給1萬幀視頻做目標(biāo)分割,顯存占用還不到1.4GB,代碼已開源
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
咦,怎么好好的藤原千花,突然變成了“高溫紅色版”?

這大紫手,難道是滅霸在世??

如果你以為上面的這些效果只是對物體后期上色了,那還真是被AI給騙到了。
這些奇怪的顏色,其實是對視頻對象分割的表示。
但u1s1,這效果還真是讓人一時間分辨不出。
無論是萌妹子飛舞的發(fā)絲:


還是發(fā)生形狀改變的毛巾、物體之間來回遮擋:

AI對目標(biāo)的分割都稱得上是嚴(yán)絲合縫,仿佛是把顏色“焊”了上去。
不只是高精度分割目標(biāo),這種方法還能處理超過10000幀的視頻。
而且分割效果始終保持在同一水平,視頻后半段依舊絲滑精細(xì)。

更意外的是,這種方法對GPU要求不高。
研究人員表示實驗過程中,該方法消耗的GPU內(nèi)存從來沒超過1.4GB。
要知道,當(dāng)下基于注意力機制的同類方法,甚至都不能在普通消費級顯卡上處理超過1分鐘的視頻。
這就是伊利諾伊大學(xué)厄巴納-香檳分校學(xué)者最新提出的一種長視頻目標(biāo)分割方法XMem。
目前已被ECCV 2022接收,代碼也已開源。
如此絲滑的效果,還在Reddit上吸引不少網(wǎng)友圍觀,熱度達(dá)到800+。

網(wǎng)友都在打趣說:
為什么要把你的手涂成紫色?
誰知道滅霸是不是有計算機視覺方面的愛好呢?

模仿人類記憶法
目前已有的視頻對象分割方法非常多,但是它們要么處理速度比較慢,要么對GPU要求高,要么精度不夠高。
而本文提出的方法,可以說是兼顧了以上三方面。
不僅能對長視頻快速進(jìn)行對象分割,畫面幀數(shù)可達(dá)到20FPS,同時在普通GPU上就能完成。
其特別之處在于,它受人類記憶模式所啟發(fā)。
1968年,心理學(xué)家阿特金森和希夫林提出多重存儲模型(Atkinson-Shiffrin memory model)。
該模型認(rèn)為,人類記憶可以分為3種模式:瞬時記憶、短期記憶和長期記憶。
參考如上模式,研究人員將AI框架也劃分出3種內(nèi)存方式。分別是:
- 及時更新的瞬時內(nèi)存
- 高分辨率工作內(nèi)存
- 密集長期記憶內(nèi)存。

其中,瞬時內(nèi)存會每幀更新一次,來記錄畫面中的圖像信息。
工作內(nèi)存從瞬時內(nèi)存中收集畫面信息,更新頻率為每r幀一次。
當(dāng)工作內(nèi)存飽和時,它會被壓縮轉(zhuǎn)移到長期內(nèi)存里。
而長期內(nèi)存也飽和時,會隨著時間推移忘記過時的特征;一般來說這會在處理過數(shù)千幀后才會飽和。
這樣一來,GPU內(nèi)存也就不會因為時間推移而不足了。
通常,對視頻目標(biāo)進(jìn)行分割會給定第一幀的圖像和目標(biāo)對象掩碼,然后模型會跟蹤相關(guān)目標(biāo),為后續(xù)幀生成相應(yīng)的掩碼。
具體來看,XMem處理單幀畫面的過程如下:
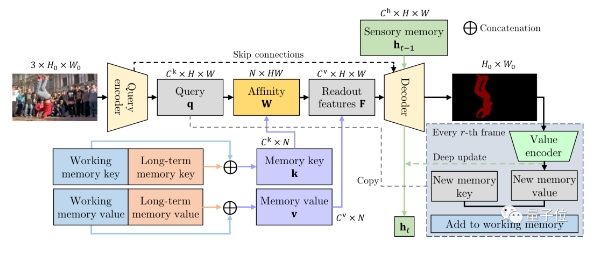

整個AI框架由3個端到端卷積網(wǎng)絡(luò)組成。
一個查詢編碼器(Query encoder)用來追蹤提取查詢特定圖像特征。
一個解碼器(Decoder)負(fù)責(zé)獲取內(nèi)存讀取步驟的輸出,以生成對象掩碼。
一個值編碼器(Value encoder)可以將圖像和目標(biāo)的掩碼相結(jié)合,從而來提取新的內(nèi)存特征值。
最終值編碼器提取到的特征值會添加到工作內(nèi)存中。
從實驗結(jié)果來看,該方法在短視頻和長視頻上,都實現(xiàn)了SOTA。

在處理長視頻時,隨著幀數(shù)的增加,XMem的性能也沒有下降。

研究團隊
作者之一為華人Ho Kei (Rex) Cheng。

他研究生畢業(yè)于香港科技大學(xué),目前在伊利諾伊大學(xué)厄巴納-香檳分校讀博。
研究方向為計算機視覺。
他先后有多篇論文被CVPR、NeurIPS、ECCV等頂會接收。
另一位作者是 Alexander G. Schwing。

他現(xiàn)在是伊利諾伊大學(xué)厄巴納-香檳分校的助理教授,博士畢業(yè)于蘇黎世聯(lián)邦理工學(xué)院。
研究方向為機器學(xué)習(xí)和計算機視覺。
論文地址:
https://arxiv.org/abs/2207.07115
GitHub:
https://github.com/hkchengrex/XMem