億級流量高并發下,緩存與數據庫不一致,咋辦?
相信只要是個稍微像樣點的互聯網公司,或多或少都有自己的一套緩存體系。
圖片來自 Pexels
只要用緩存,就可能會涉及到緩存與數據庫雙存儲雙寫,你只要是雙寫,就一定會有數據一致性的問題,遂筆者想在這和大家聊一聊:如何解決一致性問題?
如何保證緩存與數據庫雙寫一致性,也是現在 Java 面試中面試官非常喜歡問的一個問題!
一般來說,如果允許緩存可以稍微跟數據庫偶爾有不一致,也就是說如果你的系統不是嚴格要求緩存+數據庫必須保持一致性的話,最好不要做這個方案。
即:讀請求和寫請求串行化,串到一個內存隊列里去,從而達到防止并發請求導致數據錯亂的問題,場景如圖所示:
值得注意的是,串行化可以保證一定不會出現不一致的情況,但是它也會導致系統的吞吐量大幅度降低,用比正常情況下多幾倍的機器去支撐線上的一個請求(土豪請自覺無視此提醒)。
解決思路如下圖:
代碼實現大致如下:
- /**
- * 請求異步處理的service實現
- * @author Administrator
- *
- */
- @Service("requestAsyncProcessService")
- public class RequestAsyncProcessServiceImpl implements RequestAsyncProcessService {
- @Override
- public void process(Request request) {
- try {
- // 先做讀請求的去重
- RequestQueue requestQueue = RequestQueue.getInstance();
- Map<Integer, Boolean> flagMap = requestQueue.getFlagMap();
- if(request instanceof ProductInventoryDBUpdateRequest) {
- // 如果是一個更新數據庫的請求,那么就將那個productId對應的標識設置為true
- flagMap.put(request.getProductId(), true);
- } else if(request instanceof ProductInventoryCacheRefreshRequest) {
- Boolean flag = flagMap.get(request.getProductId());
- // 如果flag是null
- if(flag == null) {
- flagMap.put(request.getProductId(), false);
- }
- // 如果是緩存刷新的請求,那么就判斷,如果標識不為空,而且是true,就說明之前有一個這個商品的數據庫更新請求
- if(flag != null && flag) {
- flagMap.put(request.getProductId(), false);
- }
- // 如果是緩存刷新的請求,而且發現標識不為空,但是標識是false
- // 說明前面已經有一個數據庫更新請求+一個緩存刷新請求了,大家想一想
- if(flag != null && !flag) {
- // 對于這種讀請求,直接就過濾掉,不要放到后面的內存隊列里面去了
- return;
- }
- }
- // 做請求的路由,根據每個請求的商品id,路由到對應的內存隊列中去
- ArrayBlockingQueue<Request> queue = getRoutingQueue(request.getProductId());
- // 將請求放入對應的隊列中,完成路由操作
- queue.put(request);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- /**
- * 獲取路由到的內存隊列
- * @param productId 商品id
- * @return 內存隊列
- */
- private ArrayBlockingQueue<Request> getRoutingQueue(Integer productId) {
- RequestQueue requestQueue = RequestQueue.getInstance();
- // 先獲取productId的hash值
- String key = String.valueOf(productId);
- int h;
- int hash = (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- // 對hash值取模,將hash值路由到指定的內存隊列中,比如內存隊列大小8
- // 用內存隊列的數量對hash值取模之后,結果一定是在0~7之間
- // 所以任何一個商品id都會被固定路由到同樣的一個內存隊列中去的
- int index = (requestQueue.queueSize() - 1) & hash;
- System.out.println("===========日志===========: 路由內存隊列,商品id=" + productId + ", 隊列索引=" + index);
- return requestQueue.getQueue(index);
- }
- }
Cache Aside Pattern
下面我們來聊聊經典的緩存+數據庫讀寫的模式,就是 Cache Aside Pattern。
讀的時候,先讀緩存,緩存沒有的話,就讀數據庫,然后取出數據后放入緩存,同時返回響應。更新的時候,先更新數據庫,然后再刪除緩存。
為什么是刪除緩存,而不是更新緩存?原因很簡單,很多時候,在復雜點的緩存場景,緩存不單單是數據庫中直接取出來的值。
比如可能更新了某個表的一個字段,然后其對應的緩存,是需要查詢另外兩個表的數據并進行運算,才能計算出緩存最新的值的。
另外更新緩存的代價有時候是很高的,是不是每次修改數據庫的時候,都一定要將其對應的緩存更新一份?
也許有的場景是這樣,但是對于比較復雜的緩存數據計算的場景,就不是這樣了。
如果你頻繁修改一個緩存涉及的多個表,緩存也頻繁更新。但是問題在于,這個緩存到底會不會被頻繁訪問到?
舉個栗子,一個緩存涉及的表的字段,在 1 分鐘內就修改了 20 次,或者是 100 次,那么緩存更新 20 次、100 次。
但是這個緩存在 1 分鐘內只被讀取了 1 次,有大量的冷數據。實際上,如果你只是刪除緩存的話,那么在 1 分鐘內,這個緩存不過就重新計算一次而已,開銷大幅度降低,用到緩存才去算緩存。
其實刪除緩存,而不是更新緩存,就是一個 Lazy 計算的思想,不要每次都重新做復雜的計算,不管它會不會用到,而是讓它到需要被使用的時候再重新計算。
像 Mybatis,Hibernate,都有懶加載思想,查詢一個部門,部門帶了一個員工的 List,沒有必要說每次查詢部門,都把里面的 1000 個員工的數據也同時查出來。
80% 的情況,查這個部門,就只是要訪問這個部門的信息就可以了,先查部門,同時要訪問里面的員工,那么這時只有在你要訪問里面的員工的時候,才會去數據庫里面查詢 1000 個員工。
最初級的緩存不一致問題及解決方案
問題:先修改數據庫,再刪除緩存。如果刪除緩存失敗了,那么會導致數據庫中是新數據,緩存中是舊數據,數據就出現了不一致。
解決思路:先刪除緩存,再修改數據庫。如果數據庫修改失敗了,那么數據庫中是舊數據,緩存中是空的,那么數據不會不一致。
因為讀的時候緩存沒有,則讀數據庫中舊數據,然后更新到緩存中。
比較復雜的數據不一致問題分析
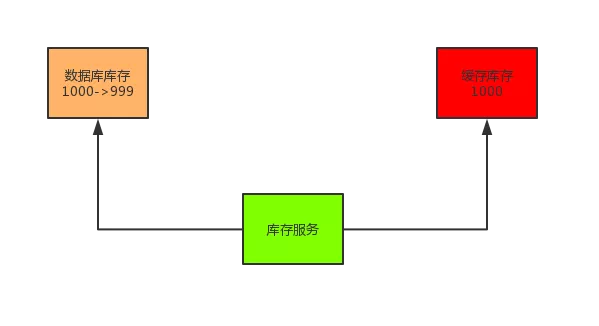
數據發生了變更,先刪除了緩存,然后要去修改數據庫。
但是還沒來得及修改,一個請求過來,去讀緩存,發現緩存空了,去查詢數據庫,查到了修改前的舊數據,放到了緩存中。
隨后數據變更的程序完成了數據庫的修改。完了,數據庫和緩存中的數據不一樣了。
為什么上億流量高并發場景下,緩存會出現這個問題?只有在對一個數據在并發的進行讀寫的時候,才可能會出現這種問題。
如果說你的并發量很低的話,特別是讀并發很低,每天訪問量就 1 萬次,那么很少的情況下,會出現剛才描述的那種不一致的場景。
但是問題是,如果每天的是上億的流量,每秒并發讀是幾萬,每秒只要有數據更新的請求,就可能會出現上述的數據庫+緩存不一致的情況。
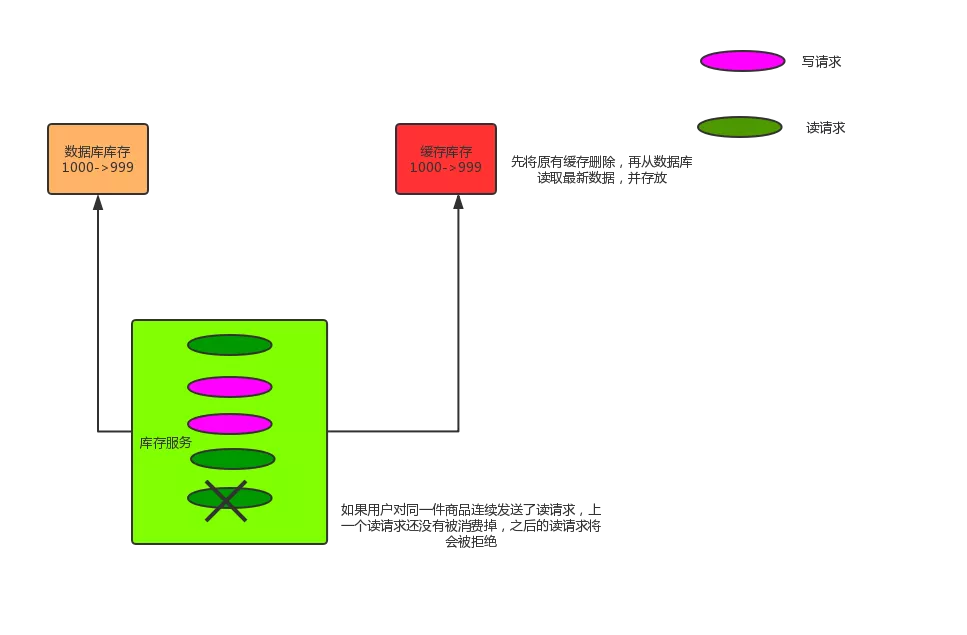
解決方案如下:更新數據的時候,根據數據的唯一標識,將操作路由之后,發送到一個 JVM 內部隊列中。
讀取數據的時候,如果發現數據不在緩存中,那么將重新讀取數據+更新緩存的操作,根據唯一標識路由之后,也發送同一個 JVM 內部隊列中。
一個隊列對應一個工作線程,每個工作線程串行拿到對應的操作,然后一條一條的執行。
這樣的話,一個數據變更的操作,先刪除緩存,然后再去更新數據庫,但是還沒完成更新。
此時如果一個讀請求過來,讀到了空的緩存,那么可以先將緩存更新的請求發送到隊列中,此時會在隊列中積壓,然后同步等待緩存更新完成。
這里有一個優化點,一個隊列中,其實多個更新緩存請求串在一起是沒意義的,因此可以做過濾。
如果發現隊列中已經有一個更新緩存的請求了,那么就不用再放個更新請求操作進去了,直接等待前面的更新操作請求完成即可。
待那個隊列對應的工作線程完成了上一個操作的數據庫的修改之后,才會去執行下一個操作,也就是緩存更新的操作,此時會從數據庫中讀取最新的值,然后寫入緩存中。
如果請求還在等待時間范圍內,不斷輪詢發現可以取到值了,那么就直接返回;如果請求等待的時間超過一定時長,那么這一次直接從數據庫中讀取當前的舊值。
高并發的場景下,該解決方案要注意的問題:
讀請求長時阻塞
由于讀請求進行了非常輕度的異步化,所以一定要注意讀超時的問題,每個讀請求必須在超時時間范圍內返回。
該解決方案,最大的風險點在于,可能數據更新很頻繁,導致隊列中積壓了大量更新操作在里面,然后讀請求會發生大量的超時,最后導致大量的請求直接走數據庫。
所以務必通過一些模擬真實的測試,看看更新數據的頻率是怎樣的。
另外一點,因為一個隊列中,可能會積壓針對多個數據項的更新操作,因此需要根據自己的業務情況進行測試,可能需要部署多個服務,每個服務分攤一些數據的更新操作。
如果一個內存隊列里積壓 100 個商品的庫存修改操作,每個庫存修改操作要耗費 10ms 去完成。
那么最后一個商品的讀請求,可能等待 10*100=1000ms=1s 后,才能得到數據,這個時候就導致讀請求的長時阻塞。
因此,一定要根據實際業務系統的運行情況,去進行一些壓力測試和模擬線上環境,去看看最繁忙的時候,內存隊列可能會積壓多少更新操作,可能會導致最后一個更新操作對應的讀請求,會 Hang 多少時間。
如果讀請求在 200ms 返回,如果你計算過后,哪怕是最繁忙的時候,積壓 10 個更新操作,最多等待 200ms,那還可以的。
如果一個內存隊列中可能積壓的更新操作特別多,那么你就要加機器,讓每個機器上部署的服務實例處理更少的數據,那么每個內存隊列中積壓的更新操作就會越少。
根據之前的項目經驗,一般來說,數據的寫頻率是很低的,因此實際上正常來說,在隊列中積壓的更新操作應該是很少的。
像這種針對讀高并發、讀緩存架構的項目,一般來說寫請求是非常少的,每秒的 QPS 能到幾百就不錯了。
實際粗略測算一下,如果一秒有 500 的寫操作,分成 5 個時間片,每 200ms 就 100 個寫操作,放到 20 個內存隊列中,每個內存隊列,可能就積壓 5 個寫操作。
每個寫操作性能測試后,一般是在 20ms 左右就完成,那么針對每個內存隊列的數據的讀請求,也就最多 Hang 一會兒,200ms 以內肯定能返回了。
經過剛才簡單的測算,我們知道,單機支撐的寫 QPS 在幾百是沒問題的,如果寫 QPS 擴大了 10 倍,那么就擴容機器,擴容 10 倍的機器,每個機器 20 個隊列。
讀請求并發量過高
這里還必須做好壓力測試,確保恰巧碰上上述情況時,還有一個風險,就是突然間大量讀請求會在幾十毫秒的延時 Hang 在服務上,看服務能不能扛的住,需要多少機器才能扛住最大的極限情況的峰值。
但是因為并不是所有的數據都在同一時間更新,緩存也不會同一時間失效,所以每次可能也就是少數數據的緩存失效了,然后那些數據對應的讀請求過來,并發量應該也不會特別大。
多服務實例部署的請求路由
可能這個服務部署了多個實例,那么必須保證說,執行數據更新操作,以及執行緩存更新操作的請求,都通過 Nginx 服務器路由到相同的服務實例上。
比如對同一個商品的讀寫請求,全部路由到同一臺機器上。可以自己去做服務間的按照某個請求參數的 Hash 路由,也可以用 Nginx 的 Hash 路由功能等等。
熱點商品路由問題導致請求傾斜
萬一某個商品的讀寫請求特別高,全部打到相同的機器的相同的隊列里面去了,可能會造成某臺機器的壓力過大。
因為只有在商品數據更新的時候才會清空緩存,然后才會導致讀寫并發,所以要根據業務系統去看,如果更新頻率不是太高的話,這個問題的影響并不是特別大,但是可能某些機器的負載會高一些。