
一、背景
自2014年大數(shù)據(jù)首次寫入政府工作報告,大數(shù)據(jù)已經(jīng)發(fā)展7年。大數(shù)據(jù)的類型也從交易數(shù)據(jù)延伸到交互數(shù)據(jù)與傳感數(shù)據(jù)。數(shù)據(jù)規(guī)模也到達了PB級別。
大數(shù)據(jù)的規(guī)模大到對數(shù)據(jù)的獲取、存儲、管理、分析超出了傳統(tǒng)數(shù)據(jù)庫軟件工具能力范圍。在這個背景下,各種大數(shù)據(jù)相關工具相繼出現(xiàn),用于應對各種業(yè)務場景需求。從Hadoop生態(tài)的Hive, Spark, Presto, Kylin, Druid到非Hadoop生態(tài)的ClickHouse, Elasticsearch,不一而足...
這些大數(shù)據(jù)處理工具特性不同,應用場景不同,但是對外提供的接口或者說操作語言都是相似的,即各個組件都是支持SQL語言。只是基于不同的應用場景和特性,實現(xiàn)了各自的SQL方言。這就要求相關開源項目自行實現(xiàn)SQL解析。在這個背景下,誕生于1989年的語法解析器生成器ANTLR迎來了黃金時代。
二、簡介
ANTLR是開源的語法解析器生成器,距今已有30多年的歷史。是一個經(jīng)歷了時間考驗的開源項目。一個程序從源代碼到機器可執(zhí)行,基本需要3個階段:編寫、編譯、執(zhí)行。
在編譯階段,需要進行詞法和語法的分析。ANTLR聚焦的問題就是把源碼進行詞法和句法分析,產(chǎn)生一個樹狀的分析器。ANTLR幾乎支持對所有主流編程語言的解析。從antlr/grammars-v4可以看到,ANTLR支持Java,C, Python, SQL等數(shù)十種編程語言。通常我們沒有擴展編程語言的需求,所以大部分情況下這些語言編譯支持更多是供學習研究使用,或者用在各種開發(fā)工具(NetBeans、Intellij)中用于校驗語法正確性、和格式化代碼。
對于SQL語言,ANTLR的應用廣度和深度會更大,這是由于Hive, Presto, SparkSQL等由于需要對SQL的執(zhí)行進行定制化開發(fā),比如實現(xiàn)分布式查詢引擎、實現(xiàn)各種大數(shù)據(jù)場景下獨有的特性等。
三、基于ANTLR4實現(xiàn)四則運算
當前我們主要使用的是ANTLR4。在《The Definitive ANTLR4 Reference》一書中,介紹了基于ANTLR4的各種有趣的應用場景。比如:實現(xiàn)一個支持四則運算的計算器;實現(xiàn)JSON等格式化文本的解析和提取;
將JSON轉換成XML;從Java源碼中提取接口等。本節(jié)以實現(xiàn)四則運算計算器為例,介紹Antlr4的簡單應用,為后面實現(xiàn)基于ANTLR4解析SQL鋪平道路。實際上,支持數(shù)字運算也是各個編程語言必須具備的基本能力。
3.1 自行編碼實現(xiàn)
在沒有ANTLR4時,我們想實現(xiàn)四則運算該怎么處理呢?有一種思路是基于棧實現(xiàn)。例如,在不考慮異常處理的情況下,自行實現(xiàn)簡單的四則運算代碼如下:
package org.example.calc;
import java.util.*;
public class CalcByHand {
// 定義操作符并區(qū)分優(yōu)先級,*/ 優(yōu)先級較高
public static Set<String> opSet1 = new HashSet<>();
public static Set<String> opSet2 = new HashSet<>();
static{
opSet1.add("+");
opSet1.add("-");
opSet2.add("*");
opSet2.add("/");
}
public static void main(String[] args) {
String exp="1+3*4";
//將表達式拆分成token
String[] tokens = exp.split("((?<=[\\+|\\-|\\*|\\/])|(?=[\\+|\\-|\\*|\\/]))");
Stack<String> opStack = new Stack<>();
Stack<String> numStack = new Stack<>();
int proi=1;
// 基于類型放到不同的棧中
for(String token: tokens){
token = token.trim();
if(opSet1.contains(token)){
opStack.push(token);
proi=1;
}else if(opSet2.contains(token)){
proi=2;
opStack.push(token);
}else{
numStack.push(token);
// 如果操作數(shù)前面的運算符是高優(yōu)先級運算符,計算后結果入棧
if(proi==2){
calcExp(opStack,numStack);
}
}
}
while (!opStack.isEmpty()){
calcExp(opStack,numStack);
}
String finalVal = numStack.pop();
System.out.println(finalVal);
}
private static void calcExp(Stack<String> opStack, Stack<String> numStack) {
double right=Double.valueOf(numStack.pop());
double left = Double.valueOf(numStack.pop());
String op = opStack.pop();
String val;
switch (op){
case "+":
val =String.valueOf(left+right);
break;
case "-":
val =String.valueOf(left-right);
break;
case "*":
val =String.valueOf(left*right);
break;
case "/":
val =String.valueOf(left/right);
break;
default:
throw new UnsupportedOperationException("unsupported");
}
numStack.push(val);
}
}
代碼量不大,用到了數(shù)據(jù)結構-棧的特性,需要自行控制運算符優(yōu)先級,特性上沒有支持括號表達式,也沒有支持表達式賦值。接下來看看使用ANTLR4實現(xiàn)。
3.2 基于ANTLR4實現(xiàn)
使用ANTLR4編程的基本流程是固定的,通常分為如下三步:
- 基于需求按照ANTLR4的規(guī)則編寫自定義語法的語義規(guī)則, 保存成以g4為后綴的文件。
- 使用ANTLR4工具處理g4文件,生成詞法分析器、句法分析器代碼、詞典文件。
- 編寫代碼繼承Visitor類或實現(xiàn)Listener接口,開發(fā)自己的業(yè)務邏輯代碼。
基于上面的流程,我們借助現(xiàn)有案例剖析一下細節(jié)。
第一步:基于ANTLR4的規(guī)則定義語法文件,文件名以g4為后綴。例如實現(xiàn)計算器的語法規(guī)則文件命名為LabeledExpr.g4。其內容如下:
grammar LabeledExpr; // rename to distinguish from Expr.g4
prog: stat+ ;
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*' ; // assigns token name to '*' used above in grammar
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ; // match identifiers
INT : [0-9]+ ; // match integers
NEWLINE:'\r'? '\n' ; // return newlines to parser (is end-statement signal)
WS : [ \t]+ -> skip ; // toss out whitespace
(注:此文件案例來源于《The Definitive ANTLR4 Reference》)
簡單解讀一下LabeledExpr.g4文件。ANTLR4規(guī)則是基于正則表達式定義定義。規(guī)則的理解是自頂向下的,每個分號結束的語句表示一個規(guī)則 。例如第一行:grammar LabeledExpr; 表示我們的語法名稱是LabeledExpr, 這個名字需要跟文件名需要保持一致。Java編碼也有相似的規(guī)則:類名跟類文件一致。
- 規(guī)則prog 表示prog是一個或多個stat。
- 規(guī)則stat 適配三種子規(guī)則:空行、表達式expr、賦值表達式 ID’=’expr。
- 表達式expr適配五種子規(guī)則:乘除法、加減法、整型、ID、括號表達式。很顯然,這是一個遞歸的定義。
最后定義的是組成復合規(guī)則的基礎元素,比如:
- 規(guī)則ID: [a-zA-Z]+表示ID限于大小寫英文字符串;
- INT: [0-9]+; 表示INT這個規(guī)則是0-9之間的一個或多個數(shù)字,當然這個定義其實并不嚴格。再嚴格一點,應該限制其長度。
在理解正則表達式的基礎上,ANTLR4的g4語法規(guī)則還是比較好理解的。
定義ANTLR4規(guī)則需要注意一種情況,即可能出現(xiàn)一個字符串同時支持多種規(guī)則,如以下的兩個規(guī)則:
- ID: [a-zA-Z]+;
- FROM: ‘from’;
很明顯,字符串” from”同時滿足上述兩個規(guī)則,ANTLR4處理的方式是按照定義的順序決定。這里ID定義在FROM前面,所以字符串from會優(yōu)先匹配到ID這個規(guī)則上。
其實在定義好與法規(guī)中,編寫完成g4文件后,ANTLR4已經(jīng)為我們完成了50%的工作:幫我們實現(xiàn)了整個架構及接口了,剩下的開發(fā)工作就是基于接口或抽象類進行具體的實現(xiàn)。實現(xiàn)上有兩種方式來處理生成的語法樹,其一Visitor模式,另一種方式是Listener(監(jiān)聽器模式)。
3.2.1 使用Visitor模式
第二步:使用ANTLR4工具解析g4文件,生成代碼。即ANTLR工具解析g4文件,為我們自動生成基礎代碼。流程圖示如下:
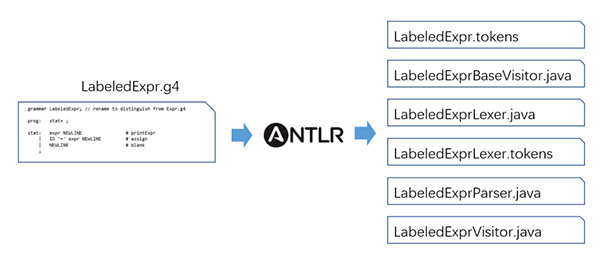
命令行如下:
antlr4 -package org.example.calc -no-listener -visitor .\LabeledExpr.g4
命令執(zhí)行完成后,生成的文件如下:
$ tree .
├── LabeledExpr.g4
├── LabeledExpr.tokens
├── LabeledExprBaseVisitor.java
├── LabeledExprLexer.java
├── LabeledExprLexer.tokens
├── LabeledExprParser.java
└── LabeledExprVisitor.java
首先開發(fā)入口類Calc.java。Calc類是整個程序的入口,調用ANTLR4的lexer和parser類核心代碼如下:
ANTLRInputStream input = new ANTLRInputStream(is);
LabeledExprLexer lexer = new LabeledExprLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
LabeledExprParser parser = new LabeledExprParser(tokens);
ParseTree tree = parser.prog(); // parse
EvalVisitor eval = new EvalVisitor();
eval.visit(tree);
接下來定義類繼承LabeledExprBaseVisitor類,覆寫的方法如下:
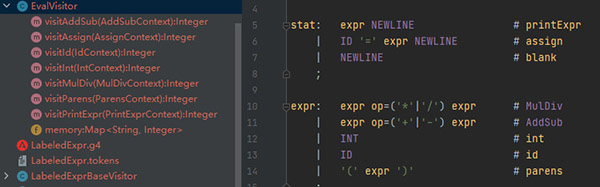
從圖中可以看出,生成的代碼和規(guī)則定義是對應起來的。例如visitAddSub對應AddSub規(guī)則,visitId對應id規(guī)則。以此類推…實現(xiàn)加減法的代碼如下:
/** expr op=('+'|'-') expr */
@Override
public Integer visitAddSub(LabeledExprParser.AddSubContext ctx) {
int left = visit(ctx.expr(0)); // get value of left subexpression
int right = visit(ctx.expr(1)); // get value of right subexpression
if ( ctx.op.getType() == LabeledExprParser.ADD ) return left + right;
return left - right; // must be SUB
}相當直觀。代碼編寫完成后,就是運行Calc。運行Calc的main函數(shù),在交互命令行輸入相應的運算表達式,換行Ctrl+D即可看到運算結果。例如1+3*4=13。
3.2.2 使用Listener模式
類似的,我們也可以使用Listener模式實現(xiàn)四則運算。命令行如下:
antlr4 -package org.example.calc -listener .\LabeledExpr.g4
該命令的執(zhí)行同樣會為我們生產(chǎn)框架代碼。在框架代碼的基礎上,我們開發(fā)入口類和接口實現(xiàn)類即可。首先開發(fā)入口類Calc.java。Calc類是整個程序的入口,調用ANTLR4的lexer和parser類代碼如下:
ANTLRInputStream input = new ANTLRInputStream(is);
LabeledExprLexer lexer = new LabeledExprLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
LabeledExprParser parser = new LabeledExprParser(tokens);
ParseTree tree = parser.prog(); // parse
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(new EvalListener(), tree);
可以看出生成ParseTree的調用邏輯一模一樣。實現(xiàn)Listener的代碼略微復雜一些,也需要用到棧這種數(shù)據(jù)結構,但是只需要一個操作數(shù)棧就可以了,也無需自行控制優(yōu)先級。以AddSub為例:
@Override
public void exitAddSub(LabeledExprParser.AddSubContext ctx) {
Double left = numStack.pop();
Double right= numStack.pop();
Double result;
if (ctx.op.getType() == LabeledExprParser.ADD) {
result = left + right;
} else {
result = left - right;
}
numStack.push(result);
}
直接從棧中取出操作數(shù),進行運算即可。
3.2.3 小結
關于Listener模式和Visitor模式的區(qū)別,《The Definitive ANTLR 4 Reference》一書中有清晰的解釋:
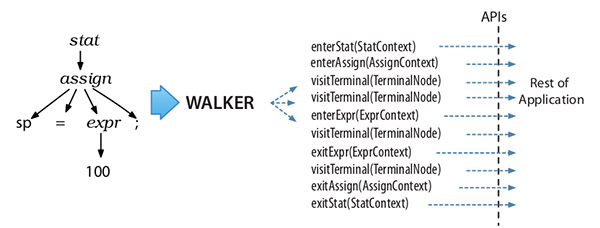
Listener模式:
Visitor模式
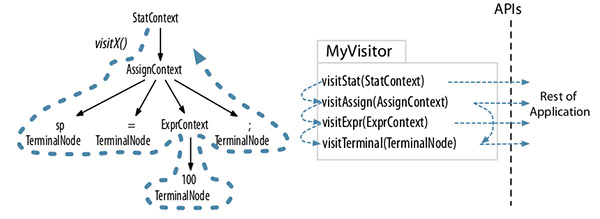
- Listener模式通過walker對象自行遍歷,不用考慮其語法樹上下級關系。Vistor需要自行控制訪問的子節(jié)點,如果遺漏了某個子節(jié)點,那么整個子節(jié)點都訪問不到了。
- Listener模式的方法沒有返回值,Vistor模式可以設定任意返回值。
- Listener模式的訪問棧清晰明確,Vistor模式是方法調用棧,如果實現(xiàn)出錯有可能導致StackOverFlow。
通過這個簡單的例子,我們驅動Antlr4實現(xiàn)了一個簡單的計算器。學習了ANTLR4的應用流程。了解了g4語法文件的定義方式、Visitor模式和Listener模式。通過ANTLR4,我們生成了ParseTree,并基于Visitor模式和Listener模式訪問了這個ParseTree,實現(xiàn)了四則運算。
綜合上述的例子可以發(fā)現(xiàn),如果沒有ANTLR4,我們自行編寫算法也能實現(xiàn)同樣的功能。但是使用ANTLR不用關心表達式串的解析流程,只關注具體的業(yè)務實現(xiàn)即可,非常省心和省事。
更重要的是,ANTLR4相比自行實現(xiàn)提供了更具想象空間的抽象邏輯,上升到了方法論的高度,因為它已經(jīng)不局限于解決某個問題,而是解決一類問題。可以說ANTLR相比于自行硬編碼解決問題的思路有如數(shù)學領域普通的面積公式和微積分的差距。
四、參考Presto源碼開發(fā)SQL解析器
前面介紹了使用ANTLR4實現(xiàn)四則運算,其目的在于理解ANTLR4的應用方式。接下來圖窮匕首見,展示出我們的真正目的:研究ANTLR4在Presto中如何實現(xiàn)SQL語句的解析。
支持完整的SQL語法是一個龐大的工程。在presto中有完整的SqlBase.g4文件,定義了presto支持的所有SQL語法,涵蓋了DDL語法和DML語法。該文件體系較為龐大,并不適合學習探究某個具體的細節(jié)點。
為了探究SQL解析的過程,理解SQL執(zhí)行背后的邏輯,在簡單地閱讀相關資料文檔的基礎上,我選擇自己動手編碼實驗。為此,定義一個小目標:實現(xiàn)一個SQL解析器。用該解析器實現(xiàn)select field from table語法,從本地的csv數(shù)據(jù)源中查詢指定的字段。
4.1 裁剪SelectBase.g4文件
基于同實現(xiàn)四則運算器同樣的流程,首先定義SelectBase.g4文件。由于有了Presto源碼作為參照系,我們的SelectBase.g4并不需要自己開發(fā),只需要基于Presto的g4文件裁剪即可。裁剪后的內容如下:
grammar SqlBase;
tokens {
DELIMITER
}
singleStatement
: statement EOF
;
statement
: query #statementDefault
;
query
: queryNoWith
;
queryNoWith:
queryTerm
;
queryTerm
: queryPrimary #queryTermDefault
;
queryPrimary
: querySpecification #queryPrimaryDefault
;
querySpecification
: SELECT selectItem (',' selectItem)*
(FROM relation (',' relation)*)?
;
selectItem
: expression #selectSingle
;
relation
: sampledRelation #relationDefault
;
expression
: booleanExpression
;
booleanExpression
: valueExpression #predicated
;
valueExpression
: primaryExpression #valueExpressionDefault
;
primaryExpression
: identifier #columnReference
;
sampledRelation
: aliasedRelation
;
aliasedRelation
: relationPrimary
;
relationPrimary
: qualifiedName #tableName
;
qualifiedName
: identifier ('.' identifier)*
;
identifier
: IDENTIFIER #unquotedIdentifier
;
SELECT: 'SELECT';
FROM: 'FROM';
fragment DIGIT
: [0-9]
;
fragment LETTER
: [A-Z]
;
IDENTIFIER
: (LETTER | '_') (LETTER | DIGIT | '_' | '@' | ':')*
;
WS
: [ \r\n\t]+ -> channel(HIDDEN)
;
// Catch-all for anything we can't recognize.
// We use this to be able to ignore and recover all the text
// when splitting statements with DelimiterLexer
UNRECOGNIZED
: .
;
相比presto源碼中700多行的規(guī)則,我們裁剪到了其1/10的大小。該文件的核心規(guī)則為: SELECT selectItem (',' selectItem)* (FROM relation (',' relation)*)?
通過理解g4文件,也可以更清楚地理解我們查詢語句的構成。例如通常我們最常見的查詢數(shù)據(jù)源是數(shù)據(jù)表。但是在SQL語法中,我們查詢數(shù)據(jù)表被抽象成了relation。
這個relation有可能來自于具體的數(shù)據(jù)表,或者是子查詢,或者是JOIN,或者是數(shù)據(jù)的抽樣,或者是表達式的unnest。在大數(shù)據(jù)領域,這樣的擴展會極大方便數(shù)據(jù)的處理。
例如,使用unnest語法解析復雜類型的數(shù)據(jù),SQL如下:

盡管SQL較為復雜,但是通過理解g4文件,也能清晰理解其結構劃分。回到SelectBase.g4文件,同樣我們使用Antlr4命令處理g4文件,生成代碼:
antlr4 -package org.example.antlr -no-listener -visitor .\SqlBase.g4
這樣就生成了基礎的框架代碼。接下來就是自行處理業(yè)務邏輯的工作了。
4.2 遍歷語法樹封裝SQL結構信息
接下來基于SQL語法定義語法樹的節(jié)點類型,如下圖所示。
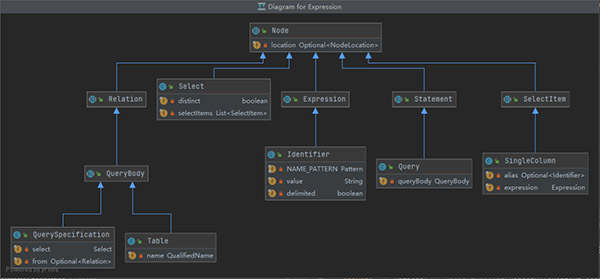
通過這個類圖,可以清晰明了看清楚SQL語法中的各個基本元素。
然后基于visitor模式實現(xiàn)自己的解析類AstBuilder (這里為了簡化問題,依然從presto源碼中進行裁剪)。以處理querySpecification規(guī)則代碼為例:
@Override
public Node visitQuerySpecification(SqlBaseParser.QuerySpecificationContext context)
{
Optional<Relation> from = Optional.empty();
List<SelectItem> selectItems = visit(context.selectItem(), SelectItem.class);
List<Relation> relations = visit(context.relation(), Relation.class);
if (!relations.isEmpty()) {
// synthesize implicit join nodes
Iterator<Relation> iterator = relations.iterator();
Relation relation = iterator.next();
from = Optional.of(relation);
}
return new QuerySpecification(
getLocation(context),
new Select(getLocation(context.SELECT()), false, selectItems),
from);
}
通過代碼,我們已經(jīng)解析出了查詢的數(shù)據(jù)源和具體的字段,封裝到了QuerySpecification對象中。
4.3 應用Statement對象實現(xiàn)數(shù)據(jù)查詢
通過前面實現(xiàn)四則運算器的例子,我們知道ANTLR把用戶輸入的語句解析成ParseTree。業(yè)務開發(fā)人員自行實現(xiàn)相關接口解析ParseTree。Presto通過對輸入sql語句的解析,生成ParseTree, 對ParseTree進行遍歷,最終生成了Statement對象。核心代碼如下:
SqlParser sqlParser = new SqlParser();
Statement statement = sqlParser.createStatement(sql);
有了Statement對象我們如何使用呢?結合前面的類圖,我們可以發(fā)現(xiàn):
- Query類型的Statement有QueryBody屬性。
- QuerySpecification類型的QueryBody有select屬性和from屬性。
通過這個結構,我們可以清晰地獲取到實現(xiàn)select查詢的必備元素:
- 從from屬性中獲取待查詢的目標表Table。這里約定表名和csv文件名一致。
- 從select屬性中獲取待查詢的目標字段SelectItem。這里約定csv首行為title行。
整個業(yè)務流程就清晰了,在解析sql語句生成statement對象后,按如下的步驟:
s1: 獲取查詢的數(shù)據(jù)表以及字段。
s2: 通過數(shù)據(jù)表名稱定為到數(shù)據(jù)文件,并讀取數(shù)據(jù)文件數(shù)據(jù)。
s3: 格式化輸出字段名稱到命令行。
s4: 格式化輸出字段內容到命令行。
為了簡化邏輯,代碼只處理主線,不做異常處理。
/**
* 獲取待查詢的表名和字段名稱
*/
QuerySpecification specification = (QuerySpecification) query.getQueryBody();
Table table= (Table) specification.getFrom().get();
List<SelectItem> selectItems = specification.getSelect().getSelectItems();
List<String> fieldNames = Lists.newArrayList();
for(SelectItem item:selectItems){
SingleColumn column = (SingleColumn) item;
fieldNames.add(((Identifier)column.getExpression()).getValue());
}
/**
* 基于表名確定查詢的數(shù)據(jù)源文件
*/
String fileLoc = String.format("./data/%s.csv",table.getName());
/**
* 從csv文件中讀取指定的字段
*/
Reader in = new FileReader(fileLoc);
Iterable<CSVRecord> records = CSVFormat.RFC4180.withFirstRecordAsHeader().parse(in);
List<Row> rowList = Lists.newArrayList();
for(CSVRecord record:records){
Row row = new Row();
for(String field:fieldNames){
row.addColumn(record.get(field));
}
rowList.add(row);
}
/**
* 格式化輸出到控制臺
*/
int width=30;
String format = fieldNames.stream().map(s-> "%-"+width+"s").collect(Collectors.joining("|"));
System.out.println( "|"+String.format(format, fieldNames.toArray())+"|");
int flagCnt = width*fieldNames.size()+fieldNames.size();
String rowDelimiter = String.join("", Collections.nCopies(flagCnt, "-"));
System.out.println(rowDelimiter);
for(Row row:rowList){
System.out.println( "|"+String.format(format, row.getColumnList().toArray())+"|");
}
代碼僅供演示功能,暫不考慮異常邏輯,比如查詢字段不存在、csv文件定義字段名稱不符合要求等問題。
4.4 實現(xiàn)效果展示
在我們項目data目錄,存儲如下的csv文件:

cities.csv文件樣例數(shù)據(jù)如下:
"LatD","LatM","LatS","NS","LonD","LonM","LonS","EW","City","State"
41, 5, 59, "N", 80, 39, 0, "W", "Youngstown", OH
42, 52, 48, "N", 97, 23, 23, "W", "Yankton", SD
46, 35, 59, "N", 120, 30, 36, "W", "Yakima", WA
42, 16, 12, "N", 71, 48, 0, "W", "Worcester", MA
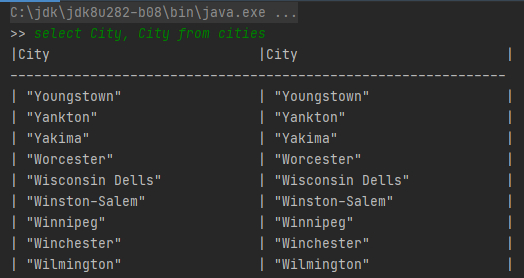
運行代碼查詢數(shù)據(jù)。使用SQL語句指定字段從csv文件中查詢。最終實現(xiàn)類似SQL查詢的效果如下:
SQL樣例1:select City, City from cities
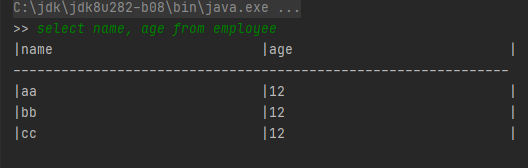
SQL樣例2:select name, age from employee
本節(jié)講述了如何基于Presto源碼,裁剪g4規(guī)則文件,然后基于Antlr4實現(xiàn)用sql語句從csv文件查詢數(shù)據(jù)。依托于對Presto源碼的裁剪進行編碼實驗,對于研究SQL引擎實現(xiàn),理解Presto源碼能起到一定的作用。
五、總結
本文基于四則運算器和使用SQL查詢csv數(shù)據(jù)兩個案例闡述了ANTLR4在項目開發(fā)中的應用思路和過程,相關的代碼可以在github上看到。理解ANTLR4的用法能夠幫助理解SQL的定義規(guī)則及執(zhí)行過程,輔助業(yè)務開發(fā)中編寫出高效的SQL語句。同時對于理解編譯原理,定義自己的DSL,抽象業(yè)務邏輯也大有裨益。紙上得來終覺淺,絕知此事要躬行。通過本文描述的方式研究源碼實現(xiàn),也不失為一種樂趣。
































