Apache Kyuubi 1.6.0 新特性解讀

一、服務端增強
1、支持批(JAR)任務提交
Apache Kyuubi 是網易數帆開源的一款企業級的數據湖探索平臺,也是一款分布式和多租戶網關,為數據湖查詢例如 Spark、Flink 或者 trino 等提供 SQL 查詢服務。Kyuubi 支持多租戶、高可用以及多工作負載等功能特性,可以滿足企業內部諸如 ETL、BI 報表、交互式分析以及批數據處理等多種大數據場景的應用。
首先介紹一下 Apache Kyuubi 1.6.0 針對服務端增強引入了一些新特性。

Kyuubi 1.6.0 支持批(JAR)任務提交。Kyuubi 本身支持 SQL,但是很多公司不僅有 SQL 任務,還有 JAR 任務,在這里稱之為 Batch 任務,這時 Kyuubi 已有的功能就無法滿足 ETL 需求。在 Kyuubi 1.6.0 版本中提供了一個通過 Restful API 形式提交 Batch 任務,實現 Kyuubi Batch 的功能。
Kyuubi Batch 功能的實現設計如圖所示,用戶首先需要通過 POST 方式向 Kyuubi Server 發送一個 Create Batch 的請求,Kyuubi Server 接收到請求后,會立即返回 BatchId,Kyuubi Server 會使用這個 BatchId 作為一個 tag 傳入 Spark 中,加入到 Spark submit 的 conf 中。這里是使用 Yarn 作為 resource manager,所以這里會把這個 tag 傳到 Yarn context 中,這樣 BatchId 同時會和 Ky?uubi Server 以及 Yarn 都進行一次綁定。最后能夠通過這個 BatchId 去訪問 Kyuubi Server 獲取 Batch Report,Kyuubi Server 也能夠通過 BatchId 去訪問 Yarn 獲取 application report。同時 Kyuubi Server 也可以去合并 Kyuubi Server 端的一些信息,比如 Batch 任務的創建時間,創建的節點,這些信息可以返回給用戶,用戶也能夠通過這個 BatchId 去獲取 Spark submit 的日志,能夠清楚知道 Spark submit 執行到了哪些階段,以及 Kyuubi Server 端發生了什么,如果出現異常,也能夠清楚的找到異常信息。
對于用戶來說,還可以通過 DELETE 方式關閉目前正在運行的 Batch 任務,如果 Batch 任務沒有提交到 Yarn 集群,Kyuubi Server 需要 kill 掉本地的 spark submit 進程,如果已經提交到yarn集群,對于 Kyuubi Server 來說需要通過 BatchId kill 掉正在運行的 Batch 任務,并返回給用戶這個 close 的結果。
在示意圖左半部分的 4 個 API,是針對 Kyuubi 單個節點的,比如拉取 local job,kill 本地進程,都是需要在Kyuubi進程啟動節點處理的。一般在生產環境為了實現 HA 和 SLB,需要部署多臺 Kyuubi 節點,為了實現多個節點的 HA,我們在這個功能特性里面引入了 Metadata Store,以及 Kyuubi 內部節點的請求的轉發機制。
Metadata Store 是用來存儲一些 Batch 任務的元數據,比如 BatchId,創建 Batch 任務的 conf 和參數,還有 Kyuubi 節點的一些信息,比如哪個節點創建的 Batch,都會加入到這個元數據中。有了 Metadata Store 之后,Batch 元數據會對多個 Kyuubi 節點都可見,包括目前的狀態,以及哪個節點創建的 Batch。關于 Kyuubi Server 之間的 rest 請求轉發,我們可以在這里舉一個簡單的例子,比如采用 K8S 的 loadbalance 作為 Kyuubi Serve?r 的服務發現,每個 rest 請求都會從這個 loadbalance 中去隨機選擇一個 Kyuubi 節點來處理,比如在處理 Kyuubi Batch 的時候,是在 Kyuubi 節點 1 創建的,當用戶需要拉取 local job 的時候,會向 loadbalance 節點發送請求,load balance 會選擇 Kyuubi 節點 2 來處理這個請求,這個時候 Kyuubi 節點 2 會首先在內存中尋找這個 Batch 任務,如果沒有找到,就會去訪問 Metadata Store,去查詢這個任務的元數據信息。此時發現任務是由 Kyuubi 節點 1 創建的,就會把拉取日志的請求發送給 Kyuubi 節點 1,由 Kyuubi 節點 1 拉取本地日志,返回給 Kyuubi 節點 2,Kyuubi 節點 2 這個時候就會把這個結果返回給用戶。這樣用戶就可以成功的通過 Kyuubi 節點 2 獲取到 Spark submit 的日志。通過 Metadata Store 和節點內部轉發,實現了多節點的 HA,換句話來說,用戶是通過 load balance 連接到任意節點,都可以拿到 Batch 的信息。
通過運用 Metadata Store 和 Kyuubi Server,也可以在服務重啟的時候,做到恢復重啟前在運行的 Batch 任務。如果這個 Batch 任務沒有提交到 Yarn 集群,Kyuubi Server 會通過 Metadata Store 里面的元信息進行重新提交,如果已經提交給 Yarn 集群,Kyuubi Server 會監控運行的 Batch 任務的狀態。
在 Kyuubi1.6.0 版本中,對 Metadata Store 做了一些增強,當 Metadata Store 有問題,比如 MySQL 短時間不可用,這個時候會把更新 Metadata Store 的一些請求存儲在內存中,進行異步的重試,而不是打斷用戶的主線程。同時當 Metadata Store 不可用的時候,對于 Batch 任務的狀態請求會 fallback 到 Yarn 上獲取任務的狀態,對這個狀態進行一些補充,然后 Kyuubi Server 會返回給用戶。
同時在 1.6.0 版本中,Kyuubi 提供了 restful 的 CLI 和 SDK,可以讓用戶很方便的使用其提供的服務,而不需要使用 curl 命令或者一些很原始的 rest API,直接使用 CLI 對用戶來說更加友好,restful SDK 可以讓平臺層的用戶使用編程的方式進行集成。同時擁有這種中心化提交 Batch 任務的服務,可以方便的去監管 Spark submit 的行為,比如做一些提交權限的校驗,拒絕不合理的 JAR 提交,來提高整個集群的安全性。

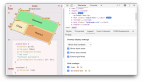
剛才也提到了,Kyuubi1.6.0 提供了 restful SDK 和 Command Line 來給用戶使用。restful 的 SDK 對于一些平臺團隊來說,通過編程的方式很容易集成。這里主要介紹命令行工具的使用,上圖右側展示了命令行的使用,類似于 K8S 的 ctl。命令結構為 kyuubi-ctl + action 命令 + batch + yml 文件。其中 action 包括 create、get、logs、delete,分別對應前文提到的 4 個 API,還有一個復合命令 Submit,包含了其它 4 個 action。配置文件中指定了 JAR 的位置,Batch 類型,目前已經支持了 Spark,正在支持 Flink,還有提交 JAR 的主程序和它的參數以及配置。
這樣對于用戶來說非常便捷,只需一行命令就能完成任務的提交,不需要配置很多 Spark 的本地環境,這里會使用最新的 Spark 版本,減少了用戶的維護成本。
2、統一 API 接口和認證機制

在 Kyuubi1.6.0 版本中,統一了 API 接口和認證機制。到 Kyuubi1.6.0 為止提供了 Thrift,Rest、JDBC 和 ODBC 的 API,提供了 Kerberos 和 Password 的認證機制,在之前的版本中,對于 Thrift 協議來說,只支持一種認證機制,在 1.6.0 版本中,兩種認證機制都支持了。對于 rest 請求 1.6.0 之前是不支持認證的,在 1.6.0 版本中,這兩種認證機制也都做了支持。有了統一的 API 和認證機制,1.6.0 基本上覆蓋了用戶所有的使用方式。
二、客戶端增強
剛剛介紹的是 1.6.0 服務端的增強,在這個版本中對客戶端也做了增強。
1、增強內置 JDBC 驅動能力
增強了內置 JDBC 的驅動能力:
① 剝離了 Hive 和 Hadoop 的依賴;
② 支持使用 keytab 進行 Kerberos 身份認證。
2、增強 Beeline

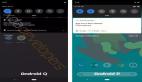
1.6.0 版本增強了 Beeline,在 Beeline 中可以顯示 Spark 控制臺的進度條,如圖所示,可以清楚地看到 Spark 每個 Stage 的執行情況和總體執行情況。
三、引擎插件
在計算引擎方面,Kyuubi1.6.0 提供了非常成熟穩定的 Spark 支持,同時 Flink、trino 以及 Hive 等計算引擎的支持也得到了充分的驗證。
1、Kyuubi Spark Engine

我們首先來看 Spark 引擎。Kyuubi 作為 Spark 的引擎,支持的已經是非常成熟了,有一套完善的生命周期管控,也經過了很多公司的大規模生產驗證,在業界有眾多的生產環境的落地案例。對于版本支持這塊,Kyuubi Spark Engine 支持了 3.0 到 3.3 的所有版本,對于這些版本也都進行了充分的驗證。在 Spark 引擎中兼容了所有的部署模式,比如 Spark on Local/Standalone 或者 Spark on Yarn/K8S,不論是 Client 還是 Cluster mode 都是支持的。
Kyuubi Spark Engine 從 Spark3.1 版本開始就提供了一個企業級插件,比如自動小文件合并,限制掃描的最大分區數,以及限制查詢結果大小,并提供了一個開箱即用的 Z-Order 優化來支持計算寫入 Stage 的配置隔離。同時在 1.6.0 中,又新增了 Spark TPC-DS 和 TPC-H 連接器,以及 Authz 認證的插件。
Kyuubi 社區依然還在陸續開發一些比如像血緣插件等企業級的功能。
2、Kyuubi Flink Engine

再來看一下 Flink Engine,在 Kyuubi1.6.0 中基本成熟穩定了,并且 Kyuubi 的 Flink Engine 是對所有社區開發者和用戶去關注的,也在不斷的迭代演進中,在 1.6.0 版本中,Flink Engine 支持了 Flink1.14、1.15 版本,1.16 還沒有發布,社區這邊已經在逐步支持。
對于部署模式而言,Flink Engine 支持 on Local、on Yarn(PerJob and Session mode),關于 on Yarn/K8S Application mode 會在 1.7.0 版本進行發布,因為 Application mode 非常契合 Kyuubi 的部署模式,目前是在開發階段。
3、Kyuubi Trino Engine, Kyuubi Hive/JDBC Engine

Trino Engine 是一個生產可用,經過移動云等社區用戶的生產驗證狀態。Hive 和 JDBC Engine 提供了一個 Beta 版本,歡迎大家使用反饋,以及生產驗證。