DetectGPT:使用概率曲率的零樣本機器生成文本檢測
DetectGPT的目的是確定一段文本是否由特定的llm生成,例如GPT-3。為了對段落 x 進行分類,DetectGPT 首先使用通用的預訓練模型(例如 T5)對段落 ~xi 生成較小的擾動。然后DetectGPT將原始樣本x的對數概率與每個擾動樣本~xi進行比較。如果平均對數比高,則樣本可能來自源模型。

ChatGPT是一個熱門話題。人們正在討論是否可以檢測到一篇文章是由大型語言模型(LLM)生成的。DetectGPT定義了一種新的基于曲率的準則,用于判斷是否從給定的LLM生成。DetectGPT不需要訓練單獨的分類器,不需要收集真實或生成的段落的數據集,也不需要顯式地為生成的文本加水印。它只使用由感興趣的模型計算的對數概率和來自另一個通用預訓練語言模型(例如T5)的文章隨機擾動。
1、DetectGPT:隨機排列和假設

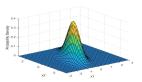
識別并利用了機器生成的通道x~pθ(左)位于logp (x)的負曲率區域的趨勢,其中附近的樣本平均具有較低的模型對數概率。相比之下,人類書寫的文本x~preal(.)(右)傾向于不占據具有明顯負對數概率曲率的區域。
DetectGPT基于一個假設,即來自源模型pθ的樣本通常位于pθ對數概率函數的負曲率區域,這是人類文本不同的。如果我們對一段文本 x~pθ 應用小的擾動,產生 ~x,與人類編寫的文本相比,機器生成的樣本的數量 log pθ(x) - log pθ(~x) 應該相對較大。利用這個假設,首先考慮一個擾動函數 q(.|x),它給出了在 ~x 上的分布,x 的略微修改版本具有相似的含義(通常考慮粗略的段落長度文本 x)。例如,q(.|x) 可能是簡單地要求人類重寫 x 的其中一個句子的結果,同時保留 x 的含義。使用擾動函數的概念,可以定義擾動差異 d (x; pθ, q):
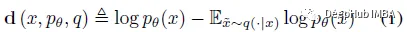
因此,下面的假設 4.1也就是:

如果q(.|x)是來自掩碼填充模型(如T5)的樣本而不是人類重寫,那么假設4.1可以以自動的、可擴展的方式進行經驗檢驗。
2、DetectGPT:自動測試
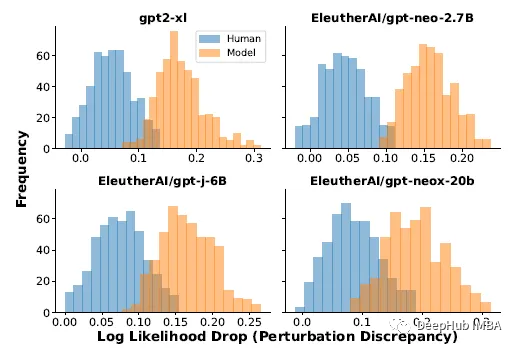
對一篇文章進行改寫后,模型生成的文章的對數概率(擾動差異)的平均下降始終高于人工書寫的文章
對于真實數據,使用了XSum數據集中的500篇新聞文章。當提示XSum中每篇文章的前30個令牌時,使用四個不同llm的輸出。使用T5-3B施加擾動,遮蔽隨機采樣的2個單詞跨度,直到文章中15%的單詞被掩蓋。上面公式(1)中的期望近似于T5中的100個樣本。
上述實驗結果表明,人寫文章和模型樣本的攝動差異分布有顯著差異;模型樣本往往有較大的擾動差異。根據這些結果,就可以通過簡單地閾值擾動差異來檢測一段文本是否由模型p生成。
通過用于估計 E~x q(.|x) log p (~x) 的觀測值的標準偏差對擾動差異進行歸一化提供了更好的檢測,通常將 AUROC 增加 0.020 左右, 所以在實驗中使用了擾動差異的歸一化版本。

DetectGPT 的檢測過程偽代碼
擾動差異可能是有用的,它測量的是什么還無法明確解釋,所以作者在下一節中使用曲率進行解釋。
3、將微擾差異解釋為曲率
擾動差異近似于候選段落附近對數概率函數局部曲率的度量,更具體地說,它與對數概率函數的 Hessian 矩陣的負跡成正比。
這一節內容比較多,這里就不詳細解釋了,有興趣的可以看看原論文,大概總結如下:
語義空間中的采樣確保所有樣本都保持在數據流形附近,因為如果隨機添加擾動標記,預計對數概率總是下降。所以可以將目標解釋為近似限制在數據流形上的曲率。
4、結果展示
零樣本機器生成文本檢測

每個實驗使用150到500個例子進行評估。機器生成的文本是通過提示真實文本的前30個標記來生成的。使用AUROC)評估性能。
可以看到DetectGPT最大程度地提高了XSum故事的平均檢測精度(AUROC提高0.1 )和SQuAD維基百科上下文(AUROC提高0.05 )。
對于15種數據集和模型組合中的14種,DetectGPT提供了最準確的檢測性能,AUROC平均提高了0.06。
與有監督檢測器的比較

在真實文本和生成文本的大型數據集上訓練的有監督的機器生成文本檢測模型在分布內(頂部行)文本上的表現與DetectGPT一樣好,甚至更好。零樣本方法適用于新域(底部一行),如PubMed醫學文本和WMT16中的德語新聞數據。
來自每個數據集的200個樣本進行評估,監督檢測器對英語新聞等分布內數據的檢測性能與DetectGPT相似,但在英語科學寫作的情況下,其表現明顯差于零樣本方法,而在德語寫作中則完全失敗。

DetectGPT檢測GPT-3的平均AUROC與專門為機器生成文本檢測訓練的監督模型相當。
從PubMedQA、XSum和writingprompt數據集中抽取了150個示例。將兩種預訓練的基于roberta的檢測器模型與DetectGPT和概率閾值基線進行了比較。DetectGPT 可以提供與更強大的監督模型競爭的檢測。
機器生成文本檢測的變體

這部分是看檢測器是否可以檢測到人工編輯的機器生成文本。通過用 T5–3B 中的樣本替換文本的 5 個單詞跨度來模擬人工修訂,直到 r% 的文本被替換。即使模型樣本中近四分之一的文本已被替換,DetectGPT 仍能將檢測 AUROC 保持在 0.8 以上。DetectGPT 顯示了所有修訂級別的最強檢測性能。