













架構(gòu)師日記-從代碼到設(shè)計的性能優(yōu)化指南
一 前言
服務(wù)性能是指服務(wù)在特定條件下的響應(yīng)速度、吞吐量和資源利用率等方面的表現(xiàn)。據(jù)統(tǒng)計,性能優(yōu)化方面的精力投入,通常占軟件開發(fā)周期的10%到25%左右,當(dāng)然這和應(yīng)用的性質(zhì)和規(guī)模有關(guān)。性能對提高用戶體驗,保證系統(tǒng)可靠性,降低資源使用率,甚至增強(qiáng)市場競爭力等方面,都有著很大的影響。
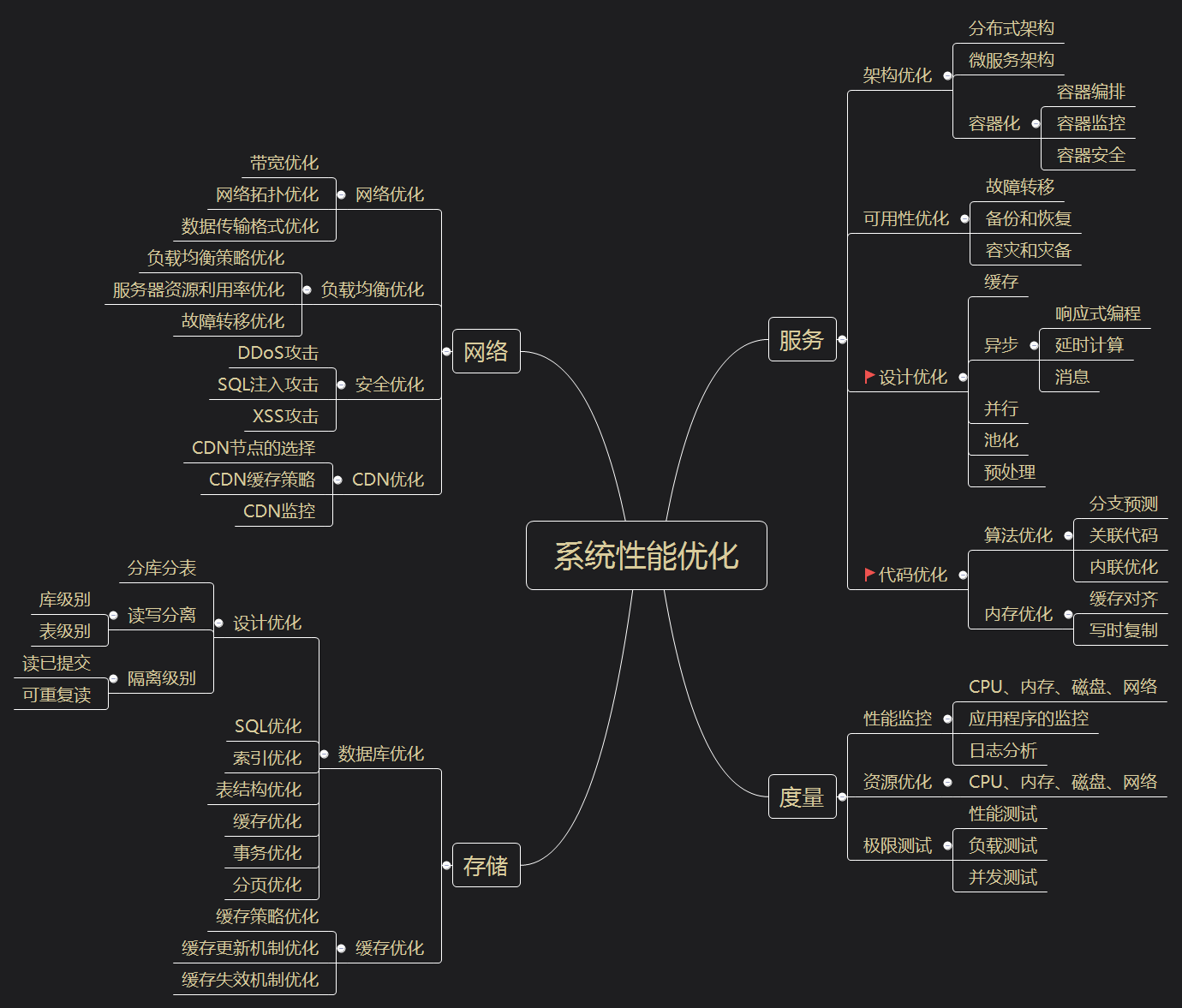
性能優(yōu)化是個系統(tǒng)性工程,宏觀上可分為網(wǎng)絡(luò),服務(wù),存儲幾個方向,每個方向又可以細(xì)分為架構(gòu),設(shè)計,代碼,可用性,度量等多個子項。本文將重點(diǎn)從代碼和設(shè)計兩個子項展開,談?wù)勀切┨嵘阅艿闹R點(diǎn)。當(dāng)然,很多性能提升策略都是有代價的,適用于某些特定場景,大家在學(xué)習(xí)和使用的時候,最好帶著批判的思維,決策前,做好利弊權(quán)衡。
先簡單羅列一下性能優(yōu)化方向:
二 代碼優(yōu)化
2.1 關(guān)聯(lián)代碼
關(guān)聯(lián)代碼優(yōu)化是通過預(yù)加載相關(guān)代碼,避免在運(yùn)行時加載目標(biāo)代碼,造成運(yùn)行時負(fù)擔(dān)。我們知道Java有兩個類加載器:Bootstrap class loader和Application class loader。Bootstrap class loader負(fù)責(zé)加載Java API中包含的核心類,而Application class loader則負(fù)責(zé)加載自定義類。關(guān)聯(lián)代碼優(yōu)化可以通過以下幾種方式來實現(xiàn)。
預(yù)加載關(guān)聯(lián)
預(yù)加載關(guān)聯(lián)類是指在程序啟動時預(yù)先加載目標(biāo)與關(guān)聯(lián)類,以避免在運(yùn)行時加載。可以通過靜態(tài)代碼塊來實現(xiàn)預(yù)加載,如下所示:
public class MainClass {
static {
// 預(yù)加載MyClass,其實現(xiàn)了相關(guān)功能
Class.forName("com.example.MyClass");
}
// 運(yùn)行相關(guān)功能的代碼
// ...
}使用線程池
線程池可以讓多個任務(wù)使用同一個線程池中的線程,從而減少線程的創(chuàng)建和銷毀成本。使用線程池時,可以在程序啟動時創(chuàng)建線程池,并在主線程中預(yù)加載相關(guān)代碼。然后以異步方式使用線程池中的線程來執(zhí)行相關(guān)代碼,可以提高程序的性能。
使用靜態(tài)變量
可以使用靜態(tài)變量來緩存與關(guān)聯(lián)代碼有關(guān)的對象和數(shù)據(jù)。在程序啟動時,可以預(yù)先加載關(guān)聯(lián)代碼,并將對象或數(shù)據(jù)存儲在靜態(tài)變量中。然后在程序運(yùn)行時使用靜態(tài)變量中緩存的對象或數(shù)據(jù),以避免重復(fù)加載和生成。這種方式可以有效地提高程序的性能,但需要注意靜態(tài)變量的使用,確保它們在多線程環(huán)境中的安全性。
2.2 緩存對齊
在介紹緩存對齊之前,需要先普及一些CPU指令執(zhí)行的相關(guān)知識。
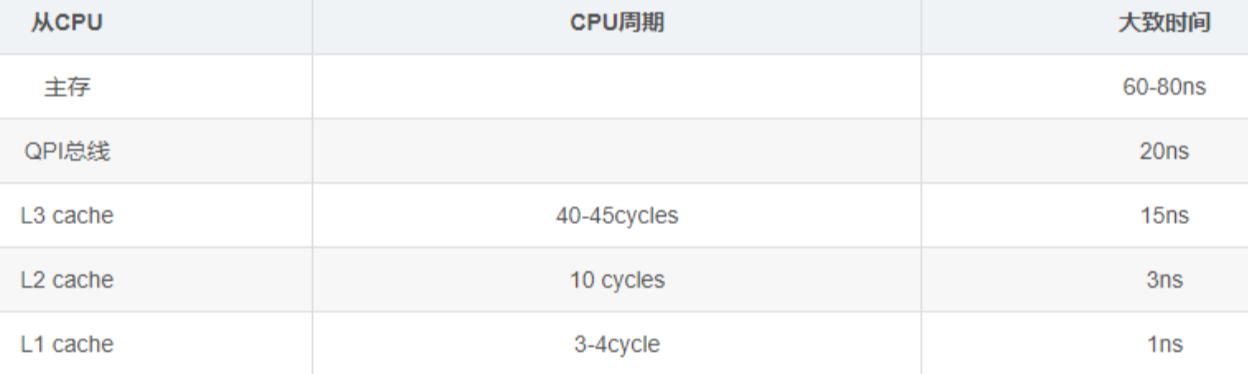
- 緩存行(Cache line):CPU讀取內(nèi)存數(shù)據(jù)時并非一次只讀一個字節(jié),一般是會讀一段64字節(jié)(硬件決定)長度的連續(xù)的內(nèi)存塊(chunks of memory),這些塊我們稱之為緩存行。
- 偽共享(False Sharing):當(dāng)運(yùn)行在兩個不同CPU上的兩個線程寫入兩個不同的變量時,如果這兩個變量恰好存儲在同一個 CPU 緩存行中,就會發(fā)生偽共享(False Sharing)。即當(dāng)?shù)谝粋€線程修改緩存行中其中一個變量時,其他引用此緩存行變量的線程的緩存行將會無效。如果CPU需要讀取失效的緩存行,它必須等待緩存行刷新,這會導(dǎo)致性能下降。
- CPU停止運(yùn)轉(zhuǎn)(stall):當(dāng)一個核心需要等待另一個核心重新加載緩存行時(出現(xiàn)偽共享時),它無法繼續(xù)執(zhí)行下一條指令,只能停止運(yùn)轉(zhuǎn)等待,這被稱之為stall。減少偽共享也就意味著減少了stall的發(fā)生。
- IPC(instructions per cycle):它表示平均每個 CPU 周期執(zhí)行的指令數(shù)量,很顯然該數(shù)值越大性能越好。可以基于IPC指標(biāo)(比如:閾值1.0)來簡單判斷程序是屬于訪問密集型還是計算密集型。Linux系統(tǒng)中可以通過tiptop命令來查看每個進(jìn)程的CPU硬件數(shù)據(jù):

如何簡單來區(qū)分訪存密集型和計算密集型程序?
1. 如果 IPC < 1.0, 很可能是 Memory stall 占主導(dǎo),多半意味著訪存密集型。
2. 如果IPC > 1.0, 很可能是計算密集型的程序。
- CPU利用率:是指系統(tǒng)中CPU處于忙碌狀態(tài)的時間與總時間的比例。忙碌狀態(tài)時間又可以進(jìn)一步拆分為指令(instruction)執(zhí)行消耗周期cycle(%INS) 和 stalled 的周期cycle(%STL)。perf 采集了10秒內(nèi)全部 CPU 的運(yùn)行狀態(tài):
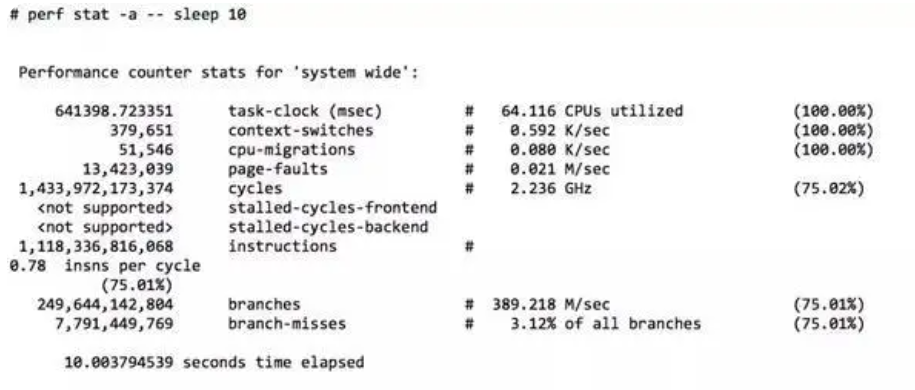
IPC計算
IPC = instructions/cycles
上圖中,可以計算出結(jié)果為:0.79
現(xiàn)代處理器一般有多條流水線(比如:4核心),運(yùn)行 perf 的那臺機(jī)器,IPC的理論值可達(dá)到4.0。
如果我們從 IPC的角度來看,這臺機(jī)器只運(yùn)行到其處理器最高速度的 19.7%(0.79 / 4.0)。總之,通過Top命令,看到CPU使用率之后,可以進(jìn)一步分析指令執(zhí)行消耗周期和 stalled 周期,有這些更詳細(xì)的指標(biāo)之后,就能夠知道該如何更好地對應(yīng)用和系統(tǒng)進(jìn)行調(diào)優(yōu)。
- 緩存對齊:是通過調(diào)整數(shù)據(jù)在內(nèi)存中的分布,讓數(shù)據(jù)在被緩存時,更有利于CPU從緩存中讀取,從而避免了頻繁的內(nèi)存讀取,提高了數(shù)據(jù)訪問的速度。
緩存填充(Padding)
減少偽共享也就意味著減少了stall的發(fā)生,其中一個手段就是通過填充(Padding)數(shù)據(jù)的形式,即在適當(dāng)?shù)木嚯x處插入一些對齊的空間來填充緩存行,從而使每個線程的修改不會臟污同一個緩存行。
/**
* 緩存行填充測試
*
* @author liuhuiqing
* @date 2023年04月28日
*/
public class FalseSharingTest {
private static final int LOOP_NUM = 1000000000;
public static void main(String[] args) throws InterruptedException {
Struct struct = new Struct();
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (int i = 0; i < LOOP_NUM; i++) {
struct.x++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < LOOP_NUM; i++) {
struct.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("cost time [" + (System.currentTimeMillis() - start) + "] ms");
}
static class Struct {
// 共享變量
volatile long x;
// 一個long占用8個字節(jié),此處定義7個填充數(shù)據(jù),來保證業(yè)務(wù)數(shù)據(jù)x和y分布在不同的緩存行中
long p1, p2, p3, p4, p5, p6, p7;
// long[] paddings = new long[7];// 使用數(shù)組代替不會生效,思考一下,為什么?
// 共享變量
volatile long y;
}
}經(jīng)過本地測試,這種以空間換時間的方式,即實現(xiàn)了緩存行數(shù)據(jù)對齊的方式,在執(zhí)行效率方面,比沒有對齊之前,提高了5倍!
@Contended注解
在Java 8中,引入了@Contended注解,該注解可以用來告訴JVM對字段進(jìn)行緩存對齊(將字段放入不同的緩存行),從而提高程序的性能。使用@Contended注解時,需要在JVM啟動時添加參數(shù)-XX:-RestrictContended,實現(xiàn)如下所示:
import sun.misc.Contended;
public class ContendedTest {
@Contended
volatile long a;
@Contended
volatile long b;
public static void main(String[] args) throws InterruptedException {
ContendedTest c = new ContendedTest();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 10000_0000L; i++) {
c.a = i;
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 10000_0000L; i++) {
c.b = i;
}
});
final long start = System.nanoTime();
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println((System.nanoTime() - start) / 100_0000);
}
}對齊內(nèi)存與本地變量
緩存填充是解決CPU偽共享問題的解決方案之一,在實際應(yīng)用中,是否還有其它方案來解決這一問題呢?答案是有的:即對齊內(nèi)存和本地變量。
- 對齊內(nèi)存:內(nèi)存行的大小一般為64個字節(jié),這個大小是硬件決定的,但大多數(shù)編譯器默認(rèn)情況下都以4字節(jié)的邊界對齊,通過將變量按照內(nèi)存行的大小對齊,可以避免偽共享問題;
- 本地變量:在不同線程之間使用不同的變量存儲數(shù)據(jù),避免不同的線程之間共享同一塊內(nèi)存,Java中的ThreadLocal就是一種典型的實現(xiàn)方式;
2.3 分支預(yù)測
分支預(yù)測是CPU動態(tài)執(zhí)行技術(shù)中的主要內(nèi)容,是通過猜測程序中的分支語句(如if-else語句或者循環(huán)語句)的執(zhí)行路徑來提高CPU執(zhí)行效率的技術(shù)。其原理是根據(jù)之前的歷史記錄和統(tǒng)計數(shù)據(jù),預(yù)測程序下一步要執(zhí)行的指令是分支跳轉(zhuǎn)指令還是順序執(zhí)行指令,從而提前加載相關(guān)數(shù)據(jù),減少CPU等待指令執(zhí)行的空閑時間。預(yù)測準(zhǔn)確率越高,CPU的性能提升就越高。那么如何提高預(yù)測的準(zhǔn)確率呢?
- 關(guān)注圈復(fù)雜度
過多的條件語句和嵌套的條件語句會導(dǎo)致分支的預(yù)測難度大幅上升,從而降低分支預(yù)測的準(zhǔn)確率和效率。一般來說,可以通過優(yōu)化代碼邏輯結(jié)構(gòu)、減少冗余等方式來避免過多的條件語句和嵌套的條件語句。
- 優(yōu)先處理常用路徑
在編寫代碼時,應(yīng)該優(yōu)先處理常用路徑,以減少CPU對分支的預(yù)測,提高預(yù)測準(zhǔn)確率和效率。例如,在if-else語句中,應(yīng)該將常用的路徑放在if語句中,而將不常用的路徑放在else語句中。
2.4 寫時復(fù)制
Copy-On-Write (COW)是一種內(nèi)存管理機(jī)制,也被稱為寫時復(fù)制。其主要思想是在需要寫入數(shù)據(jù)時,先進(jìn)行數(shù)據(jù)拷貝,然后再進(jìn)行操作,從而避免了對數(shù)據(jù)進(jìn)行不必要的復(fù)制和操作。COW機(jī)制可以有效地降低內(nèi)存使用率,提高程序的性能。
在創(chuàng)建進(jìn)程或線程的時候,操作系統(tǒng)為其分配內(nèi)存時,不是復(fù)制一個完整的物理地址空間,而是創(chuàng)建一個指向父進(jìn)程/線程物理地址空間的虛擬地址空間,并為它們的所有頁面設(shè)置"只讀"標(biāo)志。當(dāng)子進(jìn)程/線程需要修改頁面時,會觸發(fā)一個缺頁異常,并將涉及到的頁面進(jìn)行數(shù)據(jù)的復(fù)制,并為復(fù)制的頁面重新分配內(nèi)存。子進(jìn)程/線程只能夠操作復(fù)制后的地址空間,父進(jìn)程/線程的原始內(nèi)存空間則被保留。
由于COW機(jī)制在寫入之前進(jìn)行數(shù)據(jù)拷貝,所以可以有效地避免頻繁的內(nèi)存拷貝和分配操作,降低了內(nèi)存的占用率,提高了程序的性能。并且,COW機(jī)制也避免了數(shù)據(jù)的不必要復(fù)制,從而減少了內(nèi)存的消耗和內(nèi)存碎片的產(chǎn)生,提高了系統(tǒng)中可用內(nèi)存的數(shù)量。
ArrayList類可以使用Copy-On-Write機(jī)制來提高性能。
// 初始化數(shù)組
private List<String> list = new CopyOnWriteArrayList<>();
// 向數(shù)組中添加元素
list.add("value");需要注意的是,Copy-On-Write機(jī)制適用于讀操作比寫操作多的情況,因為它假定寫操作的頻率較低,從而可以通過犧牲復(fù)制的開銷來減少鎖的操作和內(nèi)存分配的消耗。
2.5 內(nèi)聯(lián)優(yōu)化
在Java中,每次調(diào)用方法都需要進(jìn)行一些額外的操作,例如創(chuàng)建堆棧幀、保存寄存器狀態(tài)等,這些額外的操作會消耗一定的時間和內(nèi)存資源。內(nèi)聯(lián)優(yōu)化是一種編譯器優(yōu)化技術(shù),Java虛擬機(jī)通常使用即時編譯器(JIT)來進(jìn)行方法內(nèi)聯(lián),用于提高程序的性能。內(nèi)聯(lián)優(yōu)化的目標(biāo)是將函數(shù)的調(diào)用替換成函數(shù)本身的代碼,以減少函數(shù)調(diào)用的開銷,從而提高程序的運(yùn)行效率。
需要注意的是,方法內(nèi)聯(lián)并不是在所有情況下都能夠提高程序的運(yùn)行效率。如果方法內(nèi)聯(lián)導(dǎo)致代碼復(fù)雜度增加或者內(nèi)存占用增加,反而會降低程序的性能。因此,在使用方法內(nèi)聯(lián)時需要根據(jù)具體情況進(jìn)行權(quán)衡和優(yōu)化。
final修飾符
final修飾符可以使方法成為不可重寫的方法。因為不可重寫,所以在編譯器優(yōu)化時可以將它們的代碼嵌入到調(diào)用它們的代碼中,從而避免函數(shù)調(diào)用的開銷。使用final修飾符可以在一定程度上提高程序的性能,但同時也減弱了代碼的可擴(kuò)展性。
限制方法長度
方法的長度會影響其在編譯時能否被內(nèi)聯(lián)。通常情況下,長度較小的方法更容易被內(nèi)聯(lián)。因此,可以在設(shè)計中將代碼分解和重構(gòu)為更小的函數(shù)。這種方式并不是100%確保可以內(nèi)聯(lián),但至少提高了實現(xiàn)此優(yōu)化的機(jī)會。內(nèi)聯(lián)調(diào)優(yōu)參數(shù),如下表格:
JVM參數(shù) | 默認(rèn)值 (JDK 8, Linux x86_64) | 參數(shù)說明 |
-XX:MaxInlineSize=<n> | 35 字節(jié)碼 | 內(nèi)聯(lián)方法大小上限 |
-XX:FreqInlineSize=<n> | 325 字節(jié)碼 | 內(nèi)聯(lián)熱方法的最大值 |
-XX:InlineSmallCode=<n> | 1000字節(jié)的原生代碼(非分層) 2000字節(jié)的原生代碼(分層編譯) | 如果最后一層的的分層編譯代碼量已經(jīng)超過這個值,就不進(jìn)行內(nèi)聯(lián)編譯 |
-XX:MaxInlineLevel=<n> | 9 | 調(diào)用層級比這個值深的話,就不進(jìn)行內(nèi)聯(lián) |
內(nèi)聯(lián)注解
在Java 5之后,引入了內(nèi)聯(lián)注解@inline,使用此注解可以在編譯時通知編譯器,將該方法內(nèi)聯(lián)到它的調(diào)用處。注解@inline在Java 9之后已經(jīng)被棄用,可以使用@ForceInline注釋來替代,同時設(shè)置JVM參數(shù):
-XX:+UnlockExperimentalVMOptions -XX:+EnableJVMCI -XX:+JVMCICompiler@ForceInline
public static int add(int a, int b) {
return a + b;
}2.6 編碼優(yōu)化
反射機(jī)制
Java反射在一定程度上會影響性能,因為它需要在運(yùn)行時進(jìn)行類型檢查轉(zhuǎn)換和方法查找,這比直接調(diào)用方法會更耗時。此外,反射也不會受到編譯器的優(yōu)化,因此可能會導(dǎo)致更慢的代碼執(zhí)行速度。
要解決這個問題有以下幾種方式:
- 盡可能使用原生方法調(diào)用,而不是通過反射調(diào)用;
- 盡可能緩存反射調(diào)用結(jié)果,避免重復(fù)調(diào)用。例如,可以將反射結(jié)果緩存到靜態(tài)變量中,以便下次使用時直接獲取,而不必再次使用反射;
- 使用字節(jié)碼增強(qiáng)技術(shù);
下面著重介紹一下反射結(jié)果緩存和字節(jié)碼增強(qiáng)兩種方案。
- 反射結(jié)果緩存可以大幅減少反射過程中的類型檢查,類型轉(zhuǎn)換和方法查找等動作,是降低反射對程序執(zhí)行效率影響的一種優(yōu)化策略。
/**
* 反射工具類
*
* @author liuhuiqing
* @date 2023年5月7日
*/
public abstract class BeanUtils {
private static final Logger LOGGER = LoggerFactory.getLogger(BeanUtils.class);
private static final Field[] NO_FIELDS = {};
private static final Map<Class<?>, Field[]> DECLARED_FIELDS_CACHE = new ConcurrentReferenceHashMap<Class<?>, Field[]>(256);
private static final Map<Class<?>, Field[]> FIELDS_CACHE = new ConcurrentReferenceHashMap<Class<?>, Field[]>(256);
/**
* 獲取當(dāng)前類及其父類的屬性數(shù)組
*
* @param clazz
* @return
*/
public static Field[] getFields(Class<?> clazz) {
if (clazz == null) {
throw new IllegalArgumentException("Class must not be null");
}
Field[] result = FIELDS_CACHE.get(clazz);
if (result == null) {
Field[] fields = NO_FIELDS;
Class<?> searchType = clazz;
while (Object.class != searchType && searchType != null) {
Field[] tempFields = getDeclaredFields(searchType);
fields = mergeArray(fields, tempFields);
searchType = searchType.getSuperclass();
}
result = fields;
FIELDS_CACHE.put(clazz, (result.length == 0 ? NO_FIELDS : result));
}
return result;
}
/**
* 獲取當(dāng)前類屬性數(shù)組(不包含父類的屬性)
*
* @param clazz
* @return
*/
public static Field[] getDeclaredFields(Class<?> clazz) {
if (clazz == null) {
throw new IllegalArgumentException("Class must not be null");
}
Field[] result = DECLARED_FIELDS_CACHE.get(clazz);
if (result == null) {
result = clazz.getDeclaredFields();
DECLARED_FIELDS_CACHE.put(clazz, (result.length == 0 ? NO_FIELDS : result));
}
return result;
}
/**
* 數(shù)組合并
*
* @param array1
* @param array2
* @param <T>
* @return
*/
public static <T> T[] mergeArray(final T[] array1, final T... array2) {
if (array1 == null || array1.length < 1) {
return array2;
}
if (array2 == null || array2.length < 1) {
return array1;
}
Class<?> compType = array1.getClass().getComponentType();
int newArrLength = array1.length + array2.length;
T[] newArr = (T[]) Array.newInstance(compType, newArrLength);
int firstArrayLen = array1.length;
System.arraycopy(array1, 0, newArr, 0, firstArrayLen);
try {
System.arraycopy(array2, 0, newArr, firstArrayLen, array2.length);
} catch (ArrayStoreException ase) {
final Class<?> type2 = array2.getClass().getComponentType();
if (!compType.isAssignableFrom(type2)) {
throw new IllegalArgumentException("Cannot store " + type2.getName() + " in an array of "
+ compType.getName(), ase);
}
throw ase;
}
return newArr;
}
}- 字節(jié)碼增強(qiáng)技術(shù),一般使用第三方庫來實現(xiàn),例如Javassist或Byte Buddy,在運(yùn)行時生成字節(jié)碼,從而避免使用反射。
為什么動態(tài)字節(jié)碼生成方式相比反射也可以提高執(zhí)行效率呢?
- 動態(tài)字節(jié)碼生成的方式在編譯期就已經(jīng)將類型信息確定下來,無需進(jìn)行類型檢查和轉(zhuǎn)換;
- 動態(tài)字節(jié)碼生成的方式可以直接調(diào)用方法,無需查找,提高了執(zhí)行效率;
- 動態(tài)字節(jié)碼生成的方式只需要在生成字節(jié)碼時獲取一次Method對象,多次調(diào)用時可以直接使用,避免了重復(fù)獲取Method對象的開銷;
這里就不再舉例說明了,感興趣的同學(xué)可以自行查閱資料進(jìn)行深入學(xué)習(xí)。
異常處理
有效的處理異常可以保證程序的穩(wěn)定性和可靠性。但異常的處理對性能還是有一定的影響的,這一點(diǎn)常常被人忽視。影響性能的具體表現(xiàn)為:
- 響應(yīng)延遲:當(dāng)異常被拋出時,Java虛擬機(jī)需要查找并執(zhí)行相應(yīng)的異常處理程序,這會導(dǎo)致一定的延遲。如果程序中存在大量的異常處理,這些延遲可能會累積,導(dǎo)致程序的整體性能下降。
- 內(nèi)存占用:異常處理需要在堆棧中創(chuàng)建異常對象,這些對象需要占用內(nèi)存。如果程序中存在大量的異常處理,這些異常對象可能會占用大量的內(nèi)存,導(dǎo)致程序的整體內(nèi)存占用量增加。
- CPU占用:異常處理需要執(zhí)行額外的代碼,這會導(dǎo)致CPU占用率增加。如果程序中存在大量的異常處理,這些額外的代碼可能會導(dǎo)致CPU占用率過高,導(dǎo)致程序的整體性能下降。
一些基準(zhǔn)測試顯示,異常處理可能會導(dǎo)致程序的性能下降幾個百分點(diǎn)。在Java虛擬機(jī)規(guī)范中提到,在沒有異常發(fā)生的情況下,基于堆棧的方法調(diào)用可能比基于異常的方法調(diào)用快2-3倍。此外,一些實驗表明,在異常處理程序中使用大量的try-catch語句,可能會導(dǎo)致性能下降10倍以上。
為避免這些問題,在編寫代碼時謹(jǐn)慎地使用異常處理機(jī)制,并確保對異常進(jìn)行適當(dāng)?shù)挠涗浐蛨蟾妫苊膺^度使用異常處理機(jī)制。
日志處理
先看以下代碼:
LOGGER.info("result:" + JsonUtil.write2JsonStr(contextAdContains) + ", logid = " + DigitThreadLocal.getLogId());以上示例代碼中,類似的日志打印方式很常見,難道有什么問題嗎?
- 性能問題:每次使用+進(jìn)行字符串拼接時,都會創(chuàng)建一個新的字符串對象,這可能會導(dǎo)致內(nèi)存分配和垃圾回收的開銷增加;
- 可讀性問題:使用+進(jìn)行字符串拼接時,代碼可能會變得難以閱讀和理解,特別是在需要連接多個字符串時;
- 如果日志級別調(diào)整到ERROR模式,我們希望日志的字符串內(nèi)容不需要進(jìn)行加工計算,但這種寫法,即使日志處于不需要打印的模式,日志內(nèi)容也進(jìn)行了無效計算;
特別實在請求量和日志打印量比較高的場景下,日志內(nèi)容的序列化和寫文件操作,對服務(wù)的耗時影響可以達(dá)到10%,甚至更多。
臨時對象
臨時對象通常是指在方法內(nèi)部創(chuàng)建的對象。大量創(chuàng)建臨時對象會導(dǎo)致Java虛擬機(jī)頻繁進(jìn)行垃圾回收,從而影響程序的性能。也會占用大量的內(nèi)存空間,從而導(dǎo)致程序崩潰或者出現(xiàn)內(nèi)存泄漏等問題。
為了避免大量創(chuàng)建臨時對象,在編碼時,可以采取以下措施:
- 字符串拼接中,使用StringBuilder或StringBuffer進(jìn)行字符串拼接,避免使用連接符,每次都創(chuàng)建新的字符串對象;
- 在集合操作中,盡量使用批量操作,如addAll、removeAll等,避免頻繁的add、remove操作,觸發(fā)數(shù)組的擴(kuò)容或者縮容;
- 在正則表達(dá)式中,可以使用Pattern.compile()方法預(yù)編譯正則表達(dá)式,避免每次都創(chuàng)建新的Matcher對象;
- 盡量使用基本數(shù)據(jù)類型,避免使用包裝類,因為包裝類的創(chuàng)建和銷毀都會產(chǎn)生臨時對象;
- 盡量使用對象池的方式創(chuàng)建和管理對象,比如使用靜態(tài)工廠方法創(chuàng)建對象,避免使用new關(guān)鍵字創(chuàng)建對象,因為靜態(tài)工廠方法可以重用對象,避免創(chuàng)建新的臨時對象;
臨時對象的生命周期應(yīng)該盡可能短,以便及時釋放內(nèi)存資源。臨時對象的生命周期過長通常是由以下原因引起的:
- 對象未被正確地釋放:如果在方法執(zhí)行完畢后,臨時對象沒有被正確地釋放,就會導(dǎo)致內(nèi)存泄漏風(fēng)險;
- 對象過度共享:如果臨時對象被過度共享,就可能會導(dǎo)致多個線程同時訪問同一個對象,從而導(dǎo)致線程安全問題和性能問題;
- 對象創(chuàng)建過于頻繁:如果在方法內(nèi)部頻繁地創(chuàng)建臨時對象,就會導(dǎo)致內(nèi)存開銷過大,可能會引起性能甚至內(nèi)存溢出問題;
為避免臨時對象的生命周期過長,建議采取以下措施:
- 及時釋放對象:在方法執(zhí)行完畢后,應(yīng)該及時釋放臨時對象(比如主動將對象設(shè)置為null),以便回收內(nèi)存資源;
- 避免過度共享:在多線程環(huán)境下,應(yīng)該避免過度共享臨時對象,可以使用局部變量或ThreadLocal等方式來避免共享問題;
- 對象池技術(shù):使用對象池技術(shù)可以避免頻繁創(chuàng)建臨時對象,從而降低內(nèi)存開銷。對象池可以預(yù)先創(chuàng)建一定數(shù)量的對象,并在需要時從池中獲取對象,使用完畢后再將對象放回池中;
小結(jié)
正所謂:“不積跬步,無以至千里;不積小流,無以成江海”。以上列舉的編碼細(xì)節(jié),都會直接或間接的影響服務(wù)的執(zhí)行效率,只是影響多少的問題。現(xiàn)實中,有時候我們不必過于苛求,但它們有一個共同的注腳:極客精神。
三 設(shè)計優(yōu)化
3.1 緩存
合理使用緩存可以有效提高應(yīng)用程序的性能,縮短數(shù)據(jù)訪問時間,降低對數(shù)據(jù)源的依賴性。緩存可以進(jìn)行多層級的設(shè)計,舉例,為了提高運(yùn)行效率,CPU就設(shè)計了L1-L3三級緩存。在應(yīng)用設(shè)計的時候,我們也可以按照業(yè)務(wù)訴求進(jìn)行層設(shè)計。常見的分層設(shè)計有本地緩存(L1),遠(yuǎn)程分布式緩存(L2)兩級。
本地緩存可以減少網(wǎng)絡(luò)請求、節(jié)約計算資源、減少高負(fù)載數(shù)據(jù)源訪問等優(yōu)勢,進(jìn)而提高應(yīng)用程序的響應(yīng)速度和吞吐量。常見的本地緩存中間件有:Caffeine、Guava Cache、Ehcache。當(dāng)然你也可以在使用類似Map容器,在應(yīng)用程序中構(gòu)建自己的緩存結(jié)構(gòu)。 分布式緩存相比本地緩存的優(yōu)勢是可以保證數(shù)據(jù)一致性、只保留一份數(shù)據(jù),減少數(shù)據(jù)冗余、可以實現(xiàn)數(shù)據(jù)分片,實現(xiàn)大容量數(shù)據(jù)的存儲。常見的分布式緩存有:Redis、Memcached。
實現(xiàn)一個簡單的LRU本地緩存示例如下:
/**
* Least recently used 內(nèi)存緩存過期策略:最近最少使用
* Title: 帶容量的<b>線程不安全的</b>最近訪問排序的Hashmap
* Description: 最后訪問的元素在最后面。<br>
* 如果要線程安全,請使用<pre>Collections.synchronizedMap(new LRUHashMap(123));</pre> <br>
*
* @author: liuhuiqing
* @date: 20123/4/27
*/
public class LRUHashMap<K, V> extends LinkedHashMap<K, V> {
/**
* The Size.
*/
private final int maxSize;
/**
* 初始化一個最大值, 按訪問順序排序
*
* @param maxSize the max size
*/
public LRUHashMap(int maxSize) {
//0.75是默認(rèn)值,true表示按訪問順序排序
super(maxSize, 0.75f, true);
this.maxSize = maxSize;
}
/**
* 初始化一個最大值, 按指定順序排序
*
* @param maxSize 最大值
* @param accessOrder true表示按訪問順序排序,false為插入順序
*/
public LRUHashMap(int maxSize, boolean accessOrder) {
//0.75是默認(rèn)值,true表示按訪問順序排序,false為插入順序
super(maxSize, 0.75f, accessOrder);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return super.size() > maxSize;
}
}3.2 異步
異步可以提高程序的性能和響應(yīng)能力,使其能更高效地處理大規(guī)模數(shù)據(jù)或并發(fā)請求。其底層原理涉及到操作系統(tǒng)的多線程、事件循環(huán)、任務(wù)隊列以及回調(diào)函數(shù)等關(guān)鍵技術(shù),除此之外,異步的思想在應(yīng)用架構(gòu)設(shè)計方面也有廣泛的應(yīng)用。常規(guī)的多線程,消息隊列,響應(yīng)式編程等異步處理方案這里就不再展開介紹了,這里介紹兩個大家可能容易忽視但實用技能:非阻塞IO和 協(xié)程。
非阻塞IO
Java Servlet 3.0規(guī)范中引入了異步Servlet的概念,可以幫助開發(fā)者提高應(yīng)用程序的性能和并發(fā)處理能力,其原理是非阻塞IO使用單線程同時處理多個請求,避免了線程切換和阻塞的開銷,特別是在讀取大文件或者進(jìn)行復(fù)雜耗時計算場景時,可以避免阻塞其他請求的處理。Spring MVC框架中也提供了相應(yīng)的異步處理方案。
?使用Callable方式實現(xiàn)異步處理
@GetMapping("/async/callable")
public WebAsyncTask<String> asyncCallable() {
Callable<String> callable = () -> {
// 執(zhí)行異步操作
return "異步任務(wù)已完成";
};
return new WebAsyncTask<>(10000, callable);
}?使用DeferredResult方式實現(xiàn)異步處理
@GetMapping("/async/deferredresult")
public DeferredResult<String> asyncDeferredResult() {
DeferredResult<String> deferredResult = new DeferredResult<>(10000L);
// 異步處理完成后設(shè)置結(jié)果
deferredResult.setResult("DeferredResult異步任務(wù)已完成");
return deferredResult;
}協(xié)程
我們知道線程的創(chuàng)建、銷毀都十分消耗系統(tǒng)資源,所以有了線程池,但這還不夠,因為線程的數(shù)量是有限的(千級別),線程會阻塞操作系統(tǒng)線程,無法盡可能的提高吞吐量。因為使用線程的成本很高,所以才會有了虛擬線程,它是用戶態(tài)線程,成本是相當(dāng)?shù)土模{(diào)度也完全由用戶進(jìn)行控制(JDK 中的調(diào)度器),它同樣可以進(jìn)行阻塞,但不用阻塞操作系統(tǒng)線程,充分提高了硬件利用率,高并發(fā)也上了一個量級。
很長一段時間,協(xié)程概念并非作為JVM內(nèi)置的功能,而是通過第三方庫或框架實現(xiàn)的。目前比較常用的協(xié)程實現(xiàn)庫有Quasar、Kilim等。但在Java19版本中,引入了虛擬線程(Virtual Threads )的支持(處于Preview階段)。
虛擬線程是java.lang.Thread的一個實現(xiàn),可以使用java.lang.Thread.Builder接口創(chuàng)建
Thread thread = Thread.ofVirtual()
.name("Virtual Threads")
.unstarted(runnable);也可以通過一個線程工廠類進(jìn)行創(chuàng)建:
ThreadFactory factory = Thread.ofVirtual().factory();虛擬線程運(yùn)行的載體必須是線程,同一個線程中可以運(yùn)行多個虛擬線程實例。
3.3 并行
并行處理的思想在大數(shù)據(jù),多任務(wù),流水線處理,模型訓(xùn)練等各個方面發(fā)揮著重要作用,包括前面介紹的異步(多線程,協(xié)程,消息等),也是建立在并行的基礎(chǔ)上。在應(yīng)用層面,典型的場景有:
- 分布式計算框架中的MapReduce就是采用一種分而治之的思想設(shè)計出來的,將復(fù)雜或計算量大的任務(wù),切分成一個個小的任務(wù),小任務(wù)分別在不同的線程或服務(wù)器上并行的執(zhí)行,最終再匯總每個小任務(wù)的結(jié)果。
- 邊緣計算(Edge Computing)是一種分布式計算范式,它將計算、存儲和網(wǎng)絡(luò)服務(wù)的部分功能從云數(shù)據(jù)中心延伸至離數(shù)據(jù)源更近的地方,即網(wǎng)絡(luò)的邊緣。這種計算方式能夠?qū)崿F(xiàn)低延遲、節(jié)省帶寬、提高數(shù)據(jù)安全性以及實時處理與分析等優(yōu)勢。
在代碼實現(xiàn)方面,做好解耦設(shè)計,接下來就可以進(jìn)行并行設(shè)計了,比如:
- 多個請求可以通過多線程并行處理,每個請求的不同處理階段;
- 如查詢階段,可以采用協(xié)程并行執(zhí)行;
- 存儲階段,可以采用消息訂閱發(fā)布的方式進(jìn)行處理;
- 監(jiān)控統(tǒng)計階段,就可以采用NIO異步的方式進(jìn)行指標(biāo)數(shù)據(jù)文件的寫入;
- 請求/響應(yīng)采用非阻塞IO模式;
3.4 池化
池化就是初始預(yù)設(shè)資源,降低每次獲取資源的消耗,如創(chuàng)建線程的開銷,獲取遠(yuǎn)程連接的開銷等。典型的場景就是線程池,數(shù)據(jù)庫連接池,業(yè)務(wù)處理結(jié)果緩存池等。
以數(shù)據(jù)庫連接池為例,其本質(zhì)是一個 socket 的連接。為每個請求打開和維護(hù)數(shù)據(jù)庫連接,尤其是動態(tài)數(shù)據(jù)庫驅(qū)動的應(yīng)用程序的請求,既昂貴又浪費(fèi)資源。為什么這么說呢?以MySQL數(shù)據(jù)庫建立連接(TCP協(xié)議)為例,建立連接總共分三步:
- 建立TCP連接,通過三次握手實現(xiàn);
- 服務(wù)器發(fā)送給客戶端「握手信息」 ,客戶端響應(yīng)該握手消息;
- 客戶端「發(fā)送認(rèn)證包」 ,用于用戶驗證,驗證成功后,服務(wù)器返回OK響應(yīng),之后開始執(zhí)行命令;
簡單粗略統(tǒng)計,完成一次數(shù)據(jù)庫連接,客戶端和服務(wù)器之間需要至少往返7次,總計平均耗時大約在200ms左右,這對于很對C端服務(wù)來說,幾乎是不能接受的。
落實到代碼編寫層面,也可以借助這一思想來優(yōu)化我們的程序執(zhí)行性能。
- 公用的數(shù)據(jù)可以全局只定義一份,比如使用枚舉,static修飾的容器對象等;
- 根據(jù)實際情況,提前設(shè)置List,Map等容器對象的初始化容量大小,防止后面的擴(kuò)容,對性能的影響;
- 亨元設(shè)計模式的應(yīng)用等;
3.5 預(yù)處理
一般需要池化的內(nèi)容,都是需要預(yù)處理的,比如為了保證服務(wù)的穩(wěn)定性,線程池和數(shù)據(jù)庫連接池等需要池化的內(nèi)容在JVM容器啟動時,處理真正請求之前,對這些池化內(nèi)容進(jìn)行預(yù)處理,等到真正的業(yè)務(wù)處理請求過來時,可以正常的快速處理。除此之外,預(yù)處理還可以體現(xiàn)在系統(tǒng)架構(gòu)層面。
- 為了提高響應(yīng)性能,將部分業(yè)務(wù)數(shù)據(jù)提前預(yù)加載到內(nèi)存中;
- 為了減輕CPU壓力,將計算邏輯提前執(zhí)行,直接將計算后的結(jié)果數(shù)據(jù)保存下來,直接供調(diào)用方使用;
- 為了降低網(wǎng)絡(luò)帶寬成本,將傳輸數(shù)據(jù)通過壓縮算法進(jìn)行壓縮處理,到了目標(biāo)服務(wù),在進(jìn)行解壓,獲得原始數(shù)據(jù);
- Myibatis為了提高SQL語句的安全性和執(zhí)行效率,也引入了預(yù)處理的概念;
四 總結(jié)
性能優(yōu)化是程序開發(fā)過程中繞不過去一個課題,本文聚焦代碼和設(shè)計兩個方面,從CPU硬件到JVM容器,從緩存設(shè)計到數(shù)據(jù)預(yù)處理,全面的展現(xiàn)了性能優(yōu)化的實施方向和落地細(xì)節(jié)。闡述的過程沒有追求各個方向的面面俱到,但都給到了一些場景化案例,來輔助理解和思考,起到拋磚引玉的效果。
作者:京東零售 劉慧卿
內(nèi)容來源:京東云開發(fā)者社區(qū)

















