使用馬爾可夫鏈構(gòu)建文本生成器
本文中將介紹一個流行的機器學(xué)習(xí)項目——文本生成器,你將了解如何構(gòu)建文本生成器,并了解如何實現(xiàn)馬爾可夫鏈以實現(xiàn)更快的預(yù)測模型。

文本生成器簡介
文本生成在各個行業(yè)都很受歡迎,特別是在移動、應(yīng)用和數(shù)據(jù)科學(xué)領(lǐng)域。甚至新聞界也使用文本生成來輔助寫作過程。
在日常生活中都會接觸到一些文本生成技術(shù),文本補全、搜索建議,Smart Compose,聊天機器人都是應(yīng)用的例子,
本文將使用馬爾可夫鏈構(gòu)建一個文本生成器。這將是一個基于字符的模型,它接受鏈的前一個字符并生成序列中的下一個字母。
通過使用樣例單詞訓(xùn)練我們的程序,文本生成器將學(xué)習(xí)常見的字符順序模式。然后,文本生成器將把這些模式應(yīng)用到輸入,即一個不完整的單詞,并輸出完成該單詞的概率最高的字符。
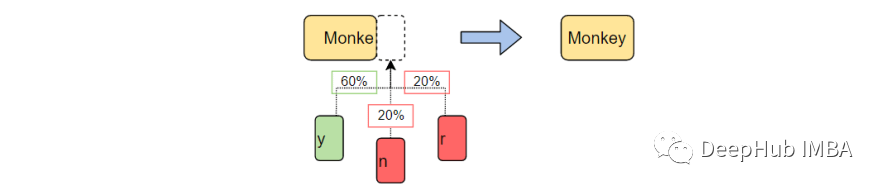
文本生成是自然語言處理的一個分支,它根據(jù)之前觀察到的語言模式預(yù)測并生成下一個字符。
在沒有機器學(xué)習(xí)之前,NLP是通過創(chuàng)建一個包含英語中所有單詞的表,并將傳遞的字符串與現(xiàn)有的單詞匹配來進行文字生成的。這種方法有兩個問題。
- 搜索成千上萬個單詞會非常慢。
- 生成器只能補全它以前見過的單詞。
機器學(xué)習(xí)和深度學(xué)習(xí)的出現(xiàn),使得NLP允許我們大幅減少運行時并增加通用性,因為生成器可以完成它以前從未遇到過的單詞。如果需要NLP可以擴展到預(yù)測單詞、短語或句子!
對于這個項目,我們將專門使用馬爾可夫鏈來完成。馬爾可夫過程是許多涉及書面語言和模擬復(fù)雜分布樣本的自然語言處理項目的基礎(chǔ)。
馬爾可夫過程是非常強大的,以至于它們只需要一個示例文檔就可以用來生成表面上看起來真實的文本。
什么是馬爾可夫鏈?
馬爾可夫鏈?zhǔn)且环N隨機過程,它為一系列事件建模,其中每個事件的概率取決于前一個事件的狀態(tài)。該模型有一組有限的狀態(tài),從一個狀態(tài)移動到另一個狀態(tài)的條件概率是固定的。
每次轉(zhuǎn)移的概率只取決于模型的前一個狀態(tài),而不是事件的整個歷史。
例如,假設(shè)想要構(gòu)建一個馬爾可夫鏈模型來預(yù)測天氣。
在這個模型中我們有兩種狀態(tài),晴天或雨天。如果我們今天一直處于晴朗的狀態(tài),明天就有更高的概率(70%)是晴天。雨也是如此;如果已經(jīng)下過雨,很可能還會繼續(xù)下雨。
但是天氣會改變狀態(tài)是有可能的(30%),所以我們也將其包含在我們的馬爾可夫鏈模型中。
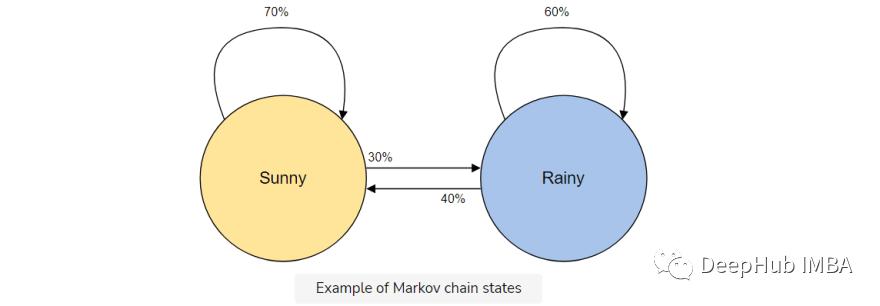
馬爾可夫鏈?zhǔn)俏覀冞@個文本生成器的完美模型,因為我們的模型將僅使用前一個字符預(yù)測下一個字符。使用馬爾可夫鏈的優(yōu)點是,它是準(zhǔn)確的,內(nèi)存少(只存儲1個以前的狀態(tài))并且執(zhí)行速度快。
文本生成的實現(xiàn)
這里將通過6個步驟完成文本生成器:
- 生成查找表:創(chuàng)建表來記錄詞頻
- 將頻率轉(zhuǎn)換為概率:將我們的發(fā)現(xiàn)轉(zhuǎn)換為可用的形式
- 加載數(shù)據(jù)集:加載并利用一個訓(xùn)練集
- 構(gòu)建馬爾可夫鏈:使用概率為每個單詞和字符創(chuàng)建鏈
- 對數(shù)據(jù)進行采樣:創(chuàng)建一個函數(shù)對語料庫的各個部分進行采樣
- 生成文本:測試我們的模型

1、生成查找表
首先,我們將創(chuàng)建一個表,記錄訓(xùn)練語料庫中每個字符狀態(tài)的出現(xiàn)情況。從訓(xùn)練語料庫中保存最后的' K '字符和' K+1 '字符,并將它們保存在一個查找表中。
例如,想象我們的訓(xùn)練語料庫包含,“the man was, they, then, the, the”。那么單詞的出現(xiàn)次數(shù)為:
- “the” — 3
- “then” — 1
- “they” — 1
- “man” — 1
下面是查找表中的結(jié)果:

在上面的例子中,我們?nèi) = 3,表示將一次考慮3個字符,并將下一個字符(K+1)作為輸出字符。在上面的查找表中將單詞(X)作為字符,將輸出字符(Y)作為單個空格(" "),因為第一個the后面沒有單詞了。此外還計算了這個序列在數(shù)據(jù)集中出現(xiàn)的次數(shù),在本例中為3次。
這樣就生成了語料庫中的每個單詞的數(shù)據(jù),也就是生成所有可能的X和Y對。
下面是我們?nèi)绾卧诖a中生成查找表:
代碼的簡單解釋:
在第3行,創(chuàng)建了一個字典,它將存儲X及其對應(yīng)的Y和頻率值。第9行到第17行,檢查X和Y的出現(xiàn)情況,如果查找字典中已經(jīng)有X和Y對,那么只需將其增加1。
2、將頻率轉(zhuǎn)換為概率
一旦我們有了這個表和出現(xiàn)的次數(shù),就可以得到在給定x出現(xiàn)之后出現(xiàn)Y的概率。公式是:
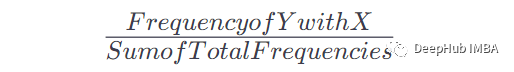
例如如果X = the, Y = n,我們的公式是這樣的:
當(dāng)X =the時Y = n的頻率:2,表中總頻率:8,因此:P = 2/8= 0.125= 12.5%
以下是我們?nèi)绾螒?yīng)用這個公式將查找表轉(zhuǎn)換為馬爾科夫鏈可用的概率:
簡單解釋:
把一個特定鍵的頻率值加起來,然后把這個鍵的每個頻率值除以這個加起來的值,就得到了概率。
3、加載數(shù)據(jù)集
接下來將加載真正的訓(xùn)練語料庫。可以使用任何想要的長文本(.txt)文檔。
為了簡單起見將使用一個政治演講來提供足夠的詞匯來教授我們的模型。
這個數(shù)據(jù)集可以為我們這個樣例的項目提供足夠的事件,從而做出合理準(zhǔn)確的預(yù)測。與所有機器學(xué)習(xí)一樣,更大的訓(xùn)練語料庫將產(chǎn)生更準(zhǔn)確的預(yù)測。
4、建立馬爾可夫鏈
讓我們構(gòu)建馬爾可夫鏈,并將概率與每個字符聯(lián)系起來。這里將使用在第1步和第2步中創(chuàng)建的generateTable()和convertFreqIntoProb()函數(shù)來構(gòu)建馬爾可夫模型。
第1行,創(chuàng)建了一個方法來生成馬爾可夫模型。該方法接受文本語料庫和K值,K值是告訴馬爾可夫模型考慮K個字符并預(yù)測下一個字符的值。第2行,通過向方法generateTable()提供文本語料庫和K來生成查找表,該方法是我們在上一節(jié)中創(chuàng)建的。第3行,使用convertFreqIntoProb()方法將頻率轉(zhuǎn)換為概率值,該方法也是我們在上一課中創(chuàng)建的。
5、文本采樣
創(chuàng)建一個抽樣函數(shù),它使用未完成的單詞(ctx)、第4步中的馬爾可夫鏈模型(模型)和用于形成單詞基的字符數(shù)量(k)。
我們將使用這個函數(shù)對傳遞的上下文進行采樣,并返回下一個可能的字符,并判斷它是正確的字符的概率。
代碼解釋:
函數(shù)sample_next接受三個參數(shù):ctx、model和k的值。
ctx是用來生成一些新文本的文本。但是這里只有ctx中的最后K個字符會被模型用來預(yù)測序列中的下一個字符。例如,我們傳遞common,K = 4,模型用來生成下一個字符的文本是是ommo,因為馬爾可夫模型只使用以前的歷史。
在第 9 行和第 10 行,打印了可能的字符及其概率值,因為這些字符也存在于我們的模型中。我們得到下一個預(yù)測字符為n,其概率為1.0。因為 commo 這個詞在生成下一個字符后更可能是更常見的
在第12行,我們根據(jù)上面討論的概率值返回一個字符。
6、生成文本
最后結(jié)合上述所有函數(shù)來生成一些文本。
結(jié)果如下:
上面的函數(shù)接受三個參數(shù):生成文本的起始詞、K的值以及需要文本的最大字符長度。運行代碼將得到一個以“dear”開頭的2000個字符的文本。
雖然這段講話可能沒有太多意義,但這些詞都是完整的,通常模仿了單詞中熟悉的模式。
接下來要學(xué)什么
這是一個簡單的文本生成項目。通過這個項目可以了解自然語言處理和馬爾可夫鏈實際工作模式,可以在繼續(xù)您的深度學(xué)習(xí)之旅時使用。
本文只是為了介紹馬爾可夫鏈來進行的實驗項目,因為它不會再實際應(yīng)用中起到任何的作用,如果你想獲得更好的文本生成效果,那么請學(xué)習(xí)GPT-3這樣的工具。