網易郵箱數倉演進之路
本文介紹了網易郵箱數倉的演進過程和期間一些關鍵的技術方案引入決策,并闡述了這些決策背后的業務需求和技術考慮因素,以及實施后的實際產出成效。最后對整個過程進行了總結及后續展望。
1、概述
到目前為止,網易郵箱數倉的發展大致經歷了三個階段:

第一個階段是2020年10月份之前,這時候我們的數據系統的主要任務是支持郵箱日常的運營統計;
第二個階段大概是2020年11月份到2021年的11月份,這段期間公司嘗試做業務的調整,挖掘新的長期增長方向。我們在這時候對郵箱數倉底層的OLAP引擎和整個數據處理鏈路都進行了重構,以適應業務方寬泛的即席數據探索需求;
第三個階段大概是2021年的12月份到現在,我們進入了精細化運營探索期。這個時期我們的主要工作是完善數倉結構,滿足更多、更深入的數據應用需求。
可以看到,由于每個時期面臨的主要問題不同,前兩個階段切換的主題在于重建基礎設施,而后兩個階段切換的主題則是完善上層建筑。
2、初始狀態
早期的網易郵箱數倉底層是一套完整的Hadoop體系結構,它的組件構成比較龐雜。但后期它完成的主要任務就是從貼源層計算統計結果到應用層,用作BI報表展示。

有一組數據能夠反映2020年10月份之前這個系統的狀態:整個集群大概有300個節點,存了9P+的數據,其中小文件眾多,導致元數據條目有6億+,這個元數據規模讓HDFS的NameNode不堪重負,2次崩潰。其中第二次崩潰導致郵箱所有的數據統計任務停了整整1周多的時間,這也是導致我們下決心后續對數倉進行升級改造的直接原因。
然而我們當時只有兩名數據開發人員,并且沒有專職的大數據運維人員。因此,從資源的角度看,我們實際上也是沒有條件繼續支撐這套體系持續穩定運轉的,一次徹底的底層重構勢在必行。
根據當時的情況,重構方案在技術層面需要下面考慮三點:
- 開發效率:因為開發人員少,而基于MR框架的開發效率比較低,我們需要一個使用成本更低、效率更高的開發平臺;
- 系統性能:老系統的任務執行效率較低(尤其是邏輯較復雜的長周期統計任務),新方案應該要在大規模數據集下有更好的查詢性能;
- 運維效率:因為缺少專職的數據運維,我們需要架構相對簡單,維護難度相對低的技術選型。
另外,在業務層面,當時我們的產品和運營側都還在新方向探索期,對業務指標間的關聯性了解不足,沒有形成穩定的觀察指標體系。具體的癥狀就是這兩個:
- “不知道要什么”:當你問業務方:“最想要看哪些指標?”,結果通常都是說不上來,不知道哪些指標和用戶、會員等核心指標的提升關聯度大;
- “什么都要”:當業務方提需求的時候就是:什么都要。各種業務過程的不同維度、不同粒度下的指標都要看。
如果在這個時期就去構建完整的多層數倉結構,預先做好多維度的聚合指標,很容易變成無用功,最后要推倒重來。實際上業務側這時候最需要的是在明細事實數據層面的高性能的ad-hoc查詢能力,并且最好更夠支持他們進行自助的數據探索。
3、數倉1.0
于是經過綜合考慮,我們從2020年底到2021年中逐步做了下面幾個工作:
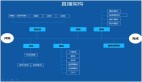
- 第一個是將舊Hadoop集群的數據進行壓縮、清理后,遷移到新搭建的猛犸Hadoop集群(規模小了很多),成為新數倉的ODS層,向上層提供原始數據輸入;
- 第二個是選型、引入了以數據查詢和寫入性能著稱的OLAP引擎ClickHouse(下文簡稱CK),作為新數倉的DWD層,支持應用側以SQL的形式查詢、挖掘事實數據;
- 第三個是基于Kafka和Flink搭建了一套新的、支持實時數據采集的數據處理鏈路,為CK輸入清洗后的事實數據。

這套框架搭建完之后帶來下面幾個方面的好處:
(1)在開發層面
- 統一用SQL進行數據需求的開發,降低了開發難度,也便于形成統一的開發規范;
- 降低了業務側自助查詢的門檻,讓運營、QA、前后端開發等職能可以自己實現數據統計任務和報表產出,相當于增加了數據開發的人力(這點對我們來說很重要,它讓我們能夠在人力資源這么緊張的情況下,還能騰出手來,在數倉的外延去補充數據中臺的一些能力);
- 實現了高效的數據接入流程。
(2)在業務提效層面
- CK具有很高的單表查詢和寫入性能,提升了數據需求實現的效率;
- 依靠強大的基礎性能,CK可以覆蓋從T+1的運營統計到準實時的服務質量基線統計需求。
(3)在運維層面
- 盡管CK自身也有在擴容等方面的維護難點,但整體上相比Hadoop技術棧的組件要少,部署結構相對簡單;
- 另外CK在數據壓縮后仍能維持較好的查詢性能,有助于我們控制存儲規模。
在新數倉上線后,我們取得了比較顯著的業務和技術成效。比如在業務支撐方面,業務側自助取數占比從0提升到了80%以上,平均取數時長從天級縮短至分鐘級,當時的業務指標覆蓋度也有了質的提升;在開發層面,統計任務的開發效率、數據查詢性能和數據接入效率都成倍地提升;而在運維層面,我們用比之前更少的服務器資源支撐了更高的數據吞吐量,同時系統可用性還得到了提升。
看上去我們已經很好地支撐了當時的業務需求,為什么還要繼續折騰呢?

因為業務會成長。隨著各項運營目標的推進,大家總算是形成了一些相對穩定的業務觀察指標了,但觀察了一段時間之后的結論就是:很多關鍵業務指標的增長都出現了瓶頸。而同時在降本增效的趨勢下,運營觸達行為的轉化率要求也提升了。
實際上是業務增長現在需要更精細化的運營策略了,而這時候我們的系統能力就逐漸和新的需求演化趨勢之間產生了一些失配:
- 首先是深挖業務增長因素的多維度分析場景增多了,而CK的Join性能優化較弱,或者說對于業務側同學和數據分析師來說,要寫出高效的關聯查詢SQL的門檻比較高,所以應用復雜的維度建模方法的難度較大(如果都打成CK喜歡的大寬表的模式的話,數據表的復用度低,重復開發量大,數據變更的影響也大);
- 第二個是運營策略越來越依賴用戶、設備等維度的標簽,而標簽(尤其是統計數值類標簽)是容易發生變更的,而CK對數據熱更新的支持不完善,會增加標簽維護的成本;
- 第三個是隨著更多數據應用的出現,分析查詢的頻次提升了,對數倉的并發請求增多,但CK的并發查詢支撐能力不強。
所以我們需要對系統進行進一步的能力提升。但從資源、成本以及需求時效性的角度考慮,去改造CK或者等它升級提供所需要的能力和特性顯然都不現實。
為了能夠在不大規模地改變現有架構的前提下,快速地補充缺失的能力,我們考慮新引入一個能滿足這些能力要求的OLAP引擎,并讓它主要工作在DWM層,用來承載輕度聚合數據、標簽及其他維表,并支撐業務的多維度分析需求。

在這個新數倉的選型上,我們對比了業界多個優秀的OLAP引擎,其中有基于Hadoop生態的方案,也有采用獨立研發的存算系統的方案。最終考慮到StarRocks在與現有系統的整合難度、關聯查詢優化、數據更新支持、并發查詢能力和運維成本等方面的均衡表現,決定選擇它作為新的選型。
StarRocks實際上是與Doris同源的另外一個開源分支。這背后其實還隱含了另外一個選型因素,就是我們和StarRocks的技術團隊在很早之前就建立了聯系,他們也在我們的實踐過程中提供了很好的技術支持。
4、數倉2.0
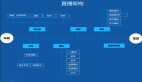
于是從2021年年末起,我們按計劃引入了StarRocks,并調整了數倉的邏輯結構,從而又帶來了一系列提升:

(1)在業務支撐層面
- 可以支持并發度比較高的多維度分析查詢需求;
- 以較小的開發、維護成本滿足了數據應用側的標簽查詢需求。
(2)在開發及架構層面
- 我們讓CK和StarRocks工作在了各自擅長的層次。在數據規模比較大的細粒度事實層,數據探索依然可以依賴CK的大寬表模式;而在中間層的開發中我們也能充分利用StarRocks的自動聚合、智能物化視圖等這些特性來提升開發效率;
- 提升通用指標的復用度,減少了重復開發;
- 降低了對明細層數據的查詢壓力。
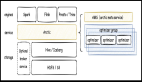
目前,我們StarRocks中存儲了40多個標簽表,數據量達300多億條,日均數據更新7億多次,每天承載的查詢量達到了千萬級(這里包括了一些在線應用的實時請求)。
在業務成效方面,一些特定的用戶標簽讓定向引流觸達活動的點擊率平均提升了90%以上;基于數倉中間層的取數系統和畫像系統上線以來,累計節省了約10人月的數據開發人力投入;同時標簽庫也支撐了風控因子庫和個性化反垃圾模型的構建。
5、總結

如果用一句話來總結到目前為止的數倉建設過程,那就是:“雖然起步晚,但幾乎總是在關鍵的業務發展節點前補充了與之匹配的能力”。我們從中得到的感觸主要有兩點:
首先是數據團隊應該時刻關注業務的運營狀態和數據的產出價值。這是我們跟上業務的發展節奏甚至推動它前進的前提,同時也體現了一種價值取向:就是技術團隊的最終產出價值通常不是技術本身,我們的技術活動的終極目標通常也不是技術先進性,而是讓業務在殘酷的市場競爭中獲得生存優勢;
其次是數倉建設無法一蹴而就。因為業務需求的演進需要一個過程,而方案的實施又有各種資源和成本上的限制,所以不可能也沒有必要從一開始就考慮實現一個大而全的系統。更好的方式可能是提前預判需求的演變趨勢,用來做長期的建設規劃,但按中短期的能力要求循序漸進地推進。
6、展望
展望未來,郵箱業務會持續發展,甚至會嘗試突破業務的領域邊界。預計會有更多針對特定領域的數據應用出現。這些應用實際上是把調用數倉算力的門檻降低了,會給數據支撐工作帶來更大的壓力。
為此我們計劃做好以下幾件事情:
- 為了保持數倉系統的健康度,需要完善數據中臺的數據治理能力,尤其是通過數據價值評估和數據生命周期管理,有效地控制數倉的熱存儲中的數據規模;
- 為了在降本增效的前提下應對不斷提升的應用算力需求,需要提升數倉系統的資源利用率和彈性伸縮能力,因此考慮引入OLAP引擎層面的存算分離和資源隔離機制;
- 為了應對業務領域拓展可能會帶來的不同的數據分析模式,還需要考慮湖倉一體和簡化、加速數據湖分析的方案。
本次的分享就到這里,謝謝大家。