神還原物體復雜、高頻細節,4K-NeRF高保真視圖合成來了
超高分辨率作為記錄和顯示高質量圖像、視頻的一種標準受到眾多研究者的歡迎,與較低分辨率(1K 高清格式)相比,高分辨率捕獲的場景通常細節十分清晰,像素的信息被一個個小 patch 放大。但是,想要將這種技術應用于圖像處理和計算機視覺還面臨很多挑戰。
本文中,來自阿里巴巴的研究者專注于新的視圖合成任務,提出了一個名為 4K-NeRF 的框架,其基于 NeRF 的體積渲染方法可以實現在 4K 超高分辨率下高保真視圖合成。

論文地址:https://arxiv.org/abs/2212.04701
項目主頁:https://github.com/frozoul/4K-NeRF
話不多說,我們先來看看效果(以下視頻均進行了降采樣處理,原版 4K 視頻請參考原項目)。
方法
接下來我們來看看該研究是如何實現的。
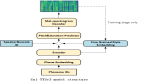
4K-NeRF pipeline(如下圖):使用基于 patch 的射線采樣技術,聯合訓練 VC-Encoder(View-Consistent)(基于 DEVO)在一個較低分辨率的空間中編碼三維幾何信息,之后經過一個 VC-Decoder 實現針對高頻細高質量的渲染與視圖一致性的增強。

該研究基于 DVGO [32] 中定義的公式實例化編碼器,學習到的基于體素網格的表示來顯式地編碼幾何結構:

對于每個采樣點,密度估計的三線性插值配備了一個 softplus 激活函數用于生成該點的體密度值:

顏色則是用一個小型的 MLP 估計算:

這樣可以通過累積沿著設線 r 的采樣點的特征來得到每個射線(或像素)的特征值:

為了更好地利用嵌入在 VC-Encoder 中的幾何屬性,該研究還通過估計每條射線 r 沿采樣射線軸的深度生成了一個深度圖。估計的深度圖為上面 Encoder 生成的場景三維結構提供了強有力的指導:

之后經過的網絡是通過疊加幾個卷積塊(既不使用非參數歸一化,也不使用降采樣操作)和交錯的升采樣操作來建立的。特別是,該研究不是簡單地將特征 F 和深度圖 M 連接起來,而是加入了深度圖中的深度信號,并通過學習變換將其注入每個塊來調制塊激活。

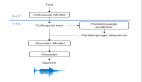
不同于傳統的 NeRF 方法中的像素級機制,該研究的方法旨在捕獲射線(像素)之間的空間信息。因此,這里不適合采用 NeRF 中隨機射線采樣的策略。因此該研究提出了一種基于 patch 的射線采樣訓練策略,以方便捕獲射線特征之間的空間依賴性。訓練中,首先將訓練視圖的圖像分割成大小為 N_p×N_p 的 patch p,以確保像素上的采樣概率是均勻的。當圖像空間維數不能被 patch 大小精確分割時,需要截斷 patch 直到邊緣,得到一組訓練 patch。然后從集合中隨機抽取一個 (或多個) patch,通過 patch 中像素的射線形成每次迭代的 mini-batch。
為了解決對精細細節產生模糊或過度平滑視覺效果的問題,該研究添加了對抗性損失和感知損失來規范精細細節合成。感知損失 通過預先訓練的 19 層 VGG 網絡來估計特征空間中預測的 patch
通過預先訓練的 19 層 VGG 網絡來估計特征空間中預測的 patch 和真值 p 之間的相似性:
和真值 p 之間的相似性:

該研究使用 損失而不是 MSE 來監督高頻細節的重建
損失而不是 MSE 來監督高頻細節的重建

此外,該研究還添加了一個輔助 MSE 損失,最后總的 loss 函數形式如下:

實驗效果
定性分析
實驗對 4K-NeRF 與其他模型進行了比較,可以看到基于普通 NeRF 的方法有著不同程度的細節丟失、模糊現象。相比之下,4K-NeRF 在這些復雜和高頻細節上呈現了高質量的逼真渲染,即使是在訓練視野有限的場景上。


定量分析
該研究與目前幾個方法在 4k 數據的基準下去做對比,包括 Plenoxels、DVGO、JaxNeRF、MipNeRF-360 和 NeRF-SR。實驗不但以圖像恢復的評價指標作為對比,還提供了推理時間和緩存內存,以供全面評估參考。結果如下:

雖然與一些方法的結果在一些指標上相差不大,但是得益于他們基于體素的方法在推理效率和內存成本上都取得了驚人的性能,允許在 300 ms 內渲染一個 4K 圖像。

總結及未來展望
該研究探討了 NeRF 在精細細節建模方面的能力,提出了一個新穎的框架來增強其在以極高分辨率的場景中恢復視圖一致的細微細節的表現力。此外,該研究還引入了一對保持幾何一致性的編解碼器模塊,在較低的空間中有效地建模幾何性質,并利用幾何感知特征之間的局部相關性實現全尺度空間中的視圖一致性的增強,并且基于 patch 的抽樣訓練框架也允許該方法集成來自面向感知的正則化的監督。該研究希望將框架合并到動態場景建模中的效果,以及神經渲染任務作為未來的方向。