【大數(shù)據(jù)】Presto(Trino)配置參數(shù)以及 SQL語法
一、概述
Trino (前身為PrestoSQL)是一款高性能,分布式的SQL查詢引擎,可以用于查詢各種類型的數(shù)據(jù)存儲,包括Hive、Mysql、Elasticsearch、Kafka、PostgreSQL等。在使用Trino時,可以通過一些參數(shù)來控制查詢的行為,例如:
- coordinator節(jié)點和worker節(jié)點的數(shù)量: 這兩個參數(shù)控制了Trino集群中管理查詢的節(jié)點數(shù)量,它們的配合調(diào)整可以影響整個集群的查詢效率。
- memory和cpu的分配: 這些參數(shù)控制了Trino在查詢和計算時使用的內(nèi)存和CPU數(shù)量。可以根據(jù)集群的實際硬件情況和查詢工作負(fù)載來靈活配置。
- join分布式:控制join關(guān)鍵字的使用。join分布式是一種優(yōu)化策略,在大規(guī)模數(shù)據(jù)集上運行的查詢中處理join操作非常簡單。
- 指定數(shù)據(jù)源:可以使用catalog和schema(數(shù)據(jù)庫)兩個關(guān)鍵字指定Trino查詢的數(shù)據(jù)源。
- 分區(qū)和bucket表的查詢: 分區(qū)表是對表進(jìn)行分區(qū)和拆分的一種方式,通過分區(qū)表查詢只需掃描相應(yīng)分區(qū),提高了查詢效率。bucket表是一種將數(shù)據(jù)分散在多個桶中的表格,它們可以通過桶數(shù)對數(shù)據(jù)進(jìn)行分片,并行化查詢操作,從而提高查詢性能。
Trino官方文檔:https://trino.io/docs/current/
關(guān)于更多的Presto介紹可以參考我這篇文章:大數(shù)據(jù)Hadoop之——基于內(nèi)存型SQL查詢引擎Presto(Presto-Trino環(huán)境部署)
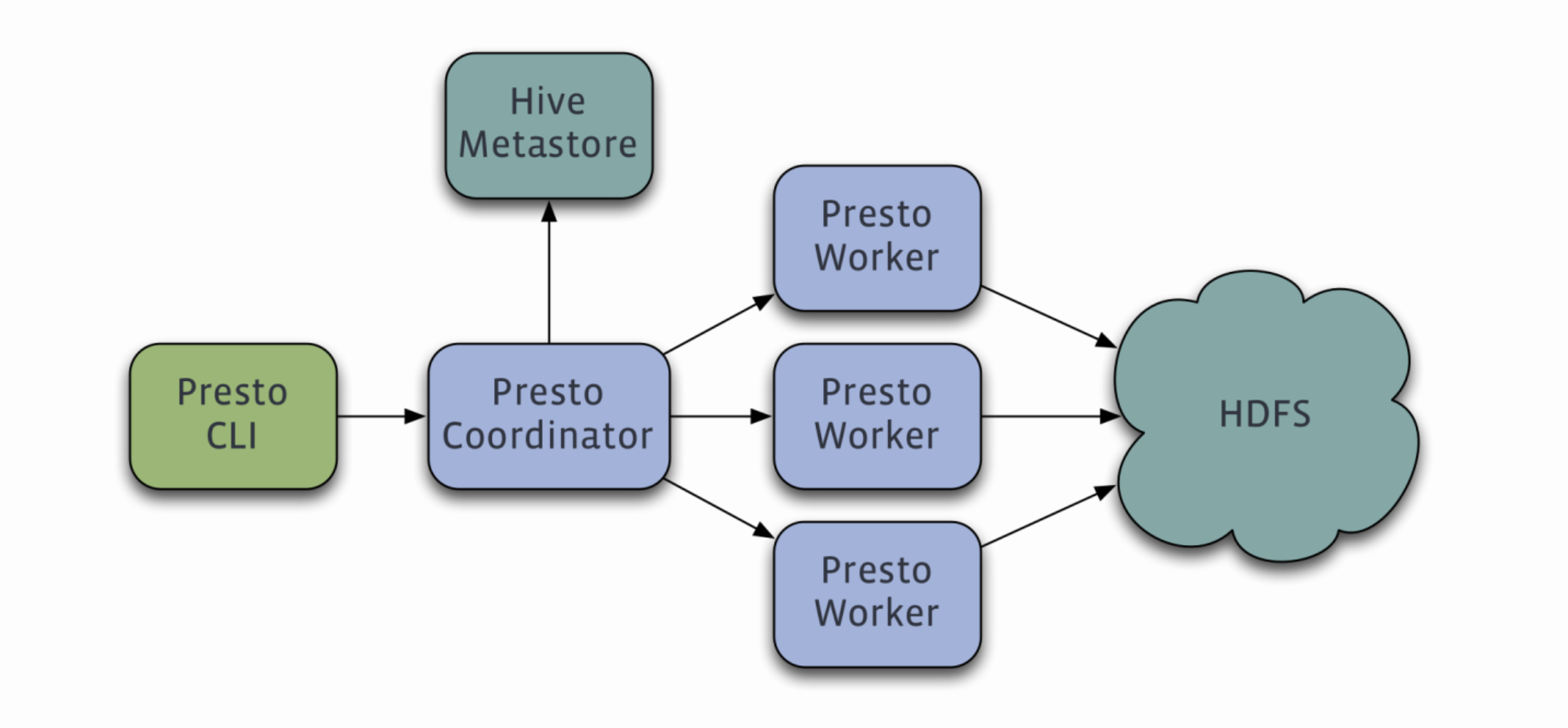
二、Trino coordinator 和 worker 節(jié)點作用
1)Trino coordinator 節(jié)點作用
在Trino中,coordinator節(jié)點是整個集群的管理節(jié)點,它的作用包括:
- 查詢協(xié)調(diào):coordinator節(jié)點負(fù)責(zé)協(xié)調(diào)所有查詢操作,如解析sql語句、生成查詢計劃、調(diào)度和分配查詢?nèi)蝿?wù)等。它會根據(jù)查詢的復(fù)雜度和數(shù)據(jù)源的規(guī)模來判斷查詢是否需要被分割和并行執(zhí)行,以提高查詢效率和資源利用率。
- 資源管理:coordinator節(jié)點負(fù)責(zé)管理整個集群的資源,如內(nèi)存、CPU等。它會根據(jù)每個查詢的資源需求和集群的可用資源情況來動態(tài)調(diào)整資源使用情況,以保證集群的穩(wěn)定性和性能。
- 節(jié)點管理:coordinator節(jié)點負(fù)責(zé)管理集群的所有worker節(jié)點,包括狀態(tài)更新、任務(wù)分配、心跳檢測等。它會監(jiān)測節(jié)點的可用性和狀態(tài),并根據(jù)集群負(fù)載情況來動態(tài)調(diào)整節(jié)點的任務(wù)分配和負(fù)載平衡策略,以保證整個集群的穩(wěn)定性和可用性。
- 集群監(jiān)控:coordinator節(jié)點負(fù)責(zé)監(jiān)控整個集群的運行狀況,包括各個節(jié)點的狀態(tài)、負(fù)載情況、查詢性能等。它會將這些信息進(jìn)行匯總和分析,并生成相應(yīng)的報告和指標(biāo),以便管理員進(jìn)行集群的優(yōu)化和調(diào)整。
- 系統(tǒng)管理:coordinator節(jié)點負(fù)責(zé)管理整個Trino系統(tǒng),包括配置文件管理、插件管理、安全管理等。它會根據(jù)管理員的設(shè)定和權(quán)限來進(jìn)行相應(yīng)的管理和控制,以保證整個系統(tǒng)的穩(wěn)定性和安全性。
因此,可以看出coordinator節(jié)點在Trino集群中起到了至關(guān)重要的作用,它是整個集群的大腦和控制中心。為了保證集群的性能和可用性,建議對coordinator節(jié)點進(jìn)行適當(dāng)?shù)呐渲煤凸芾恚詽M足查詢復(fù)雜度和數(shù)據(jù)量的需求。
2)Trino worker 節(jié)點作用
在Trino中,worker節(jié)點是集群中執(zhí)行任務(wù)的節(jié)點。它的作用包括:
- 任務(wù)執(zhí)行:worker節(jié)點負(fù)責(zé)執(zhí)行coordinator分配給它的任務(wù),如數(shù)據(jù)讀取、數(shù)據(jù)過濾、數(shù)據(jù)聚合等。它會將數(shù)據(jù)處理的結(jié)果返回給coordinator節(jié)點,以便進(jìn)行下一步的處理和計算。
- 數(shù)據(jù)存儲:worker節(jié)點負(fù)責(zé)存儲集群中的數(shù)據(jù),包括數(shù)據(jù)的分片、存儲和管理等。它會維護(hù)一個數(shù)據(jù)存儲倉庫,并根據(jù)查詢計劃和任務(wù)分配來讀取和處理數(shù)據(jù),以提高查詢效率和資源利用率。
- 資源管理:worker節(jié)點會根據(jù)集群的資源限制和任務(wù)優(yōu)先級,動態(tài)調(diào)整資源的分配和使用情況,以保證集群的穩(wěn)定性和性能。
- 網(wǎng)絡(luò)通信:worker節(jié)點負(fù)責(zé)與coordinator節(jié)點進(jìn)行通信,并根據(jù)分配的任務(wù)來讀取和處理數(shù)據(jù)。它需要保證和coordinator節(jié)點的通信暢通,并及時反饋處理結(jié)果。
因此,可以看出worker節(jié)點在Trino集群中扮演了至關(guān)重要的角色,它是整個集群的工作機(jī)器和數(shù)據(jù)存儲倉庫。為了保證集群的性能和可用性,建議對worker節(jié)點進(jìn)行適當(dāng)?shù)呐渲煤凸芾恚詽M足查詢和數(shù)據(jù)處理的需求。同時,建議用戶根據(jù)自己的業(yè)務(wù)需求和數(shù)據(jù)量來增加或降低worker節(jié)點的數(shù)量和配置,以達(dá)到最佳的資源利用率和查詢效率。
三、Trino 參數(shù)詳細(xì)講解
1)coordinator 節(jié)點配置
1、config.properties 配置文件
config.properties是Trino服務(wù)器的配置文件,它包含了Trino服務(wù)器的各種配置選項,如節(jié)點配置、查詢優(yōu)化器配置、內(nèi)存和CPU配置、集群安全配置等。下面是幾個常見的config.properties選項:
- coordinator=true/false:配置當(dāng)前節(jié)點是否為coordinator節(jié)點。
- node-scheduler.include-coordinator:是Trino協(xié)調(diào)節(jié)點(coordinator)的配置參數(shù)之一,用于控制調(diào)度器是否包括協(xié)調(diào)節(jié)點自身作為可用的執(zhí)行節(jié)點。默認(rèn)情況下,node-scheduler.include-coordinator的值為 true,即協(xié)調(diào)節(jié)點被視為可用的執(zhí)行節(jié)點。
- task.max-memory-per-node:該參數(shù)用于設(shè)置每個工作節(jié)點上單個任務(wù)(task)可使用的最大內(nèi)存量。它定義了每個任務(wù)在工作節(jié)點上可以使用的最大內(nèi)存量。單位可以是字節(jié)(B)、千字節(jié)(KB)、兆字節(jié)(MB)、千兆字節(jié)(GB)或太字節(jié)(TB)。
- query.max-memory:這個參數(shù)設(shè)置了每個查詢可使用的最大內(nèi)存量。它控制著整個查詢在所有工作節(jié)點上可以使用的總內(nèi)存量。當(dāng)查詢需要的內(nèi)存超過這個限制時,Trino將拋出內(nèi)存不足的錯誤。
- query.max-memory-per-node:此參數(shù)定義了每個工作節(jié)點可使用的最大內(nèi)存量。它限制了單個查詢在單個工作節(jié)點上可以使用的最大內(nèi)存量。當(dāng)單個任務(wù)需要的內(nèi)存超過此限制時,Trino將啟動其他任務(wù)以利用其他工作節(jié)點上的內(nèi)存。
- query.max-total-memory-per-node: 該參數(shù)限制了每個工作節(jié)點可使用的最大總內(nèi)存量。它控制著所有正在運行的查詢在單個工作節(jié)點上可以使用的總內(nèi)存量。當(dāng)工作節(jié)點上的查詢總內(nèi)存使用超過此限制時,Trino將拒絕新的查詢請求。
- memory.heap-headroom-per-node:用來配置Trino worker節(jié)點的Java堆空間余量的選項。它指定了每個worker節(jié)點JVM堆中保留的額外內(nèi)存空間的大小,用于處理臨時內(nèi)存和查詢的內(nèi)存需求。默認(rèn)情況下,memory.heap-headroom-per-node的值是0。這意味著Trino使用默認(rèn)的Java Heap內(nèi)存分配策略來處理內(nèi)存,并盡可能避免OOM(內(nèi)存不足)錯誤。
- query.max-run-time:配置每個查詢的最大運行時間,防止查詢太復(fù)雜導(dǎo)致資源耗盡。
- http-server.http.port=8080:配置http服務(wù)器的端口號。
- query.results.max-age=1m:配置查詢結(jié)果在內(nèi)存中的最大保存時間,防止浪費內(nèi)存。
- query.priority=1:配置查詢的優(yōu)先級,以便coordinator節(jié)點調(diào)度任務(wù)。
- exchange.client-threads=2:配置worker節(jié)點與coordinator節(jié)點之間數(shù)據(jù)交換的線程數(shù)量,以提高網(wǎng)絡(luò)通信效率。
- plugin.<plugin-name>.<option>=<value>:配置插件選項和值,以擴(kuò)展Trino的功能和支持新的數(shù)據(jù)源。
因此,config.properties文件對于Trino服務(wù)器的性能和功能都具有重要的作用,建議管理員和用戶仔細(xì)查閱和配置。同時,可以根據(jù)業(yè)務(wù)需求和系統(tǒng)資源情況來適當(dāng)調(diào)整其中的選項,以達(dá)到最佳的性能和效率。
示例配置如下:
###################################
## 協(xié)調(diào)節(jié)點配置
###################################
coordinator=true
###################################
## HTTP服務(wù)配置
###################################
http-server.http.port=8080
###################################
## 內(nèi)存配置
###################################
query.max-memory=5GB
query.max-memory-per-node=2GB
query.max-total-memory-per-node=10GB
###################################
## 發(fā)現(xiàn)服務(wù)配置
###################################
discovery-server.enabled=true
discovery.uri=http://localhost:8080
###################################
## 插件配置
###################################
plugin.myplugin.property=value
###################################
## 其他配置
###################################
# 身份驗證配置
http-server.authentication.type=PASSWORD
http-server.authentication.password-user-mapping-file=etc/password-authenticator.properties
# 授權(quán)配置
access-control.name=my-access-control
access-control.config-file=etc/access-control.properties
# 元數(shù)據(jù)存儲配置
metadata.store.type=jdbc
metadata.store.jdbc-url=jdbc:postgresql://localhost:5432/trino_metadata
metadata.store.username=trino
metadata.store.password=secret
# 集群配置
discovery-server.enabled=true
discovery.uri=http://localhost:8080
node-scheduler.include-coordinator=true
# 指標(biāo)和監(jiān)控配置
metrics.enabled=true
metrics.reporting-interval=1m
metrics.store.type=prometheus
metrics.store.reporters=prometheus
metrics.store.prometheus.uri=http://localhost:9090/metrics2、jvm.config 配置文件
Trino協(xié)調(diào)節(jié)點(coordinator)的JVM配置文件是 jvm.config。它位于Trino安裝目錄的 etc 文件夾中。
jvm.config 文件用于配置協(xié)調(diào)節(jié)點的Java虛擬機(jī)(JVM)參數(shù),以控制內(nèi)存、垃圾回收、線程等方面的行為。
一些常用的JVM參數(shù)及其含義:
-server:啟用服務(wù)器模式,優(yōu)化性能。-Xmx8G:設(shè)置Java堆的最大內(nèi)存為8GB。最好是配置小于32G。-XX:+UseG1GC:啟用G1垃圾收集器。-XX:InitialRAMPercentage:是一個Java虛擬機(jī)(JVM)參數(shù),用于設(shè)置初始堆內(nèi)存的百分比。它指定了初始堆內(nèi)存大小相對于可用系統(tǒng)內(nèi)存的比例。默認(rèn)值為64,表示JVM將會使用可用系統(tǒng)內(nèi)存的64%。
`-XX:InitialRAMPercentage` 該參數(shù)通常與`-Xmx`(最大堆內(nèi)存)參數(shù)一起使用,以確保在應(yīng)用程序啟動時分配足夠的初始堆內(nèi)存。
-XX:InitialRAMPercentage 和 -Xmx 都是用于配置Java虛擬機(jī)(JVM)的堆內(nèi)存參數(shù)。下面是一個示例配置和相應(yīng)的換算示例:
-XX:InitialRAMPercentage=25
-Xmx8G
假設(shè)可用系統(tǒng)內(nèi)存為16GB(Gigabytes),我們將根據(jù)配置計算初始堆內(nèi)存和最大堆內(nèi)存的大小。
首先,我們使用 -XX:InitialRAMPercentage 參數(shù)來計算初始堆內(nèi)存的大小:
初始堆內(nèi)存大小 = 可用系統(tǒng)內(nèi)存 * (InitialRAMPercentage / 100)
初始堆內(nèi)存大小 = 16GB * (25 / 100) = 4GB
接下來,我們使用 -Xmx 參數(shù)來指定最大堆內(nèi)存的大小,這里設(shè)置為8GB。
因此,根據(jù)以上配置和換算示例,初始堆內(nèi)存將為4GB,最大堆內(nèi)存將為8GB。
請注意,確保根據(jù)實際系統(tǒng)內(nèi)存大小和應(yīng)用程序的內(nèi)存需求進(jìn)行適當(dāng)?shù)恼{(diào)整。對于初始堆內(nèi)存和最大堆內(nèi)存,建議根據(jù)應(yīng)用程序的性能需求進(jìn)行合理配置,以確保充分利用系統(tǒng)資源并避免內(nèi)存不足或浪費的情況。
此外,-XX:InitialRAMPercentage 和 -Xmx 參數(shù)的可用性和行為可能因JVM的版本和廠商而有所不同。請參考所使用JVM的文檔以獲取準(zhǔn)確的信息。- -XX:MaxRAMPercentage:是一個JVM參數(shù),用于指定JVM使用系統(tǒng)內(nèi)存的最大百分比。這個參數(shù)可以被用于Trino和其他Java應(yīng)用程序。它的默認(rèn)值為64,表示JVM將最大使用可用系統(tǒng)內(nèi)存的64%。例如,如果系統(tǒng)有16GB內(nèi)存可用,則默認(rèn)情況下JVM將使用10.24GB內(nèi)存。
- -XX:MaxRAMPercentage:是一個JVM參數(shù),用于控制G1垃圾收集器中堆區(qū)域的大小。G1垃圾收集器是Java SE 9及更高版本中使用的一種高效的垃圾收集器,可以用于Trino和其他Java應(yīng)用程序。堆區(qū)域是G1垃圾收集器中內(nèi)存分配的最小單位。這個參數(shù)的默認(rèn)值是堆大小除以2048,最小值是1MB,最大值是32MB。這意味著如果堆大小是8GB,則每個堆區(qū)域的默認(rèn)大小是4MB。
- -XX:+ExplicitGCInvokesConcurrent:是一個JVM參數(shù),用于啟用顯式垃圾回收調(diào)用時并發(fā)處理的垃圾收集器。在此模式下,會在發(fā)出垃圾回收調(diào)用時,同時運行一個并發(fā)垃圾收集器,以優(yōu)化程序的性能。
- -XX:+ExitOnOutOfMemoryError:是一個JVM參數(shù),用于在發(fā)生OutOfMemoryError錯誤時自動退出JVM。OutOfMemoryError指的是Java程序中無法分配足夠的內(nèi)存的情況。默認(rèn)情況下,JVM在發(fā)生OutOfMemoryError時不會終止。如果您使用這個參數(shù),則JVM將在發(fā)生OutOfMemoryError時立即退出,從而防止程序繼續(xù)運行并進(jìn)一步損壞數(shù)據(jù)或系統(tǒng)。
- -XX:-OmitStackTraceInFastThrow:是一個JVM參數(shù),用于在Java程序中啟用錯誤堆棧跟蹤提示。通常,當(dāng)Java程序中發(fā)生異常或錯誤時,系統(tǒng)會生成一個堆棧跟蹤提示來告訴您程序執(zhí)行過程中出現(xiàn)了哪些錯誤。默認(rèn)情況下,當(dāng)程序中的代碼中發(fā)生快速失敗時,JVM會省略異常堆棧跟蹤提示,以提高程序的性能。這意味著,當(dāng)程序出現(xiàn)錯誤時,您可能無法輕松地DEBUG并查找到底發(fā)生了什么錯誤。
- -XX:ReservedCodeCacheSize:是一個JVM參數(shù),用于設(shè)置JIT編譯器代碼緩存的最大大小。默認(rèn)情況下,JIT編譯器會將編譯過的代碼存放在代碼緩存中,以加速程序的后續(xù)執(zhí)行。然而,如果緩存大小不夠,JIT編譯器可能會不得不丟棄部分編譯過的代碼,這會導(dǎo)致程序性能下降。
- -XX:PerMethodRecompilationCutoff:是一個Java虛擬機(jī)(JVM)的參數(shù),用于設(shè)置方法重新編譯的閾值。它指定了一個方法在執(zhí)行多少次之后需要重新編譯。該參數(shù)的值通常是一個正整數(shù),默認(rèn)值為15000。
- -XX:PerBytecodeRecompilationCutoff:是一個Java虛擬機(jī)(JVM)的參數(shù),用于設(shè)置字節(jié)碼重新編譯的閾值。它指定了一個方法的字節(jié)碼在執(zhí)行多少次之后需要重新編譯。該參數(shù)的值通常是一個正整數(shù),默認(rèn)值為10000。
- -Djdk.attach.allowAttachSelf 是一個Java系統(tǒng)屬性,用于允許Java進(jìn)程自己附加到自己。該屬性通常用于啟用Java程序自我監(jiān)視和調(diào)試的功能。默認(rèn)情況下,此屬性被設(shè)置為"false",禁止Java進(jìn)程附加到自身。要允許Java進(jìn)程附加到自身,需要將該屬性設(shè)置為"true"。
- -Djdk.nio.maxCachedBufferSize:是一個Java系統(tǒng)屬性,用于設(shè)置NIO緩沖區(qū)的最大緩存大小。NIO(New I/O)是Java提供的一種高性能I/O操作方式。該屬性指定了NIO緩沖區(qū)在緩存中的最大大小。默認(rèn)情況下,該屬性未設(shè)置,使用JVM內(nèi)部的默認(rèn)值。可以通過設(shè)置該屬性為一個正整數(shù)值來限制NIO緩沖區(qū)的最大緩存大小,以控制內(nèi)存的使用。默認(rèn)值取決于 Java 運行時環(huán)境的版本。在 Java 8 及之前的版本中,默認(rèn)值為 -1,表示不限制 NIO 緩沖區(qū)的最大緩存大小。而在 Java 9 及以后的版本中,默認(rèn)值為 0,表示禁用 NIO 緩沖區(qū)的緩存,即不進(jìn)行緩存。
- -XX:+UnlockDiagnosticVMOptions:是一個 Java 虛擬機(jī)(JVM)選項,用于解鎖診斷性 VM 選項。默認(rèn)情況下,JVM 中的某些診斷功能是被禁用的,通過使用該選項,可以解鎖并啟用這些診斷功能。這個選項通常用于開發(fā)和調(diào)試目的。
- -XX:+UseAESCTRIntrinsics:是一個 Java 虛擬機(jī)(JVM)選項,用于啟用AES-CTR加密算法的硬件優(yōu)化。當(dāng)該選項被啟用時,JVM會嘗試使用CPU的AES指令集來執(zhí)行AES-CTR操作,以提高加密和解密的性能。
- -XX:-G1UsePreventiveGC:是一個 Java 虛擬機(jī)(JVM)選項,用于禁用 G1 垃圾收集器的預(yù)防性垃圾回收(Preventive GC)機(jī)制。預(yù)防性垃圾回收是 G1 垃圾收集器的一項特性,旨在在堆內(nèi)存使用率較低時主動觸發(fā)垃圾回收,以避免堆內(nèi)存達(dá)到極限。
這個選項通常用于開發(fā)和以下是一個示例的 jvm.config 配置文件:
-server
-Xmx2G
-XX:InitialRAMPercentage=20
-XX:MaxRAMPercentage=80
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
# Disable Preventive GC for performance reasons (JDK-8293861)
-XX:-G1UsePreventiveGC請注意,具體的配置取決于您的硬件資源、工作負(fù)載和性能需求。您可以根據(jù)您的具體情況來調(diào)整和優(yōu)化JVM參數(shù)。
3、log.properties 配置文件
# 設(shè)置日志級別,有四個級別:DEBUG, INFO, WARN and ERROR
io.trino=INFO4、node.properties 配置文件
# 環(huán)境的名字。集群中所有的Trino節(jié)點必須具有相同的環(huán)境名稱。
node.environment=production
# 此Trino安裝的唯一標(biāo)識符。這對于每個節(jié)點都必須是唯一的,不填則是隨機(jī)的。
node.id=trino-coordinator
# 數(shù)據(jù)目錄的位置(文件系統(tǒng)路徑)。Trino在這里存儲日志和其他數(shù)據(jù)。
node.data-dir=/opt/apache/trino/data2)worker 節(jié)點配置
1、config.properties 配置文件
以下是一個Trino工作節(jié)點的配置文件示例config.properties,用于配置工作節(jié)點的基本設(shè)置,包括通信、內(nèi)存、線程池以及插件等。
coordinator=false
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=10GB
query.max-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://<your-coordinator-node-hostname>:8080
exchange.http-client.keep-alive-interval=5m
exchange.http-client.idle-timeout=10m
task.concurrency=16
task.writer-count=4
jvm.configured-initial-ram-percent=80
memory.heap-headroom-per-node=1GB以下是示例配置文件中的各項設(shè)置的含義:
- coordinator=false:設(shè)置當(dāng)前節(jié)點為工作節(jié)點而非協(xié)調(diào)器節(jié)點。
- node-scheduler.include-coordinator=false:用于決定協(xié)調(diào)器節(jié)點是否應(yīng)該納入查詢計算資源的調(diào)度范圍。當(dāng)該參數(shù)設(shè)置為true時,協(xié)調(diào)器節(jié)點可以作為一個普通的計算節(jié)點來執(zhí)行查詢,從而幫助處理計算負(fù)載。當(dāng)設(shè)置false,這將確保協(xié)調(diào)器節(jié)點不會執(zhí)行查詢,從而避免了性能瓶頸問題,一般是設(shè)置false,禁用協(xié)調(diào)節(jié)點又充當(dāng)worker節(jié)點使用。
- http-server.http.port=8080:HTTP服務(wù)器監(jiān)聽的端口號,用于接收REST API請求。
- query.max-memory=10GB:單個查詢可用的最大內(nèi)存數(shù)量。
- query.max-memory-per-node=2GB:單個工作節(jié)點可用于執(zhí)行查詢的最大內(nèi)存數(shù)量。
- discovery-server.enabled=true:啟用節(jié)點發(fā)現(xiàn)服務(wù)器,用于協(xié)調(diào) Trino 群集中的各個節(jié)點。
- discovery.uri=http://<your-coordinator-node-hostname>:8080:發(fā)現(xiàn)服務(wù)器節(jié)點的URL。
- exchange.http-client.keep-alive-interval=5m:控制通信時,HTTP客戶端保持活動狀態(tài)的時間。
- exchange.http-client.idle-timeout=10m:當(dāng)HTTP客戶端處于空閑狀態(tài)時,客戶端關(guān)閉連接之前保持空閑的時間量。
- task.concurrency=16:在工作節(jié)點上同時執(zhí)行的最大任務(wù)數(shù)。
- task.writer-count=4:在工作節(jié)點上同時寫入數(shù)據(jù)的最大任務(wù)數(shù)。
- jvm.configured-initial-ram-percent=80:JVM初始堆大小作為RAM百分比的設(shè)置。
- memory.heap-headroom-per-node=1GB:為Trino查詢準(zhǔn)備的每個節(jié)點之外的堆剩余空間。
請注意,這只是一個示例配置,您可以根據(jù)您自己的需求進(jìn)行修改。有關(guān)更多配置參數(shù)和詳細(xì)信息,請參閱官方文檔:https://trino.io/docs/current/installation/deployment.html。
2、jvm.config 配置文件
下面是一個Trino工作節(jié)點的jvm.config示例配置文件,它包含了一些常用的JVM參數(shù),可以幫助你優(yōu)化Trino的性能和內(nèi)存利用率:
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=16M
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %p
-XX:ErrorFile=/var/log/trino/hs_err_pid%p.log
-Djava.library.path=/usr/lib/hadoop/lib/native
-Djdk.attach.allowAttachSelf=true這里是每個參數(shù)的含義:
- -server: 使用JVM的服務(wù)模式,通常是用于長時間運行的應(yīng)用程序。
- -Xmx16G: 設(shè)置JVM可用的最大堆內(nèi)存為16GB。
- -XX:+UseG1GC: 啟用G1垃圾回收器。
- -XX:G1HeapRegionSize=16M: 設(shè)置G1 GC的堆區(qū)域大小為16MB。
- -XX:+HeapDumpOnOutOfMemoryError: 在內(nèi)存溢出時生成堆內(nèi)存轉(zhuǎn)儲文件。
- -XX:OnOutOfMemoryError=kill -9 %p: 在內(nèi)存溢出時強(qiáng)制殺死Trino進(jìn)程。
- -XX:ErrorFile=/var/log/trino/hs_err_pid%p.log: 將JVM錯誤信息輸出到指定的錯誤文件中。
- -XX:+ExplicitGCInvokesConcurrent: 啟用顯式垃圾回收操作。
- -Djava.library.path=/usr/lib/hadoop/lib/native: 指定Hadoop本機(jī)庫的路徑。
- -Djdk.attach.allowAttachSelf=true: 允許JVM附加到它自己的進(jìn)程,有助于診斷和調(diào)試。
這只是一個基礎(chǔ)配置文件,用戶可以根據(jù)各自的需求和系統(tǒng)資源狀況進(jìn)行微調(diào)。同時需要注意的是,在配置JVM參數(shù)時,一定要謹(jǐn)慎,了解每個參數(shù)的含義和影響,并進(jìn)行適當(dāng)?shù)臏y試和調(diào)優(yōu),以確保系統(tǒng)的穩(wěn)定性和性能。
3、log.properties 配置文件
# 設(shè)置日志級別,有四個級別:DEBUG, INFO, WARN and ERROR
io.trino=INFO4、node.properties 配置文件
# 環(huán)境的名字。集群中所有的Trino節(jié)點必須具有相同的環(huán)境名稱。
node.environment=production
# 此Trino安裝的唯一標(biāo)識符。這對于每個節(jié)點都必須是唯一的,不填則是隨機(jī)的。
node.id=trino-worker-1
# 數(shù)據(jù)目錄的位置(文件系統(tǒng)路徑)。Trino在這里存儲日志和其他數(shù)據(jù)。
node.data-dir=/opt/apache/trino/data四、環(huán)境準(zhǔn)備
如已經(jīng)有環(huán)境了,可以忽略,如想快熟部署Presto(Trino)環(huán)境可參考我這篇文章:【大數(shù)據(jù)】通過 docker-compose 快速部署 Presto(Trino)保姆級教程
docker exec -it trino-coordinator bash
# --catalog:數(shù)據(jù)源 --schema:數(shù)據(jù)庫
${TRINO_HOME}/bin/trino-cli --server http://trino-coordinator:8080 --user=hadoop五、Trino 中的 數(shù)據(jù)源(catalog)
在Trino中,catalog是一種用于管理數(shù)據(jù)連接和數(shù)據(jù)源的概念。一個catalog可以代表一個數(shù)據(jù)庫、一個hive實例、或者其他支持的數(shù)據(jù)源。Trino可以通過啟用不同的catalog來連接和查詢不同的數(shù)據(jù)源,這樣你就可以使用一個Trino集群查詢多個數(shù)據(jù)源中的數(shù)據(jù),而不需要使用不同的工具和語言進(jìn)行查詢。
Trino中支持的catalog包括:
系統(tǒng)catalog:包括system、memory、information_schema和metadata,用于管理和查詢Trino系統(tǒng)和運行時信息。
- Hive catalog:用于連接處理Hive數(shù)據(jù)。
- Mysql catalog:用于連接在Trino中,catalog是一種用于管理數(shù)據(jù)連接和數(shù)據(jù)源的概念。一個catalog可以代表一個數(shù)據(jù)庫、一個hive實例、或者其他支持的數(shù)據(jù)源。Trino可以通過啟用不同的catalog來連接和查詢不同的數(shù)據(jù)源,這樣你就可以使用一個Trino集群查詢多個數(shù)據(jù)源中的數(shù)據(jù),而不需要使用不同的工具和語言進(jìn)行查詢。
Trino中支持的catalog包括:
- 系統(tǒng)catalog:包括system、memory、information_schema和metadata,用于管理和查詢Trino系統(tǒng)和運行時信息。
- Mysql catalog:用于連接Mysql數(shù)據(jù)源。
- Hive catalog:用于連接處理Hive數(shù)據(jù)。
- Kafka catalog:用于連接處理Kafka消息數(shù)據(jù)。
- Elasticsearch catalog:用于連接處理Elasticsearch數(shù)據(jù)。
- Jdbc catalog:用于連接處理關(guān)系型數(shù)據(jù)庫。
- Cassandra catalog:用于連接處理Cassandra NoSQL數(shù)據(jù)庫。
除了以上常用的catalog,Trino還支持許多其他的catalog。你可以通過配置文件或者命令行參數(shù)來啟用或禁用不同的catalog,以便連接和查詢不同的數(shù)據(jù)源。當(dāng)啟用一個catalog時,需要為它配置連接參數(shù)和身份憑證等信息。Trino中的catalog提供了一種簡便而靈活的方式來管理連接和查詢多種數(shù)據(jù)源,使得數(shù)據(jù)查詢和集成變得更加高效和便利。
官方文檔:https://trino.io/docs/current/connector.html
六、Trino 數(shù)據(jù)類型
官方文檔:https://trino.io/docs/current/language/types.html
1)基礎(chǔ)數(shù)據(jù)類型
類型 | 描述 | 示例 |
boolean | true或false | true |
tinyint | 8位有符號整數(shù),最小值? 2^7 ,最大值 2^7-1 | 42 |
smallint | 16位有符號整數(shù),最小值? 2^15 ,最大值 2^15-1 | 42 |
integer、int | 32位有符號整數(shù),最小值? 2^31 ,最大值 2^31-1 | |
bigint | 64位有符號整數(shù),最小值? 2^63 ,最大值 2^63-1 | |
real | 32位浮點數(shù),遵循IEEE 754二進(jìn)制浮點數(shù)運算標(biāo)準(zhǔn) | 2.71828 |
double | 64位浮點數(shù),遵循IEEE 754二進(jìn)制浮點數(shù)運算標(biāo)準(zhǔn) | 2.71828 |
decimal | 固定精度小數(shù) | 123456.7890 |
varchar、varchar(n) | 可變長度字符串。字符長度為m(m < n),則分配m個字符 | “hello world” |
char、char(n) | 固定長度字符串。總是分配n個字符,不管字符長度是多少。char表示char(1) | “hello world” |
- 當(dāng)字符串cast為char(n),不足的字符用空格填充,多的字符被截斷
- 當(dāng)插入字符串到類型為char(n)的列,不足的字符用空格填充,多了就報錯
- 當(dāng)插入字符串到類型為varchar(n)的列,多了就報錯
2)集合數(shù)據(jù)類型
類型 | 示例 |
array | array[‘a(chǎn)pples’, ‘oranges’, ‘pears’] |
map | map(array[‘a(chǎn)’, ‘b’, ‘c’], array[1, 2, 3]) |
json | |
row | row(1, 2, 3) |
3)日期時間數(shù)據(jù)類型
官方文檔:https://trino.io/docs/current/functions.html
類型 | 描述 | 示例 |
date | 包含年、月、日的日期 | 2023-05-14 |
time | 包含時、分、秒、毫秒的時間, 時區(qū)可選 | 16:26:08.123 +08:00 |
timestamp | 包含日期和時間, 時區(qū)可選 | 2023-05-14 16:26:08.123 Asia/Shanghai |
interval year to month | 間隔時間跨度為年、月 | interval ‘1-2’ year to month |
interval day to second | 間隔時間跨度為天、時、分、秒、毫秒 | interval ‘5’ day to second |
七、Trino 內(nèi)置函數(shù)
Trino(之前叫Presto)提供了豐富的內(nèi)置函數(shù),可以滿足各種SQL查詢的需求。下面對Trino內(nèi)置函數(shù)進(jìn)行詳細(xì)說明。
1)數(shù)學(xué)函數(shù)
- abs(numeric):返回數(shù)值參數(shù)的絕對值。
- ceil(numeric):返回不小于參數(shù)的最小整數(shù)。
- floor(numeric):返回不大于參數(shù)的最大整數(shù)。
- exp(numeric):返回e的冪次方。
- log(numeric):返回參數(shù)的自然對數(shù)。
- log10(numeric):返回參數(shù)的以10為底的對數(shù)。
- sqrt(numeric):返回參數(shù)的平方根。
- power(numeric, numeric):返回第一個參數(shù)乘以第二個參數(shù)的冪次方。
2)字符串函數(shù)
- concat(string1, string2, ...): 連接兩個或多個字符串。
- length(str):返回字符串的長度。
- substring(str, from [, length ]):返回字符串的子串,從指定位置開始(從1開始計算),如果提供長度參數(shù),則截取固定長度。
- replace(str, pattern, replacement):將字符串中的符合模式的字符串替換成替換字符串。
- lower(str) / upper(str):將字符串轉(zhuǎn)化成小寫/大寫。
- trim([characters from] string):去掉字符串頭尾指定的空格或字符。
- regexp_extract(string, pattern, index):指定模式,并返回特定位置(從1開始計算)的匹配結(jié)果。
- regexp_replace(string, pattern, replacement):將字符串中的符合模式的字符串替換成替換字符串。
3)日期時間函數(shù)
- date(date_string):將日期字符串轉(zhuǎn)化成日期格式。
- current_date:返回當(dāng)前日期。
- current_time:返回當(dāng)前時間。
- current_timestamp:返回當(dāng)前時間戳。
- year(date):返回日期的年份。
- month(date):返回日期的月份。
- day(date):返回日期的日份。
- hour(timestamp):返回時間戳的小時部分。
- minute(timestamp):返回時間戳的分鐘部分。
- second(timestamp):返回時間戳的秒部分。
4)聚合函數(shù)
- count(*) / count(expression):返回記錄數(shù)。count(*)表示所有行的行數(shù),一般用于計算表的行數(shù)。count(expression)返回expression的不同值的數(shù)量。
- sum(number):返回列數(shù)值的總和。
- avg(numeric):返回數(shù)值列的平均值。
- max(value) / min(value):返回列的最大值/最小值。
- array_agg(expression):將指定表達(dá)式的結(jié)果合并為一個數(shù)組。
5)邏輯函數(shù)
- if(condition, true_value, false_value):如果條件為真,返回true_value,否則返回false_value。
- nullif(expression1, expression2):如果expression1等于expression2,則返回null。
- coalesce(expression1, expression2, ...):返回參數(shù)列表中第一個非空的值。
- and(x1, x2, ...) / or(x1, x2, ...) / not(x):邏輯運算符,返回相應(yīng)的邏輯值。
6)類型轉(zhuǎn)換函數(shù)
- cast(expression AS type):將表達(dá)式轉(zhuǎn)化為指定類型。
- try_cast(expression AS type):嘗試將表達(dá)式轉(zhuǎn)化為指定類型,如果無法轉(zhuǎn)化,則返回null。
- to_json(expression):將指定的值序列化為JSON字符串。
- from_json(jsonString, type):將一個JSON字符串反序列化為指定類型。
- to_array(map) / to_map(array):將一個map(array)轉(zhuǎn)化為一個數(shù)組(map)。
這些內(nèi)置函數(shù)只是Trino中的部分函數(shù),Trino還支持大量其他內(nèi)置函數(shù),可以參閱Trino的官方文檔獲得更詳細(xì)、更全面的信息。
八、Trino 中的 SQL 語法
連接:
# 如不是通過容器部署,自己有環(huán)境,可以忽略下來容器登錄的步驟
docker exec -it trino-coordinator bash
# --catalog:數(shù)據(jù)源 --schema:數(shù)據(jù)庫
${TRINO_HOME}/bin/trino-cli --server http://trino-coordinator:8080 --user=hadoop官方文檔:https://trino.io/docs/current/sql.html
1)數(shù)據(jù)源語法
一般數(shù)據(jù)源配置在${TRINO_HOME}/etc/catalog目錄下
# 查看數(shù)據(jù)源
show catalogs;當(dāng)然也可以通過sql創(chuàng)建,示例如下:
1、配置hive數(shù)據(jù)源${TRINO_HOME}/etc/catalog/hive.conf
connector.name=hive
hive.metastore.uri=thrift://hive-metastore:9083
hive.config.resources='/opt/apache/trino/etc/catalog/core-site.xml,/opt/apache/trino/etc/catalog/hdfs-site.xml'2、查看catalog
${TRINO_HOME}/bin/trino-cli --server http://trino-coordinator:8080 --user=hadoop
SHOW CATALOGS;
# 查看當(dāng)前 catalog
SELECT current_catalog;2)數(shù)據(jù)庫語法(schemas)
在Trino中,catalog用于訪問數(shù)據(jù)源和外部系統(tǒng)。每個catalog都可以包含一個或多個schema,每個schema包含一組相關(guān)的表。你可以在Trino中使用CREATE SCHEMA、DROP SCHEMA、RENAME SCHEMA和SHOW SCHEMAS等語句來管理schema。
語法:
CREATE SCHEMA [ IF NOT EXISTS ] schema_name
[ AUTHORIZATION ( user | USER user | ROLE role ) ]
[ WITH ( property_name = expression [, ...] ) ]以下是一些用于操作catalog schema的示例:
- 創(chuàng)建一個名為schema_test的新schema
#USE 語法,USE catalog.schema
# USE schema
USE hive.default;
CREATE SCHEMA IF NOT EXISTS schema_test;
# 查看
show schemas;【注意】如果登錄時,沒有帶--scheme,就必須USE切換scheme,才能使用創(chuàng)建schema。
- 查看scheme
show schemas from hive;
show schemas;- 刪除一個名為my_schema的schema
DROP SCHEMA hive.schema_test;- 查看當(dāng)前scheme
# 查看當(dāng)前catalog
SELECT current_catalog;
# 查看scheme
SELECT current_schema;3)表 DDL 語法
在Trino中,你可以使用CREATE TABLE語句來創(chuàng)建表,使用ALTER TABLE來修改表的結(jié)構(gòu)和元數(shù)據(jù),并使用DROP TABLE來刪除表。
下面分別介紹一下這幾個操作的語法和參數(shù):
1、創(chuàng)建表 - CREATE TABLE
語法:
CREATE TABLE [ IF NOT EXISTS ]
table_name (
{ column_name data_type [ NOT NULL ]
[ COMMENT comment ]
[ WITH ( property_name = expression [, ...] ) ]
| LIKE existing_table_name
[ { INCLUDING | EXCLUDING } PROPERTIES ]
}
[, ...]
)
[ COMMENT table_comment ]
[ WITH ( property_name = expression [, ...] ) ]使用CREATE TABLE創(chuàng)建一個新的表。下面是一個示例:
CREATE TABLE orders (
orderkey bigint,
orderstatus varchar,
totalprice double,
orderdate date
)
WITH (format = 'ORC')
# 在Trino中,你可以使用 FORMAT 子句指定查詢結(jié)果輸出的格式。Trino支持多種常見格式,包括文本(text)、CSV、JSON、javax.json、Avro、Parquet、ORC、RCFile等。其中,my_table是你想要創(chuàng)建的表名,后面的括號中列出了表的列和對應(yīng)的數(shù)據(jù)類型。在Trino中可以定義多種數(shù)據(jù)類型,如integer、varchar、boolean等等。更多數(shù)據(jù)類型可以查看Trino官方文檔。
你可以使用CREATE TABLE的參數(shù)進(jìn)行更高級的操作,例如指定分桶(bucket)、分區(qū)(partition)和格式(format),以下是一些常用參數(shù)的示例:
CREATE TABLE my_table3 (
column1 int,
column2 varchar(64),
column3 varchar(64),
column4 varchar(64)
)
WITH (
format = 'ORC',
partitioned_by = ARRAY['column3','column4'],
bucketed_by = ARRAY['column2'],
bucket_count = 10
);
# 注意:partitioned字段必須是表的最后的字段這個示例中,表使用ORC格式存儲,按照column3和column4列進(jìn)行了分區(qū),使用column2列進(jìn)行了分桶,并設(shè)置了10個桶。
2、修改表 - ALTER TABLE
使用ALTER TABLE命令修改現(xiàn)有表。下面是一些常見的用法:
- 添加列
ALTER TABLE my_table ADD COLUMN new_column datatype;- 修改列
ALTER TABLE my_table ALTER COLUMN column1 TYPE new_datatype;- 刪除列
ALTER TABLE my_table DROP COLUMN column1;- 添加分區(qū)
ALTER TABLE my_table ADD PARTITION (column1 = 'value1', column2 = 'value2');- 刪除分區(qū)
ALTER TABLE my_table DROP PARTITION (column1 = 'value1', column2 = 'value2', ...);3、刪除表 - DROP TABLE
使用DROP TABLE語句刪除現(xiàn)有表。下面是一個示例:
DROP TABLE my_table;
-- 如報錯:io.prestosql.spi.security.AccessDeniedException: Access Denied: Cannot drop table
-- 在catalog hive中添加以下兩行
-- hive.allow-drop-table=true
-- hive.allow-rename-table=true注意:刪除一個表將會永久刪除該表的全部數(shù)據(jù),慎重操作!
4、trino 中的分區(qū)分桶
在Trino中,你可以使用分區(qū)(partition)和分桶(bucket)來優(yōu)化查詢性能,提高查詢速度和效率。
1、分區(qū)(partition)
- 分區(qū)是指把數(shù)據(jù)按照一定規(guī)則劃分成若干部分(比如按照日期、地區(qū)、類別等),每個部分就是一個分區(qū)。在Trino中,你可以使用 CREATE TABLE 語句的 partitioned_by 子句來創(chuàng)建一個分區(qū)表,你可以寫入數(shù)據(jù)到這個表的每個分區(qū)。
- 使用分區(qū)對于查詢過濾條件的列進(jìn)行過濾非常高效。Trino實際上將所有數(shù)據(jù)按照分區(qū)規(guī)則分布到磁盤的不同目錄下,當(dāng)你執(zhí)行包含了分區(qū)過濾的查詢時,Trino會自動發(fā)現(xiàn)這個過濾條件,并且只讀取符合條件的分區(qū)數(shù)據(jù),這樣就可以大大提高查詢效率。
以下是一個創(chuàng)建一個按照日期分區(qū)的示例:
CREATE TABLE my_part_table (
id bigint,
name varchar(64),
event_date date
)
WITH (
partitioned_by = ARRAY['event_date']
);2、分桶(bucket)
- 分桶是將表中的數(shù)據(jù)劃分成若干個桶(bucket)存儲的方式。在Trino中,你可以使用 CREATE TABLE 語句的 bucketed_by 和 bucket_count 子句來創(chuàng)建一個分桶表。在建表時,你需要定義一個或多個bucket列并設(shè)置桶的數(shù)量,Trino會根據(jù)這些設(shè)置把表中的數(shù)據(jù)分配到不同的桶中。
使用分桶后,Trino優(yōu)化器可以將查詢操作分配到不同的節(jié)點上并行執(zhí)行,以實現(xiàn)更快的查詢速度。比如,如果你的分桶表中有100個桶,Trino可以把這100個桶分配到100個不同的節(jié)點上并行執(zhí)行查詢操作,從而大大提高查詢效率。
以下是一個創(chuàng)建分桶的示例:
CREATE TABLE my_bucket_table (
id INT,
name VARCHAR,
age INT
)
WITH (
bucket_count = 10,
bucketed_by = ARRAY['id']
);
CREATE TABLE my_bucket_table_new (
id INT,
name VARCHAR,
age INT
)
WITH (
bucket_count = 10,
bucketed_by = ARRAY['id']
);4)添加數(shù)據(jù)
INSERT INTO my_bucket_table (id, name, age) VALUES (1, 'Tom', 20), (2, 'Jerry', 23);
INSERT INTO my_bucket_table_new SELECT * FROM my_bucket_table;