主數據系統的設計與實現
1 主數據系統的必要性
隨著企業信息化的不斷深入,企業建設的業務系統、辦公系統等信息系統越來越多。由于規劃、預算、實施計劃等原因限制,各信息系統建設的步調不一致,規劃不統一,導致一個嚴重的問題:一些基礎數據,比如商品編碼、客戶編碼等,在不同信息系統內取值不一致,甚至定義也不一致,為各業務系統打通,以及數據中心建設帶來極大的障礙。這些基礎數據一般稱為主數據,對主數據的規范和梳理需要建設“主數據系統”。
主數據問題主要有幾個方面:
各系統基礎數據定義不一,集中的數據處理(比如 BI、大數據、機器學習等)需要經過繁瑣的數據清洗、格式化、一致性檢查和轉換等步驟,代價巨大;
數據字典各自為政,甚至存在無法調和的邏輯矛盾,比如在 A 系統是主鍵的字段在 B 系統卻允許不唯一;
有時候盡管定義了統一的規范,但各系統獨立維護,也無法保證主數據的一致性。
由此,主數據系統的建設宜早不宜晚,特別是對于已經在使用 ERP 的傳統企業。但是,由于主數據系統偏重于“技術優化”的范疇,很難在業務上見到立竿見影的效果,甚至對于業務人員都是“透明”的,而且還投入不小,所以對于如何申請到資源并立項,是個不小的挑戰。但這不在本文討論的范圍內。
2 主數據系統設計的基本原則
主數據系統的設計方法很多,但大多數都需要對原有信息系統進行傷筋動骨的改動。因此,各企業在主數據系統的實施上都比較保守,寧愿花費大量的人工處理,以及諸多的各系統補丁,進行數據清理和轉換,這種方案效率低而且無法解決根本性問題。
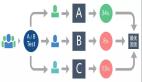
在結構上,由于多個應用系統之間,都可能存在提供數據和使用數據兩種角色,一般采用點對點兩兩交互的網狀結構,這種結構對同步時序、轉換規則、系統復雜度等均提出了極高的要求,也帶來——復雜性高,實施周期長,無法分步實施,容易失敗等問題。

圖 1 網狀結構和星形結構
很顯然,星形結構明顯由于網狀結構,而且必然對原信息系統的修改更少。
主數據系統設計原則幾個要點如下:
- 數據同步從一般的“網狀結構”改為穩定性高的“星形結構”,打破點對點兩兩交叉的復雜結構;
- 通過“數據代理”方式,不侵入原信息系統,不需要對原系統進行大量改動,可以進行有計劃的分步實施;
- 主數據系統對每一條數據記錄,設置全域范圍唯一的 uuid 記錄識別碼,用于主數據記錄全生命周期的識別、映射和轉換;
- 所有數據轉換、映射均由主數據系統實現,對原系統完全“透明”;
- 關聯記錄通過 uuid 多次映射的方式,確保任何現有系統以及將來接入的系統,都無需關心源數據的關聯關系,復雜度大大降低。
3 主數據系統的具體實現
下面結合一種實現方法,給出完整的數據庫設計和流程圖。并對其中的關鍵點進行詳細闡述。該項目已經上線運行半年多,可靠性和數據一致性均經過嚴格驗證。
本項目幾個前提如下:
(1)所有業務系統數據庫都是 MySQL;
(2)所有業務系統數據提供者的主數據表都有 id 主鍵,但字段名不一定為“id”,也不一定具有自增屬性;
(3)所有業務系統數據提供者的主數據表都有最后更新時間戳,同樣字段名各不相同;
(4)所有業務系統數據提供者均以標志位標識“刪除”,而不進行記錄的物理刪除。
3.1 總體架構
總體架構為星形結構,如圖 2:

圖 2 主數據系統總體架構圖
其中:
(1)為簡化設計,基于前提的第 2、3 點,數據代理直接采用數據庫連接方式,定時對數據提供者的數據庫表進行輪詢。由此,對于數據提供者對應主數據表必須具有讀權限,對于數據消費者的對應主數據表必須具有 insert/update 權限;
(2)數據代理(1~n),每個均連接主數據數據庫和唯一一個信息系統數據庫。業務系統數據庫的“數據消費者”和“數據提供者”角色可能只有一種,例如,辦公自動化(OA)系統,可能只作為“數據提供者”角色,提供組織架構、人員等主數據。這種情況下,該“數據代理”無需配置和調度“數據消費者”功能。
(3)MySQL 數據庫表結構定義可以從 information_schema.COLUMNS 直接獲取,其他數據庫可以找類似系統表,如果沒有,則需要單獨填充字段定義。
(4)數據庫設計如下:
- tb_columns_def:表結構定義,從 information_schema.COLUMNS 直接復制
- tb_data_role:數據角色定義

3.2 數據提供者拉取
功能流程如圖 3:
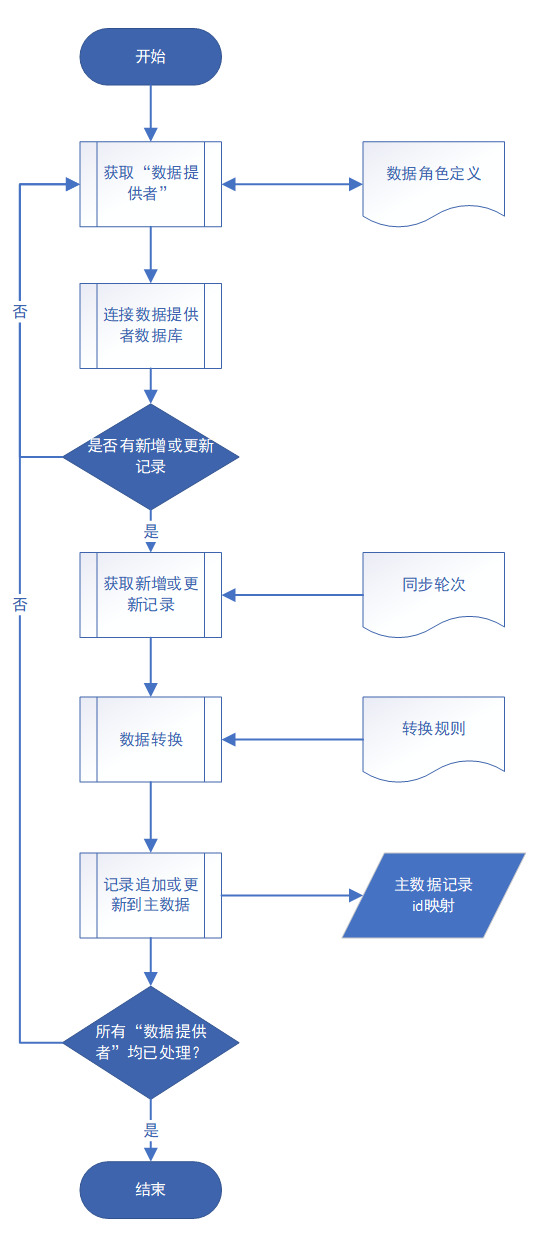
圖 3“數據提供者”拉取流程
其中:
(1)被定時調度(本項目設置 1 分鐘一次)激活后,連接對應的信息系統數據庫,檢查是否有新增或更新記錄,如有,則進行數據拉取——從源數據數據庫拉取并存入主數據數據庫,同時記錄“同步輪次”。
(2)一個信息系統可能提供多個“數據提供者”,在全部數據提供者都輪詢并處理結束后,流程結束。
(3)數據庫設計如下:
tb_data_sync_log:同步日志表,保存同步控制數據

3.3 數據消費者推送
功能流程如圖 4:

圖 4 數據消費者推送流程
其中:
(1)被定時調度激活后,檢查主數據系統“同步輪次”是否有新增,如有,則進行數據推送。連接數據消費者信息系統數據庫,從主數據數據庫推送新增或更新數據記錄到信息系統數據庫,同時記錄“同步輪次”。
(2)檢查主數據系統“同步輪次”是否有新增,通過 tb_data_sync_log.relative_cycle_no 與對應主數據(main_role)記錄的最新倫次比較。
(3)一個信息系統可能需要多個“數據消費者”,在全部數據消費者都輪詢并處理結束后,流程結束。
(4)數據庫設計同數據提供者(參見第 2 節)。
3.4 數據轉換
功能流程如圖 5:

圖 5 數據轉換流程
其中:
(1)數據轉換是不同信息系統與主數據之間,字段類型、長度、格式轉換的核心模塊。
(2)數據轉換通過參數配置和附加處理函數,實現高度靈活性。
(3)數據轉換首先獲取源和目標數據表的字段定義,其次獲取對應字段的轉換規則。對所有已定義轉換規則的字段進行處理:
A、對字段類型、長度進行通用轉換;
B、調用附加處理函數(如果有),進行特殊轉換;
C、按照關聯 id 規則(如果有),讀取主數據數據庫的 id 映射,進行 對應關聯 id 處理;
D、循環處理所有字段。
(4)數據庫設計如下:
tb_transfer_def:轉換規則定義表

tb_transfer_rule:轉換規則字段映射表
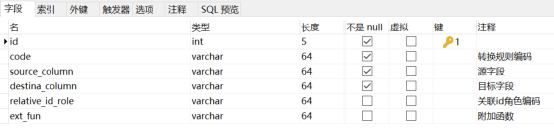
tb_id_mapping:id 映射表
4 關鍵點總結
主數據系統涉及多個系統的數據同步,由于各異構系統的差異性,導致主數據系統復雜度較高,成功的案例不多。本項目基于前述前提,取得較好的效果。現將關鍵點總結分享如下:
1、數據提供者的新增 id 和更新時間戳,對于不具備這兩個條件的數據提供者,無法辨識新增和更新,不能進行增量同步,必須進行改造。如果由于種種原因源數據無法改造,則可以考慮變通方法,利用數據庫自有同步工具(例如 Oracle 的 DGG 等),在同步的副本中增加新增和更新標識;
2、不管數據提供者還是數據消費者,無法進行數據庫直接連接的,則“數據代理”需要以外掛應用的形式存在,與主數據系統的通訊采用 WebService 方式。將帶來緩存、重試、冪等……多個復雜度的大大提高。
3、由于不同主數據表之間字段上存在映射關系,比如人員的所屬部門的,需要在 id 映射上做多次轉換,基本原則就是以落地主數據的 uuid 為“唯一權威”,其他關系都通過與 uuid 映射獲得。
4、待補充——從數據庫設計中,經過思考可以去發現,不再贅述。