緩存數據不一致和并發競爭怎么處理
數據不一致
問題描述
同一份數據,可能會同時存在 DB 和緩存之中。那就有可能發生,DB 和緩存的數據不一致。如果緩存有多個副本,多個緩存副本里的數據也可能會發生不一致現象。
原因分析
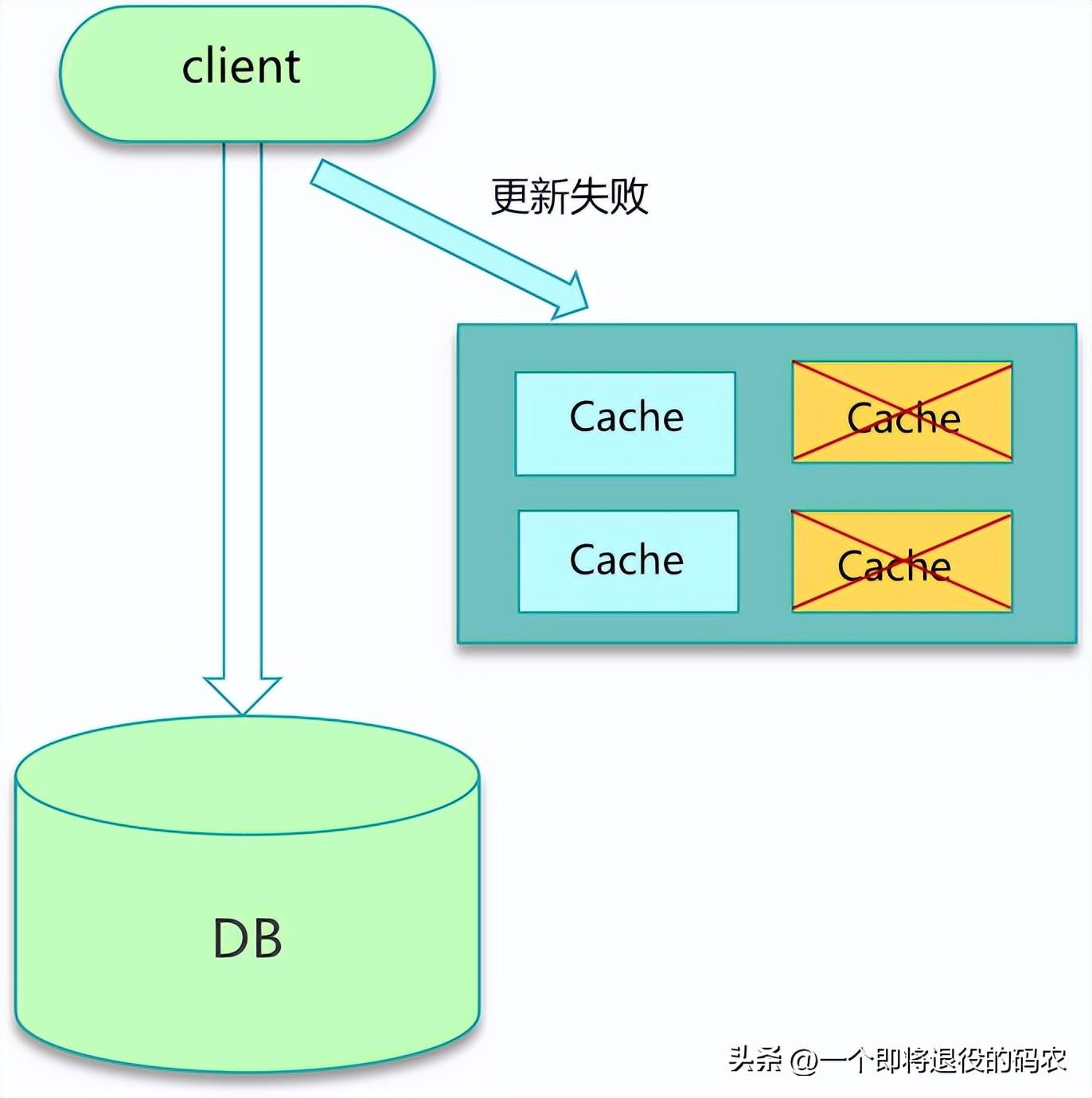
不一致的問題大多跟緩存更新異常有關。比如更新 DB 后,寫緩存失敗,從而導致緩存中存的是老數據。另外,如果系統采用一致性 Hash 分布,同時采用 rehash 自動漂移策略,在節點多次上下線之后,也會產生臟數據。緩存有多個副本時,更新某個副本失敗,也會導致這個副本的數據是老數據。
業務場景
導致數據不一致的場景也不少。如下圖所示,在緩存機器的帶寬被打滿,或者機房網絡出現波動時,緩存更新失敗,新數據沒有寫入緩存,就會導致緩存和 DB 的數據不一致。緩存 rehash 時,某個緩存機器反復異常,多次上下線,更新請求多次 rehash。這樣,一份數據存在多個節點,且每次 rehash 只更新某個節點,導致一些緩存節點產生臟數據。
解決方案
要盡量保證數據的一致性。這里也給出了 3 個方案,可以根據實際情況進行選擇。
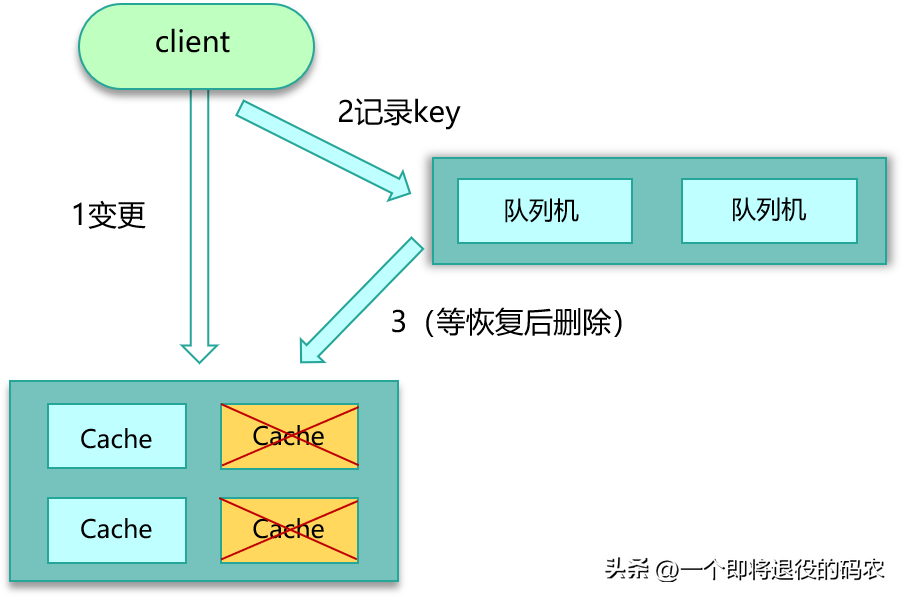
- 第一個方案,cache 更新失敗后,可以進行重試,如果重試失敗,則將失敗的 key 寫入隊列機服務,待緩存訪問恢復后,將這些 key 從緩存刪除。這些 key 在再次被查詢時,重新從 DB 加載,從而保證數據的一致性。
- 第二個方案,緩存時間適當調短,讓緩存數據及早過期后,然后從 DB 重新加載,確保數據的最終一致性。
- 第三個方案,不采用 rehash 漂移策略,而采用緩存分層策略,盡量避免臟數據產生。
數據并發競爭
問題描述
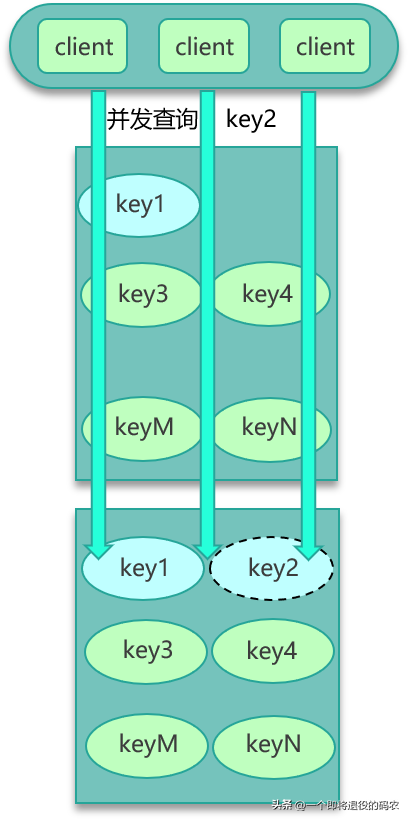
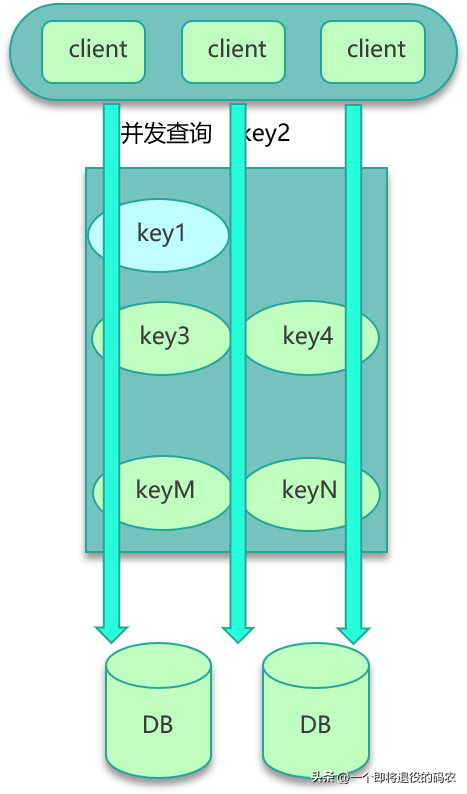
第五個經典問題是數據并發競爭。互聯網系統,線上流量較大,緩存訪問中很容易出現數據并發競爭的現象。數據并發競爭,是指在高并發訪問場景,一旦緩存訪問沒有找到數據,大量請求就會并發查詢 DB,導致 DB 壓力大增的現象。
數據并發競爭,主要是由于多個進程/線程中,有大量并發請求獲取相同的數據,而這個數據 key 因為正好過期、被剔除等各種原因在緩存中不存在,這些進程/線程之間沒有任何協調,然后一起并發查詢 DB,請求那個相同的 key,最終導致 DB 壓力大增,如下圖。
業務場景
數據并發競爭在大流量系統也比較常見,比如車票系統,如果某個火車車次緩存信息過期,但仍然有大量用戶在查詢該車次信息。又比如微博系統中,如果某條微博正好被緩存淘汰,但這條微博仍然有大量的轉發、評論、贊。上述情況都會造成該車次信息、該條微博存在并發競爭讀取的問題。
解決方案
要解決并發競爭,有 2 種方案。
- 方案一是使用全局鎖。如下圖所示,即當緩存請求 miss 后,先嘗試加全局鎖,只有加全局鎖成功的線程,才可以到 DB 去加載數據。其他進程/線程在讀取緩存數據 miss 時,如果發現這個 key 有全局鎖,就進行等待,待之前的線程將數據從 DB 回種到緩存后,再從緩存獲取。
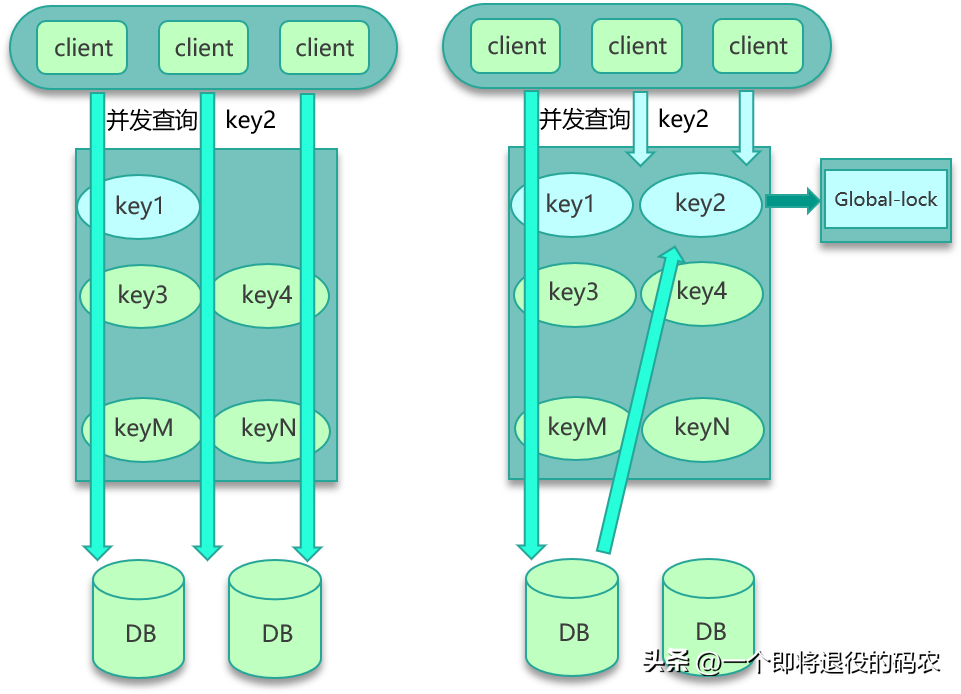
- 方案二是,對緩存數據保持多個備份,即便其中一個備份中的數據過期或被剔除了,還可以訪問其他備份,從而減少數據并發競爭的情況,如下圖。