













嘉賓 | 竇志成
整理 | 張鋒
策劃 | 徐杰承
搜索引擎自誕生之初到現(xiàn)在已經(jīng)有二十多年,其形式和架構(gòu)一直沒有發(fā)生很大改變。伴隨著互聯(lián)網(wǎng)技術(shù)的持續(xù)發(fā)展,未來的搜索環(huán)境將變得愈加復(fù)雜多樣,用戶獲取信息的方式也會發(fā)生很多的變化,自然語言、語音、視覺等多種輸入形式勢必會取代簡單的關(guān)鍵詞;答案、高階知識、分析結(jié)果、生成內(nèi)容等多種模態(tài)內(nèi)容輸出將取代簡單結(jié)果列表;在交互方式上也可能會從單輪檢索過渡到多輪自然語言交互。
那么在新的搜索的環(huán)境下,未來智能搜索技術(shù)都將會呈現(xiàn)出哪些特征呢?日前,在51CTO主辦的在??AISummit全球人工智能技術(shù)大會??上,中國人民大學(xué)高瓴人工智能學(xué)院副院長竇志成老師通過主題演講——《下一代智能搜索技術(shù)》,為廣大聽眾分享了新一代智能搜索技術(shù)的發(fā)展趨勢及核心特征,同時就交互式、多模態(tài)、可解釋搜索、及以大模型為中心的去索引化搜索等技術(shù)做出了詳盡分析。本文將竇志成老師的演講內(nèi)容進行了編輯整理,希望能給大家?guī)硪恍┬碌膯l(fā):
未來搜索的主要特征
我們認為未來的搜索可能會有至少這五個方面的特征:
- 對話式,人和搜索引擎是通過自然語言進行多輪交互的一種方式。
- 個性化,會根據(jù)不同用戶的需求反饋不同的結(jié)果,而不是千篇一律、千人一面的為所有人反饋相同的結(jié)果。
- 多模態(tài),返回的內(nèi)容和輸入的方式可能不僅僅局限于用文本來作為媒介或者是途徑。
- 富知識,搜索返回的信息不僅僅是一個結(jié)果列表的形式,可能是有各種不同的展示的形式,以各種知識、實體的方式展示。
- 去索引,倒排索引或稠密索引的方式也迫切需要產(chǎn)生很大的變化。
對話式
現(xiàn)在使用的搜索引擎普遍采用的模式是在一個框里面輸入一兩個詞進行搜索。未來的搜索則可能是我們與搜索引擎采用對話的方式進行交互。
在傳統(tǒng)的搜索引擎采用的關(guān)鍵詞檢索方式,我們希望把所有要找的信息核心都通過關(guān)鍵詞描述出來,即我們假設(shè)單個查詢能夠完整、準確地表達這個信息的需求。但在表達一個較為復(fù)雜的信息時,關(guān)鍵詞其實是很難滿足需求的。而對話式搜索可以通過多輪交互來充分表達信息需求,比較符合人和人在交流的時層層遞進的信息交互方式。
想要到達這種交互式搜索,會給系統(tǒng)或算法帶來很大的挑戰(zhàn),需要讓搜索引擎從多輪的自然語言交互中準確理解用戶的意圖,同時也要把理解出的意圖與用戶想要的信息做好匹配。
相比于傳統(tǒng)的關(guān)鍵詞搜索,對話式搜索需要更復(fù)雜的查詢理解(例如需要解決當前查詢中的省略,共指等問題),以還原用戶的真實搜索意圖。最簡單的方式是將歷史查詢?nèi)科唇悠饋恚褂妙A(yù)訓(xùn)練語言模型進行編碼。
簡單的拼接對話方式雖然簡單,但可能會引入噪聲,并不是所有的歷史查詢都對于理解當前查詢是有幫助的,所以我們只選出和它有依賴關(guān)系的上下文,這樣也能解決長度的問題。
對話式檢索模型COTED
基于以上思想,我們提出了對話式稠密檢索的模型COTED,其主要包括如下三部分:
1、通過識別對話查詢中的依賴關(guān)系,來去除對話中的噪聲,進而更好地預(yù)測用戶的意圖。
2、基于對比學(xué)習(xí)的數(shù)據(jù)增強(模仿各種噪聲情況)和去噪損失函數(shù),有效讓模型學(xué)會忽略無關(guān)的上下文,把它和最終匹配的損失函數(shù)聯(lián)合,做多任務(wù)的學(xué)習(xí)。
3、通過課程學(xué)習(xí)的方式來降低模型多任務(wù)學(xué)習(xí)的學(xué)習(xí)難度,最終提升模型性能。
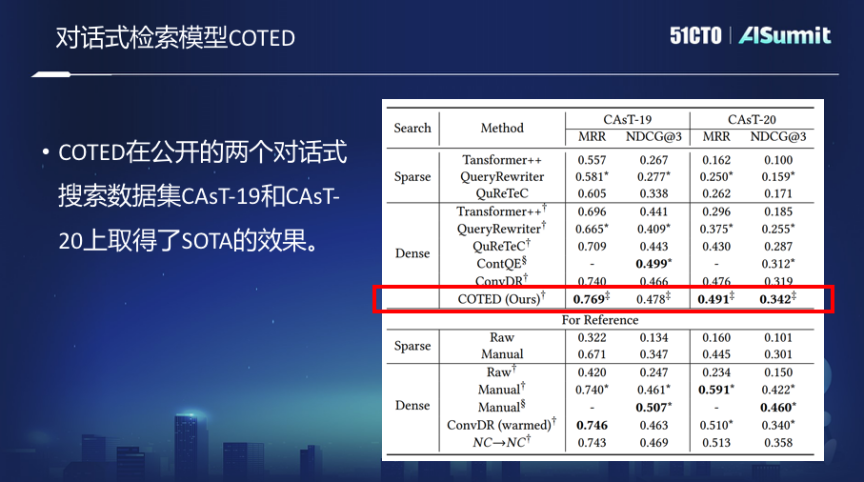
然而,夠用于對話式搜索模型訓(xùn)練的數(shù)據(jù)實際上是非常有限的,在有限的少樣本情況下,對話式搜索的模型訓(xùn)練是非常困難的。
如何解決這個問題?出發(fā)點就是能否把搜索引擎日志遷移去做對話式搜索引擎的訓(xùn)練。在這個思想上,把大規(guī)模的web搜索的日志轉(zhuǎn)換成對話式搜索日志,然后在轉(zhuǎn)換之后的數(shù)據(jù)上訓(xùn)練對話式搜索的模型。但這種方法也同時伴隨著兩個很明顯的問題:
一是傳統(tǒng)的web搜索采用關(guān)鍵詞搜索的方式,對話式搜索是自然語言對話的方式,查詢形式是不一樣的,無法直接遷移使用。二是查詢本身就會存在很多噪聲,需要對搜索日志里面的用戶數(shù)據(jù)做一些清洗、過濾、轉(zhuǎn)換,才能用在對話式搜索里面。
對話式搜索訓(xùn)練模型ConvTrans
為了解決這些問題,我們做了對話式搜索訓(xùn)練模型ConvTrans,并實現(xiàn)了以下功能。
首先,以圖的方式對傳統(tǒng)的web搜索引擎中的日志進行了組織,通過查詢與查詢、查詢與文檔之間建立聯(lián)系構(gòu)建了圖。在圖的基礎(chǔ)上,使用了一個基于T5的兩階段查詢改寫的模型,將一個關(guān)鍵詞的查詢改寫成一個問題的形式。經(jīng)過改寫之后,圖中每個查詢都會用自然語言來表達新的查詢,再設(shè)計一個采樣的算法,從圖上做隨機游走,生成對話的會話,之后基于這個數(shù)據(jù)來訓(xùn)練對話的模型。
實驗顯示,用這種自動生成的訓(xùn)練數(shù)據(jù)來訓(xùn)練的對話式搜索模型,能夠和使用昂貴的人造或者人工標注的數(shù)據(jù)達到同樣的效果,且隨著自動生成的訓(xùn)練數(shù)據(jù)規(guī)模的增大,性能也會持續(xù)提升。這種方法使我們基于大規(guī)模搜索日志進行訓(xùn)練對話式搜索模型成為了可能。

對話式搜索模型雖然在搜索上已經(jīng)走了一大步,但這種對話方式仍然是被動的,搜索引擎一直被動的接受用戶的輸入,根據(jù)輸入來返回結(jié)果,搜索引擎沒有主動地去問用戶你到底要找什么。但在人和人的交流過程中,當你被問一個問題的時候,有時候你會主動地來反問一些問題來做澄清。
比如必應(yīng)搜索里面,如果Query是“Headaches”,頭疼。它會問你“What do want to know about this medical condition”“你想知道關(guān)于這個疾病的什么事”,比如說是它的癥狀、還是治療、還是診斷、還是成因或者誘因。因為Headaches本身是非常寬泛的一個Query,在這種情況下,系統(tǒng)希望能夠進一步澄清你想找到哪里的信息。
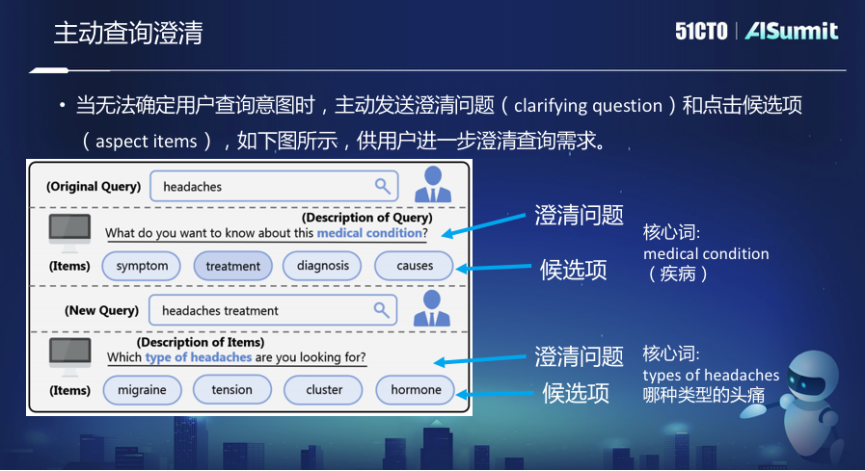
這里面臨兩個問題,第一是候選項,就是想讓用戶去澄清到哪個具體的項。第二是澄清問題,搜索引擎主動反過來問用戶的這個問題。而核心詞是澄清問題里面最至關(guān)重要的一部分。
在這方面的探索,第一是通過查詢?nèi)罩竞椭R庫去給定一個查詢的時候,能夠生成一些澄清的候選項。第二,基于規(guī)則可以通過搜索的結(jié)果來預(yù)測這個澄清問題的一些核心詞。同時也標注一些數(shù)據(jù),通過有監(jiān)督的模型來做這種文本標簽的分類。第三,進一步在這個標注數(shù)據(jù)的基礎(chǔ)上訓(xùn)練端到端的生成模型。
個性化
個性化指的是未來的搜索將以用戶為核心。現(xiàn)在的搜索引擎,不管是誰來查,返回都是同樣的結(jié)果。而這并不能滿足用戶的特定化信息需求。
現(xiàn)在的個性化搜索采用的模式,首先通過用戶歷史學(xué)習(xí)用戶熟悉的知識信息,對查詢進行個性化實體消歧。其次,通過消歧后的查詢實體增強個性化匹配。
此外我們在基于產(chǎn)品品類構(gòu)建用戶的多興趣模型方面也做了探索,假設(shè)用戶可能有自己在所有品類上的一些品牌(規(guī)格、型號)傾向性,但是這個傾向性不能簡單的通過一兩個向量來去刻畫。應(yīng)該根據(jù)用戶購物的歷史,構(gòu)建知識圖譜,通過知識圖譜針對不同品類學(xué)習(xí)不同的興趣,最終做更精準的個性化搜索的結(jié)果推送。
也可以用同樣的個性化方法去做聊天機器人,核心思想就是通過用戶歷史對話,學(xué)習(xí)用戶個性化興趣和語言模式,訓(xùn)練個性化對話模型,可以模仿(代理)用戶說話。
多模態(tài)
現(xiàn)在的搜索引擎在處理多模態(tài)信息的時候,其實有相當多的局限性的。未來用戶獲取的信息可能不僅僅是一些文字、網(wǎng)頁,可能還包括圖片、視頻以及更復(fù)雜的結(jié)構(gòu)信息。所以未來的搜索引擎在多模態(tài)信息獲取上還有很多工作需要做。
現(xiàn)在的搜索引擎在理解或者是做跨模態(tài)檢索時,即給出一個文本的描述,去找它對應(yīng)的圖片的時候,做得還是有很多缺陷的。類似的搜索如果遷移到手機上,局限性就會更大。
所謂的多模態(tài)就是語言、要找的圖像、圖片、視頻等模態(tài),映射到統(tǒng)一的一個空間上,這就意味著可以通過文字去找圖片,圖片去找文字,圖片去找圖片等。
對此,我們做了大規(guī)模多模態(tài)的預(yù)訓(xùn)練模型——文瀾。其重點是基于海量的互聯(lián)網(wǎng)圖片和附近文字的弱監(jiān)督相關(guān)性貢獻的信息訓(xùn)練出來的。采用雙塔模式,最后訓(xùn)練的是一個圖片的編碼器和文本的編碼器,這兩個編碼器通過端到端匹配的優(yōu)化學(xué)習(xí)過程,讓最終的表示向量能夠映射到統(tǒng)一空間中,而不是把圖片的細粒度和文字的細粒度拼接在一起。
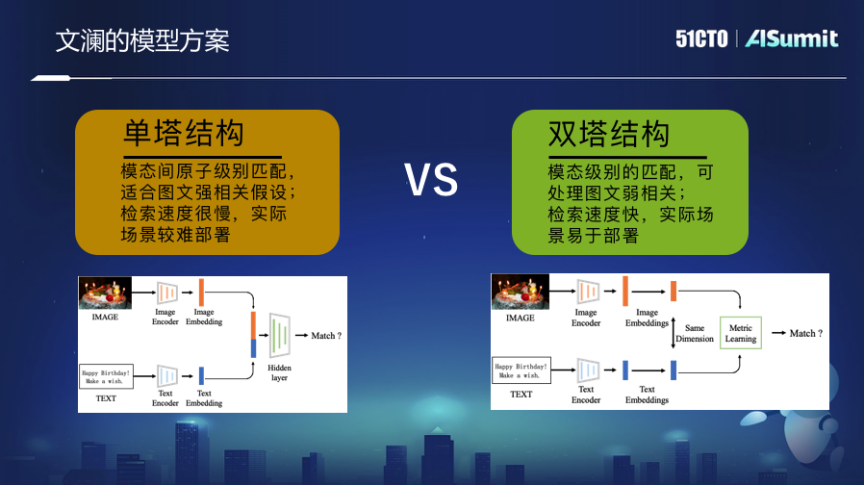
這種跨模態(tài)的檢索能力,其實不只是端到端給用戶使用web搜索引擎時提供了更多的空間,同時也可以支撐很多應(yīng)用,例如創(chuàng)作,不管是社交媒體還是文創(chuàng)類,都可以用它來支撐。
富知識
現(xiàn)在的搜索引擎普遍檢索的主體還是網(wǎng)頁,而未來搜索引擎處理的單元不僅僅是網(wǎng)頁,應(yīng)該是以知識為處理的單位,包括返回的結(jié)果也應(yīng)該是高階的知識,而不是一個一個頁面的列表形式。很多時候用戶其實想通過搜索引擎來完成一些復(fù)雜的信息需求,故而希望搜索引擎幫助分析結(jié)果,而不是讓人來一個一個去分析。
基于此想法我們構(gòu)建了分析引擎,相當于是在搜索引擎的基礎(chǔ)上,能提供深度的文本分析,幫助用戶高效、快捷地獲取高階知識。幫助用戶完成對大規(guī)模文檔的閱讀和理解,并對其中所包含的關(guān)鍵信息和知識進行抽取、挖掘、匯總,最終通過交互式的分析過程,讓用戶對挖掘到的高階知識進行瀏覽和分析,進而為用戶提供決策支持。
例如用戶希望找霧霾相關(guān)的信息,可以直接輸入“霧霾”。富知識模式與傳統(tǒng)的搜索引擎返回的結(jié)果不同,可能返回一個時間軸,告訴用戶關(guān)于霧霾的信息在時間軸上的分布等情況,還會總結(jié)出關(guān)于霧霾的子話題有哪些、機構(gòu)有哪些、人物有哪些。當然它也可以像搜索引擎一樣提供詳細的結(jié)果的列表。

這種可以直接提供分析,而且是交互式分析的能力,能夠更好地幫助用戶獲取復(fù)雜信息的能力。提供給用戶的東西不再是簡單的搜索結(jié)果列表。當然這種交互式的多維知識分析,只是一種展示方式,以后還可以做更多的方式,比如我們現(xiàn)在正在做的一件事情就是從檢索到生成(有理有據(jù)的)內(nèi)容。
去索引
現(xiàn)在的搜索引擎廣泛采用以索引為核心的分階段方式,從大量互聯(lián)網(wǎng)的網(wǎng)頁爬回所需內(nèi)容后構(gòu)建Index,也就是倒排的索引或稠密的向量索引。用戶的Query來之后,先要做召回,在召回的結(jié)果基礎(chǔ)上再做精細化排序。
這個模式有很多弊端,因為要分階段,如果一個階段上出了問題,例如在召回階段沒有找到想要的結(jié)果,它排序階段做得再好,也不可能返回很好的結(jié)果。
在未來的搜索引擎中,這種結(jié)構(gòu)有可能是會被打破的。全新的想法是使用一個大的模型來取代現(xiàn)在的索引的模式,所有的查詢都可以通過模型來滿足。這就不再需要使用索引了,而是直接通過這種模型反饋想要的結(jié)果。
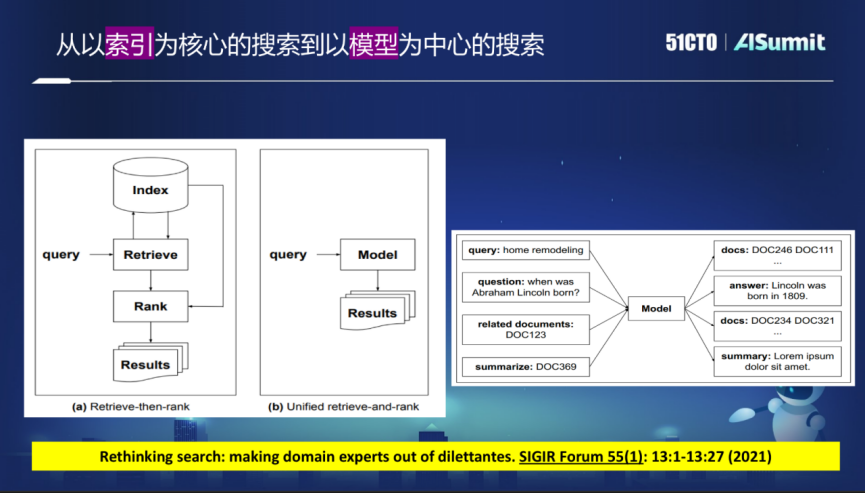
在這個基礎(chǔ)上,可以直接提供結(jié)果列表,也可以直接提供用戶所需的答案,甚至答案還可以是圖像,將各模態(tài)更好的融合在一起。去掉索引,直接通過模型來反饋結(jié)果,就意味著這個模型能夠直接return或者直接返回文檔的標識符,文檔標識符是一定要嵌入到模型中的,構(gòu)建以模型為中心的搜索。
總結(jié)
現(xiàn)在的搜索引擎廣泛采用關(guān)鍵詞為輸入,文檔列表為輸出的這種簡單模式。在滿足人們復(fù)雜信息獲取需求方面,已經(jīng)存在了一些問題。未來的搜索引擎將會是對話式的、是個性化的、是以用戶為中心的、是能夠破除千人一面的。同時能夠處理多模態(tài)的信息,能夠處理知識、能夠返回知識。在架構(gòu)上,未來也一定會突破現(xiàn)有的采用倒排索引或者稠密向量索引的這種以索引為核心的模式,逐步過渡到以模型為核心的模式。
?
嘉賓介紹
竇志成,中國人民大學(xué)高瓴人工智能學(xué)院副院長,北京智源人工智能研究院“智能信息檢索與挖掘”方向項目經(jīng)理。2008加入微軟亞洲研究院,從事互聯(lián)網(wǎng)搜索的相關(guān)工作,培養(yǎng)了豐富的信息檢索技術(shù)研發(fā)經(jīng)驗。2014年開始在中國人民大學(xué)任教,主要研究方向為智能信息檢索和自然語言處理。曾獲國際信息檢索大會(SIGIR 2013)最佳論文提名獎,亞洲信息檢索大會(AIRS 2012)最佳論文獎,全國信息檢索學(xué)術(shù)會議(CCIR 2018、CCIR 2021)最佳論文獎。擔(dān)任SIGIR 2019的程序委員會主席(短文),信息檢索評測會議NTCIR-16程序委員會主席,中國計算機學(xué)會大數(shù)據(jù)專家委員會副秘書長等職務(wù)。近兩年主要關(guān)注個性化和多樣化搜索排序、交互式和對話式搜索模型、面向信息檢索的預(yù)訓(xùn)練方法、搜索和推薦模型的可解釋性、個性化產(chǎn)品搜索等。
















