













面試回答 CopyOnWrite 的三重境界,1%的人能答到最后

今天聊一個非常硬核的技術(shù)知識,給大家分析一下CopyOnWrite思想是什么,以及在Java并發(fā)包中的具體體現(xiàn),包括在Kafka內(nèi)核源碼中是如何運(yùn)用這個思想來優(yōu)化并發(fā)性能的。
這個CopyOnWrite在面試的時候,很可能成為面試官的一個殺手锏把候選人給一擊必殺,也很有可能成為候選人拿下Offer的獨(dú)門秘籍,是相對高級的一個知識。
1、讀多寫少的場景下引發(fā)的問題?
大家可以設(shè)想一下現(xiàn)在我們的內(nèi)存里有一個ArrayList,這個ArrayList默認(rèn)情況下肯定是線程不安全的,要是多個線程并發(fā)讀和寫這個ArrayList可能會有問題。
好,問題來了,我們應(yīng)該怎么讓這個ArrayList變成線程安全的呢?
有一個非常簡單的辦法,對這個ArrayList的訪問都加上線程同步的控制。
比如說一定要在synchronized代碼段來對這個ArrayList進(jìn)行訪問,這樣的話,就能同一時間就讓一個線程來操作它了,或者是用ReadWriteLock讀寫鎖的方式來控制,都可以。
我們假設(shè)就是用ReadWriteLock讀寫鎖的方式來控制對這個ArrayList的訪問。
這樣多個讀請求可以同時執(zhí)行從ArrayList里讀取數(shù)據(jù),但是讀請求和寫請求之間互斥,寫請求和寫請求也是互斥的。
大家看看,代碼大概就是類似下面這樣:
public Object read() {
lock.readLock().lock();
// 對ArrayList讀取
lock.readLock().unlock();
}
public void write() {
lock.writeLock().lock();
// 對ArrayList寫
lock.writeLock().unlock();
}
大家想想,類似上面的代碼有什么問題呢?
最大的問題,其實(shí)就在于寫鎖和讀鎖的互斥。假設(shè)寫操作頻率很低,讀操作頻率很高,是寫少讀多的場景。
那么偶爾執(zhí)行一個寫操作的時候,是不是會加上寫鎖,此時大量的讀操作過來是不是就會被阻塞住,無法執(zhí)行?
這個就是讀寫鎖可能遇到的最大的問題。
2、引入 CopyOnWrite 思想解決問題
這個時候就要引入CopyOnWrite思想來解決問題了。
他的思想就是,不用加什么讀寫鎖,鎖統(tǒng)統(tǒng)給我去掉,有鎖就有問題,有鎖就有互斥,有鎖就可能導(dǎo)致性能低下,你阻塞我的請求,導(dǎo)致我的請求都卡著不能執(zhí)行。
那么他怎么保證多線程并發(fā)的安全性呢?
?很簡單,顧名思義,利用“CopyOnWrite”的方式,這個英語翻譯成中文,大概就是“寫數(shù)據(jù)的時候利用拷貝的副本來執(zhí)行”。
你在讀數(shù)據(jù)的時候,其實(shí)不加鎖也沒關(guān)系,大家左右都是一個讀罷了,互相沒影響。?
問題主要是在寫的時候,寫的時候你既然不能加鎖了,那么就得采用一個策略。
假如說你的ArrayList底層是一個數(shù)組來存放你的列表數(shù)據(jù),那么這時比如你要修改這個數(shù)組里的數(shù)據(jù),你就必須先拷貝這個數(shù)組的一個副本。
然后你可以在這個數(shù)組的副本里寫入你要修改的數(shù)據(jù),但是在這個過程中實(shí)際上你都是在操作一個副本而已。
這樣的話,讀操作是不是可以同時正常的執(zhí)行?這個寫操作對讀操作是沒有任何的影響的吧!
大家看下面的圖,一起來體會一下這個過程:
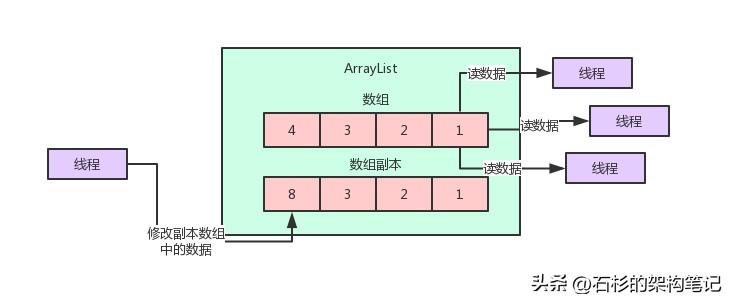
?關(guān)鍵問題來了,那那個寫線程現(xiàn)在把副本數(shù)組給修改完了,現(xiàn)在怎么才能讓讀線程感知到這個變化呢?
關(guān)鍵點(diǎn)來了,劃重點(diǎn)! 這里要配合上volatile關(guān)鍵字的使用。
筆者之前寫過文章,給大家解釋過volatile關(guān)鍵字的使用,核心就是讓一個變量被寫線程給修改之后,立馬讓其他線程可以讀到這個變量引用的最近的值,這就是volatile最核心的作用。
所以一旦寫線程搞定了副本數(shù)組的修改之后,那么就可以用volatile寫的方式,把這個副本數(shù)組賦值給volatile修飾的那個數(shù)組的引用變量了。
只要一賦值給那個volatile修飾的變量,立馬就會對讀線程可見,大家都能看到最新的數(shù)組了。
下面是JDK里的 CopyOnWriteArrayList 的源碼。
大家看看寫數(shù)據(jù)的時候,他是怎么拷貝一個數(shù)組副本,然后修改副本,接著通過volatile變量賦值的方式,把修改好的數(shù)組副本給更新回去,立馬讓其他線程可見的。?
// 這個數(shù)組是核心的,因為用volatile修飾了
// 只要把最新的數(shù)組對他賦值,其他線程立馬可以看到最新的數(shù)組
private transient volatile Object[] array;
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 對數(shù)組拷貝一個副本出來
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 對副本數(shù)組進(jìn)行修改,比如在里面加入一個元素
newElements[len] = e;
// 然后把副本數(shù)組賦值給volatile修飾的變量
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
?然后大家想,因為是通過副本來進(jìn)行更新的,萬一要是多個線程都要同時更新呢?那搞出來多個副本會不會有問題?
當(dāng)然不能多個線程同時更新了,這個時候就是看上面源碼里,加入了lock鎖的機(jī)制,也就是同一時間只有一個線程可以更新。
那么更新的時候,會對讀操作有任何的影響嗎?
絕對不會,因為讀操作就是非常簡單的對那個數(shù)組進(jìn)行讀而已,不涉及任何的鎖。而且只要他更新完畢對volatile修飾的變量賦值,那么讀線程立馬可以看到最新修改后的數(shù)組,這是volatile保證的。?
private E get(Object[] a, int index) {
// 最簡單的對數(shù)組進(jìn)行讀取
return (E) a[index];
}
這樣就完美解決了我們之前說的讀多寫少的問題。
如果用讀寫鎖互斥的話,會導(dǎo)致寫鎖阻塞大量讀操作,影響并發(fā)性能。
但是如果用了CopyOnWriteArrayList,就是用空間換時間,更新的時候基于副本更新,避免鎖,然后最后用volatile變量來賦值保證可見性,更新的時候?qū)ψx線程沒有任何的影響!
3、CopyOnWrite 思想在Kafka源碼中的運(yùn)用
在Kafka的內(nèi)核源碼中,有這么一個場景,客戶端在向Kafka寫數(shù)據(jù)的時候,會把消息先寫入客戶端本地的內(nèi)存緩沖,然后在內(nèi)存緩沖里形成一個Batch之后再一次性發(fā)送到Kafka服務(wù)器上去,這樣有助于提升吞吐量。
話不多說,大家看下圖:
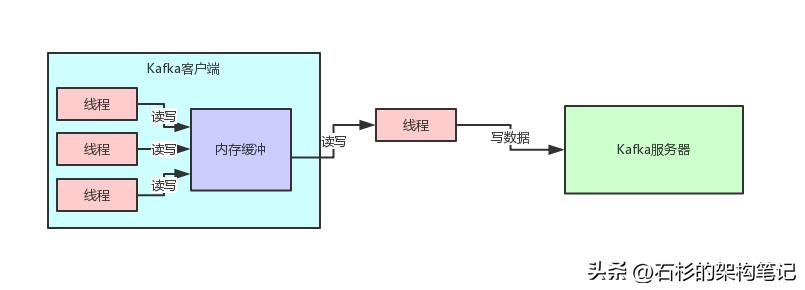
這個時候Kafka的內(nèi)存緩沖用的是什么數(shù)據(jù)結(jié)構(gòu)呢?大家看源碼:
private final ConcurrentMap<topicpartition, deque<="" span="">
batches = new CopyOnWriteMap<TopicPartition, Deque>();
這個數(shù)據(jù)結(jié)構(gòu)就是核心的用來存放寫入內(nèi)存緩沖中的消息的數(shù)據(jù)結(jié)構(gòu),要看懂這個數(shù)據(jù)結(jié)構(gòu)需要對很多Kafka內(nèi)核源碼里的概念進(jìn)行解釋,這里先不展開。
但是大家關(guān)注一點(diǎn),他是自己實(shí)現(xiàn)了一個CopyOnWriteMap,這個CopyOnWriteMap采用的就是CopyOnWrite思想。
我們來看一下這個CopyOnWriteMap的源碼實(shí)現(xiàn):
// 典型的volatile修飾普通Map
private volatile Mapmap;
public synchronized V put(K k, V v) {
// 更新的時候先創(chuàng)建副本,更新副本,然后對volatile變量賦值寫回去
Mapcopy = new HashMap(this.map);
V prev = copy.put(k, v);
this.map = Collections.unmodifiableMap(copy);
return prev;
}
public V get(Object k) {
// 讀取的時候直接讀volatile變量引用的map數(shù)據(jù)結(jié)構(gòu),無需鎖
return map.get(k);
}
所以Kafka這個核心數(shù)據(jù)結(jié)構(gòu)在這里之所以采用CopyOnWriteMap思想來實(shí)現(xiàn),就是因為這個Map的key-value對,其實(shí)沒那么頻繁更新。
也就是TopicPartition-Deque這個key-value對,更新頻率很低。
但是他的get操作卻是高頻的讀取請求,因為會高頻的讀取出來一個TopicPartition對應(yīng)的Deque數(shù)據(jù)結(jié)構(gòu),來對這個隊列進(jìn)行入隊出隊等操作,所以對于這個map而言,高頻的是其get操作。
這個時候,Kafka就采用了CopyOnWrite思想來實(shí)現(xiàn)這個Map,避免更新key-value的時候阻塞住高頻的讀操作,實(shí)現(xiàn)無鎖的效果,優(yōu)化線程并發(fā)的性能。
相信大家看完這個文章,對于CopyOnWrite思想以及適用場景,包括JDK中的實(shí)現(xiàn),以及在Kafka源碼中的運(yùn)用,都有了一個切身的體會了。
如果你能在面試時說清楚這個思想以及他在JDK中的體現(xiàn),并且還能結(jié)合知名的開源項目 Kafka 的底層源碼進(jìn)一步向面試官進(jìn)行闡述,面試官對你的印象肯定大大的加分。

















