大語(yǔ)言模型的 few-shot 或許會(huì)改變機(jī)器翻譯的范式

近期 NLP 界的大語(yǔ)言模型 (Large LM) 引領(lǐng)了一波研究熱潮 。有關(guān)大語(yǔ)言模型介紹的博文眾多、此處推薦一下 Stanford 為此專門設(shè)計(jì)的一門課程(僅開源了講義)。
Stanford CS324 - Large Language Modelsstanford-cs324.github.io/winter2022/
大語(yǔ)言模型當(dāng)然也影響到了機(jī)器翻譯領(lǐng)域。近一個(gè)月里 arxiv 上掛出了多篇相關(guān)的論文,而去年一年類似的工作基本都是在 WMT 比賽后作為參賽報(bào)告提交的。由此也可以窺見大語(yǔ)言模型對(duì)機(jī)器翻譯的沖擊。
這幾篇論文展示的一些結(jié)果很有啟發(fā),尤其是本次 Google 發(fā)表的論文很有在未來改變機(jī)器翻譯訓(xùn)練范式的潛質(zhì)——盡管筆者認(rèn)為論文的實(shí)驗(yàn)分析存在一些瑕疵,我也贊同論文標(biāo)題對(duì)他們?cè)?few-shot 機(jī)器翻譯上效果的形容:unreasonable。
接下來筆者將針對(duì)論文進(jìn)行簡(jiǎn)單介紹及評(píng)價(jià)。
The unreasonable effectiveness of few-shot learning for machine translation
機(jī)構(gòu):Google AI
鏈接:https://arxiv.org/pdf/2302.01398.pdf
本文的效果非常驚艷。作者聲稱只使用 decoder-only 的模型(類似PaLM) [https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html] 、中量級(jí)的單語(yǔ)數(shù)據(jù)做訓(xùn)練,再在infer時(shí)加上五組雙語(yǔ)對(duì),就能讓 few-shot 機(jī)器翻譯的結(jié)果追平甚至超過 WMT’21 競(jìng)賽的優(yōu)勝模型。
訓(xùn)練方法
作者使用了深度為 32 層、寬度為 4096 hidden+16384 的 FFW 大型 decoder-only Transformer 就在 100M 級(jí)別的單語(yǔ)語(yǔ)料上進(jìn)行訓(xùn)練、模型參數(shù)量在 8B 左右。各語(yǔ)種的數(shù)據(jù)量見下表

作者使用的單語(yǔ)語(yǔ)料數(shù)量級(jí)并不算大
由于采用了decoder-only的架構(gòu),作者使用了UL2的訓(xùn)練方法[https://arxiv.org/abs/2205.05131]。簡(jiǎn)言之,這種方法和 BERT 的 mask recover 自監(jiān)督預(yù)訓(xùn)練很相似,只是添加了更多種類的噪音,并要求模型恢復(fù)被加噪音的token。
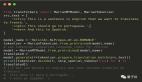
在 infer 階段,作者給定了如下的 prompt 模板來讓模型生成翻譯結(jié)果,其中是從 dev set 中隨機(jī)挑選的 5 個(gè)雙語(yǔ)句子。還需要提及的是 MBR[https://arxiv.org/abs/2111.09388] 作為解碼搜索算法而非 beam search。

prompt 模板中規(guī)中矩
如此簡(jiǎn)單的步驟就完成了模型訓(xùn)練和 infer 的設(shè)置。
實(shí)驗(yàn)效果
作者主要是和 WMT‘21 的前三模型以及自家的 LM 大模型 PaLM 做對(duì)比,所用的指標(biāo)主要是自家的 BLEURT。
下表為大語(yǔ)種翻譯的效果。一個(gè)有趣的點(diǎn)是三語(yǔ)訓(xùn)練的模型效果甚至比雙語(yǔ)的還要好——這一點(diǎn)其實(shí)和以往多語(yǔ)言訓(xùn)練的經(jīng)驗(yàn)有些不同(語(yǔ)種越多、大語(yǔ)種的效果往往越差)。

兩個(gè)大語(yǔ)種的翻譯上,作者的模型追平或超過了往期冠軍、甚至戰(zhàn)勝了自家的 Google Translate 在線服務(wù)。
下表為小語(yǔ)種冰島語(yǔ)的翻譯效果。因?yàn)楸鶏u語(yǔ)較少,作者實(shí)際上是先在英、德單語(yǔ)上預(yù)訓(xùn)練,再在冰島語(yǔ)單語(yǔ)上訓(xùn)練的(作者聲稱這種方法并不影響最終效果、只是為了訓(xùn)練啟動(dòng)更快)。有趣的一點(diǎn)是同為大模型的 PaLM 在小語(yǔ)種上效果很差,而本文的方法反而不錯(cuò)。

小語(yǔ)種的翻譯上不及往期冠軍,但遠(yuǎn)超自家的大語(yǔ)言模型、比肩 Google Translate
此外論文還秀了一些術(shù)語(yǔ)翻譯、風(fēng)格化翻譯的效果。這里僅介紹一個(gè)實(shí)驗(yàn):作者使用了 IWSLT’22 的相關(guān)任務(wù)數(shù)據(jù)集(口語(yǔ)化翻譯和書面語(yǔ)化翻譯)。prompt 模板中填入的 dev set 被證實(shí)可以很好地控制翻譯風(fēng)格:

UMD 是當(dāng)期冠軍。作者的 few-shot 展示了與之匹敵的效果
筆者簡(jiǎn)評(píng)
筆者首先要指出的是,論文的評(píng)測(cè)可能存在一些問題, 值得我們謹(jǐn)慎對(duì)待 :
- 評(píng)估指標(biāo)的問題:作者引用同組內(nèi)的研究
[https://arxiv.org/abs/2211.09102]
, 聲稱 BLEU 這種 n-gram 的指標(biāo)不能良好地衡量大型 LM 生成的結(jié)果,而優(yōu)先使用了 BLEURT。然而,BLEURT 也有許多缺陷:一是 BLEURT 比較對(duì)翻譯流暢度的偏好高于準(zhǔn)確度,而大語(yǔ)言模型擅長(zhǎng)生成好句子、同時(shí) few-shot 模型在翻譯時(shí)經(jīng)常有漏譯的問題,作者們選用 BLEURT 有刻意揚(yáng)長(zhǎng)避短的嫌疑;二是 BLEURT 指標(biāo)和本文模型的訓(xùn)練語(yǔ)料都來自 Google 自家 household 的語(yǔ)料庫(kù),這也許會(huì)造成評(píng)測(cè)上的不準(zhǔn)確(見下文筆者的經(jīng)驗(yàn)談*)。

作者在附錄中低調(diào)地報(bào)告了 BLEU 結(jié)果,比 SOTA 差 10 個(gè)點(diǎn)左右
- 數(shù)據(jù)泄漏問題: WMT 測(cè)試集的領(lǐng)域非常單一、集中在新聞。在 WMT 比賽中官方發(fā)布的訓(xùn)練集一般是前一年的新聞?wù)Z料,而測(cè)試集是最近發(fā)布的新聞,由此避免數(shù)據(jù)泄漏。而本文用到的是網(wǎng)絡(luò)爬取的語(yǔ)料等,如果其中有和測(cè)試集類似的新聞報(bào)道,很有可能模型。盡管作者做了 training set 和 test set 間 token-level 的重疊度分析,但一方面作者用的指標(biāo)相對(duì)寬松、需要有 15 個(gè) token 相同才視為重疊——即便如此重疊度在1%的水平;另一方面,正如作者認(rèn)為 BLEU 這種 token-level 的指標(biāo)不精確一樣,token-level 的重疊度一樣不能很好地衡量領(lǐng)域相似度,詞不相似但領(lǐng)域相似的訓(xùn)練數(shù)據(jù)一樣能帶來在測(cè)試集上的過擬合。

訓(xùn)練集和測(cè)試集的 overlap 衡量。測(cè)試集句子有 15 個(gè) token 與訓(xùn)練集某句相同時(shí),記為一次 overlap
- Scaling 的問題: neural scaling law 及一些大模型的討論工作展示了大語(yǔ)料+大模型能大幅提升 NLP 效果。作為 Google 的研究團(tuán)隊(duì),作者們肯定不缺乏數(shù)據(jù),然而論文只探索了 100M 級(jí)別的訓(xùn)練效果。我們應(yīng)當(dāng)思考,論文的方法在更大數(shù)據(jù)下的性能是否也會(huì)按照 scaling law 那樣增長(zhǎng)?筆者認(rèn)為作者們有做加數(shù)據(jù)的實(shí)驗(yàn),但可能性能的提升效果不如預(yù)期。
*筆者在工作中也經(jīng)常比較各大公司的翻譯效果。在幾家競(jìng)品翻譯人工評(píng)估結(jié)果相似的情況下,BLEURT 最偏好 Google Translate 的結(jié)果,有可能是兩者用了相同的訓(xùn)練數(shù)據(jù)。
*按照之前筆者參與 WMT 比賽的經(jīng)驗(yàn),有一個(gè)常見的競(jìng)賽的 trick 是在往期的 dev set 上做微量精調(diào)[https://aclanthology.org/W19-5341.pdf], 此法可以小幅度提升 BLEU 值( 1-3 BLEU),這是因?yàn)?WMT 對(duì) dev/test set 的譯文風(fēng)格有著較強(qiáng)的一致性控制。筆者按照本文的方法測(cè)量了往期 en-de 的 dev/test set 的 15 token 重合度,都不超過 0.3%,側(cè)面說明作者的 overlap 指標(biāo)有缺陷。此外,德語(yǔ)、冰島語(yǔ)作為屈折語(yǔ),同個(gè)單詞的詞形變化非常地豐富,不清楚作者算 overlap 時(shí)有沒有對(duì)單詞做 stemming。
但即便論文實(shí)驗(yàn)上有缺陷、行文也多少有些 overclaim,筆者認(rèn)為這篇論文足夠驚艷。
其一,作者的這一套方法幾乎不依賴雙語(yǔ)數(shù)據(jù)、對(duì)單語(yǔ)數(shù)據(jù)的要求也很少,唯一的門檻在于模型較大 (8 B)。然而在可見的未來,大語(yǔ)言模型作為大勢(shì)所趨,這個(gè)量級(jí)的模型的部署和訓(xùn)練也會(huì)越來越容易、也會(huì)有更多類似 BLOOM 的開源。即便作者的方法不能完全打敗傳統(tǒng)雙語(yǔ)訓(xùn)練的模型,也極大地降低了機(jī)器翻譯模型的門檻,尤其是數(shù)據(jù)門檻。
其二,作者的方法對(duì)于小語(yǔ)種翻譯模型的訓(xùn)練范式(尤其是無監(jiān)督機(jī)器翻譯)可以說是降維打擊。
其三,則是告訴我們大規(guī)模語(yǔ)言模型還有很多神奇性質(zhì)。之前的 seq2seq 范式下,單語(yǔ) pretrain +雙語(yǔ) few-shot 的效果并不好,很多時(shí)候得要用 Back-translation 等才能達(dá)到合格的水平。而本文通過把模型加大就直接解決了該類問題。Large LM 的潛力比我們預(yù)想的強(qiáng)。
此外還有一小點(diǎn):風(fēng)格化翻譯、術(shù)語(yǔ)翻譯、特定領(lǐng)域是上一代機(jī)器翻譯沒有很好解決的問題,本篇論文給了一些 prompt 上的經(jīng)驗(yàn)參考,可以說是給了一種低開銷的 prompt 方案(考慮到近期 NLP 社區(qū)也都在用 prompt 和 context learning 的方法來做這些任務(wù)了,沒有這篇論文,這類問題的技術(shù)路徑也是大體確定的)