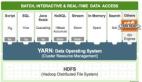
01 結(jié)構(gòu)化或非結(jié)構(gòu)化數(shù)據(jù)的數(shù)據(jù)攝取
數(shù)據(jù)攝取是指從各種來源(結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù))將數(shù)據(jù)導(dǎo)入系統(tǒng)的過程。數(shù)據(jù)可以來自數(shù)據(jù)庫、日志文件、傳感器數(shù)據(jù)、社交媒體等。
攝取方式有兩種:
- 批量攝取 (Batch Ingestion):數(shù)據(jù)以固定時(shí)間間隔批量導(dǎo)入系統(tǒng),適用于非實(shí)時(shí)性要求高的場(chǎng)景。
- 流式攝取 (Stream Ingestion):數(shù)據(jù)實(shí)時(shí)進(jìn)入系統(tǒng),適用于需要實(shí)時(shí)處理的場(chǎng)景,如物聯(lián)網(wǎng)數(shù)據(jù)、用戶行為分析等。
02 原始數(shù)據(jù)存儲(chǔ)
原始數(shù)據(jù)存儲(chǔ)是將攝取到的未經(jīng)處理的數(shù)據(jù)存儲(chǔ)到大容量的存儲(chǔ)系統(tǒng)中,以便后續(xù)處理。存儲(chǔ)可以是臨時(shí)存儲(chǔ),也可以是長(zhǎng)期歸檔存儲(chǔ)。
結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)在傳統(tǒng)數(shù)據(jù)庫中,如關(guān)系型數(shù)據(jù)庫。
非結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)在分布式文件系統(tǒng)中,如 HDFS(Hadoop Distributed File System)或云存儲(chǔ)(如 AWS S3、Azure Blob Storage、Google Cloud Storage)。
03 數(shù)據(jù)處理,包括過濾、轉(zhuǎn)換、規(guī)范化等
數(shù)據(jù)處理是對(duì)原始數(shù)據(jù)進(jìn)行清洗、過濾、轉(zhuǎn)換、規(guī)范化等操作的過程,以便為后續(xù)的分析和存儲(chǔ)做準(zhǔn)備。
04 數(shù)據(jù)倉庫,包括鍵值存儲(chǔ)、關(guān)系數(shù)據(jù)庫、OLAP 數(shù)據(jù)庫等
數(shù)據(jù)倉庫是為分析目的準(zhǔn)備的存儲(chǔ)系統(tǒng),能夠存儲(chǔ)處理后的數(shù)據(jù),支持復(fù)雜的查詢和數(shù)據(jù)分析。數(shù)據(jù)倉庫可以是關(guān)系型、鍵值存儲(chǔ)或 OLAP 數(shù)據(jù)庫。
鍵值存儲(chǔ)適合高性能的鍵值查詢,如 AWS DynamoDB、Azure Cosmos DB。
關(guān)系數(shù)據(jù)庫用于存儲(chǔ)結(jié)構(gòu)化數(shù)據(jù),支持 SQL 查詢,如 Amazon RDS、Google Cloud SQL。
OLAP(在線分析處理)數(shù)據(jù)庫適用于快速的多維數(shù)據(jù)分析和報(bào)表生成,如 Google BigQuery、Amazon Redshift、Azure Synapse Analytics。
05 演示層,包括儀表板和實(shí)時(shí)通知
演示層是最終用戶與數(shù)據(jù)交互的界面,通常以圖形化方式呈現(xiàn)數(shù)據(jù)分析結(jié)果。它包括儀表板、報(bào)表、實(shí)時(shí)通知等。
有趣的是,不同的云供應(yīng)商對(duì)同一類產(chǎn)品有不同的名稱。
例如,第一步和最后一步都使用了無服務(wù)器產(chǎn)品。該產(chǎn)品在 AWS 中稱為 “l(fā)ambda”,在 Azure 和 Google Cloud 中稱為 “function”。