













五個例子學會Pandas中的字符串過濾
Pandas 庫有許多可以輕松簡單地處理文本數(shù)據(jù)函數(shù)和方法。 在本文中,我介紹將學習 5 種可用于過濾文本數(shù)據(jù)(即字符串)的不同方法:
- 是否包含一系列字符
- 求字符串的長度
- 判斷以特定的字符序列開始或結束
- 判斷字符為數(shù)字或字母數(shù)字
- 查找特定字符序列的出現(xiàn)次數(shù)
首先我們導入庫和數(shù)據(jù)
import pandas as pddf = pd.read_csv("example.csv")df
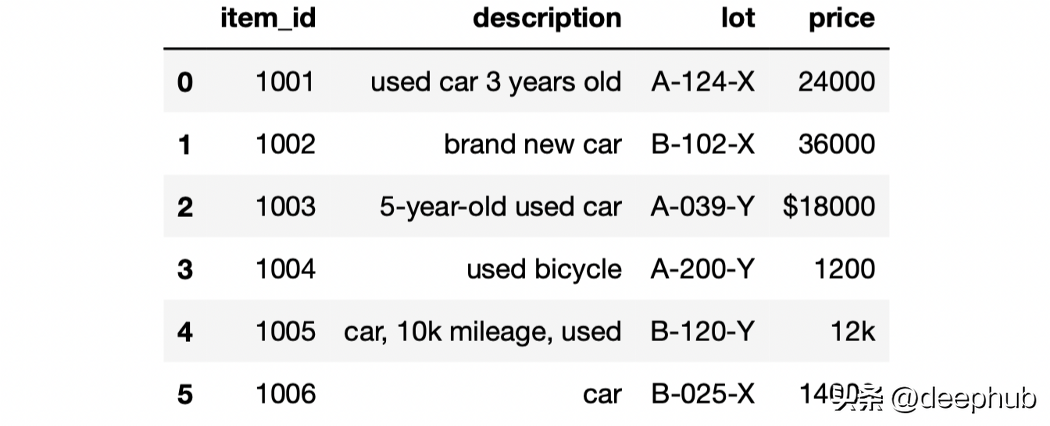
我們這個樣例的DataFrame 包含 6 行和 4 列。 我們將使用不同的方法來處理 DataFrame 中的行。第一個過濾操作是檢查字符串是否包含特定的單詞或字符序列,使用 contains 方法查找描述字段包含“used car”的行。 但是要獲得pandas中的字符串需要通過 Pandas 的 str 訪問器,代碼如下:
df[df["description"].str.contains("used car")]

但是為了在這個DataFrame中找到所有的二手車,我們需要分別查找“used”和“car”這兩個詞,因為這兩個詞可能同時出現(xiàn),但是并不是連接在一起的:
df[df["description"].str.contains("used") &df["description"].str.contains("car")]
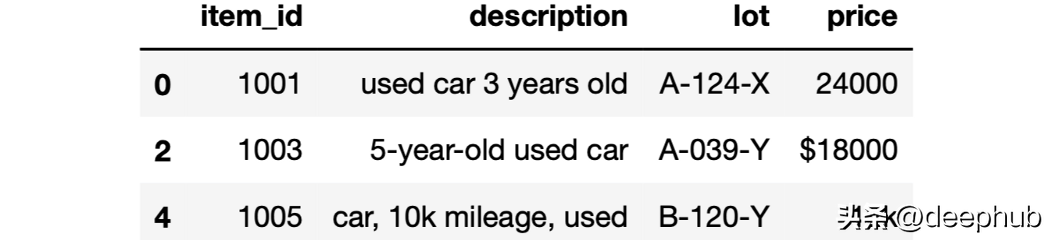
可以看到最后一行包含“car”和“used”,但不是一起。
下一個方法是根據(jù)字符串的長度進行過濾。 假設我們只對超過 15 個字符的描述感興趣。 可以使用內(nèi)置的 len 函數(shù)來執(zhí)行此操作,如下所示:
df[df["description"].apply(lambda x: len(x) > 15)]
這里就需要編寫了一個 lambda 表達式,通過在表達式中使用 len 函數(shù)獲取長度并使用apply函數(shù)將其應用到每一行。 執(zhí)行此操作的更常用和有效的方法是通過 str 訪問器來進行:
df[df["description"].str.len() > 15]

我們可以分別使用startswith和endswith基于字符串的第一個或最后一個字母進行過濾。
df[df["lot"].str.startswith("A")]
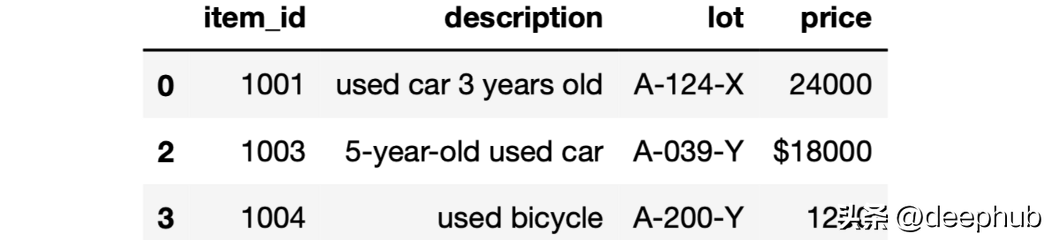
這個方法也能夠檢查前 n 個字符。 例如,我們可以選擇以“A-0”開頭的行:
df[df["lot"].str.startswith("A-0")]

Python 的內(nèi)置的字符串函數(shù)都可以應用到Pandas DataFrames 中。 例如,在價格列中,有一些非數(shù)字字符,如 $ 和 k。 我們可以使用 isnumeric 函數(shù)過濾掉。
df[df["price"].apply(lambda x: x.isnumeric()==True)]

同樣如果需要保留字母數(shù)字(即只有字母和數(shù)字),可以使用 isalphanum 函數(shù),用法與上面相同。
count 方法可以計算單個字符或字符序列的出現(xiàn)次數(shù)。例如,查找一個單詞或字符出現(xiàn)的次數(shù)。
我們這里統(tǒng)計描述欄中的“used”的出現(xiàn)次數(shù):
df["description"].str.count("used")# 結果0 11 02 13 14 15 0Name: description, dtype: int64
如果想使用它進行條件過濾,只需將其與一個值進行比較,如下所示:
df[df["description"].str.count("used") < 1]
非常簡單吧!
本文介紹了基于字符串值的 5 種不同的 Pandas DataFrames 方式。 雖然一般情況下我們更關注數(shù)值類型的數(shù)據(jù),但文本數(shù)據(jù)同樣重要,并且包含許多有價值的信息。能夠對文本數(shù)據(jù)進行清理和預處理對于數(shù)據(jù)分析和建模至關重要。





















