













看似蒸蒸日上,其實國產數據庫發展亂象叢生
?寫這篇文章的周末,我很多時候都是在思考一個數據庫國產化替代的建設方案,翻閱了大量的資料。今年正好是我參加工作后的第31個年頭,工作的最初十年,我寫了十年代碼,從匯編、COBOL到C語言,寫了幾十萬行代碼;隨后的十幾年,我一直在幫助用戶用好數據庫,也在幫助Oracle推廣RAC技術;2015年開始,我一邊繼續從事數據庫優化的工作,一邊在幫助客戶如何從Oracle遷移到成本更低的數據庫系統上。所以對國產數據庫我一直有一種十分特殊的情感,這是一種愛恨交織的情感。所以今天最后用“亂象”這個題目的時候,還是有些猶豫的,在國產數據庫發展如火如荼的時候,潑這盆冷水合適不合適。
亂象
1.國產關系型數據庫廠商數量多,碎片化嚴重
根據工信部數據庫發展白皮書2021的描述,截止2021年6月底,光是國產關系型數據庫廠商就已經高達81家,估計馬上要發布的2022版里突破100家甚至150家都是很有可能的。相對于十多年前的寥寥數家,這些年國產數據庫產業的發展確實是十分迅猛,用野蠻生長來描述也不為過。這些新興的國產數據庫廠商里,也不乏具有相當強大基因,投資巨大,真正認真在做數據庫產業的企業,不過大洪水下肯定也會泥沙俱下。原本就起步較晚,人才儲備、資金投入都不太足夠的國產數據庫產業,再被割裂為這么多的細小單位,每個獨立個體的真實能力就很值得懷疑了。無論是CPU,服務器,操作系統,中間件這些IT基礎設施,投身于IT基礎設施中的王冠的企業沒想到有這么多,這不知道是中國數據庫之幸還是中國數據庫的災難。
上周五我在一個沙龍上分享了一些關于基于業務場景的國產數據庫選型的演講,并不是開門見山的去討論業務場景和數據庫選型,而是從對國產數據庫廠商的分析開始的。這些分析都是基于工信部的產業發展白皮書的內容。

從成立年限上看,我們的國產數據庫企業還很年輕,不過成立20年以上的企業還是有十四家,只不過這些企業的這20年并不好過,以數據庫產品銷售為主業根本生存不下去。因此雖然有20年的歷史,實際上真正的歷史恐怕要打些折扣的。
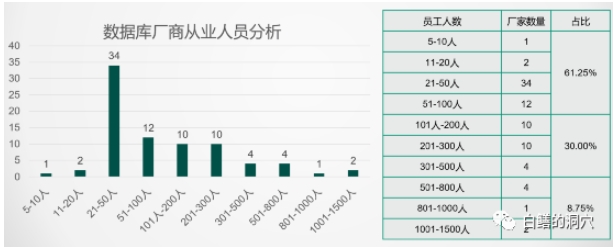
只看歷史可能還無法直接感受到差距,而從從業人數上看,就可以看到國產數據庫產業碎片化的惡果了。超過60%的數據庫廠商不足100人,而超過500人的企業不足10%。對于想摘取IT基礎設施王冠的中國數據庫企業,最大的企業的規模可能還不如某個哪怕二三流的國外數據庫廠商的一個小研發部門的規模。如果把人員再細化為管理、研發、產品、市場、銷售、后勤等部門,恐怕研發人員就更是少得可憐了。據說目前國內最大的數據庫廠商的研發人員不足500人,這就是中國數據庫企業的現狀。

2.技術基礎薄弱,人才匱乏,大多數技術來源于開源項目
如果我們再來看看技術層面的東西,從專利數量上看,90%的數據庫企業的數據庫領域的專利數少于100件,所有的關系型數據庫廠商的專利數加在一起不足4000件,而截止2020年,Oracle公司一家企業的專利數就超過1萬4千件。
在技術基礎薄弱,人才匱乏的情況下,為什么一下子能涌現出如此多的數據庫企業和產品呢?從國產數據庫的技術來源分析上我們就可以看出一些端倪了。

上面這個圖表是我們根據收集到的資料自己做的,不一定十分準確,不過可以大體反映出國產數據庫的技術來源。大多數是來自于開源項目,因此才會出現大量的規模較小的數據庫企業。使用開源技術來發展自己的數據庫產業并不是一件壞事,實際上我還是比較贊成的。充分利用開源技術能夠加速國產數據庫產業的發展,縮短與國外頭部企業的差距。不過利用開源技術不等于完全依靠開源技術,而是應該在開源技術基礎上進行大量的自主創新,加入自己的技術。比如國內有很多利用PG開源代碼的數據庫產品,有哪家公司對PG的源碼的理解程度,對PG社區的貢獻能夠達到俄羅斯POSTGRESQLPRO的水平呢?可喜的是,在這種亂象后面我們已經看到了一些數據庫廠商開始了自主化的創新,在開源代碼的基礎上已經走得很遠了,我想再有幾年的積累,一定會突破開源技術上的某些瓶頸,走出自己的自主化道路。
3.國產數據庫的代碼自主化率是個迷
如果看工信部的代碼自主化測試報告,那么絕大多數號稱國產自研的數據庫產品都能夠拿出很高自主化率的報告來,而且動不動都是95%以上的。我曾經測試過一個號稱代碼自主化率超過95%的數據庫產品,其SQL引擎是完全“兼容”MYSQL的,存儲引擎用的不是INNODB。有一次一不小心我把一個不太常用的MYSQL原生態的參數調整了一下,沒想到,SQL引擎的工作模式居然按照參數的要求調整了。如果僅僅為了保持MYSQL語法的兼容性的自主化代碼,連這種細微之處都模仿得如此完美,那也太牛了吧。
4.時常聲稱吊打Oracle,實際上與Oracle差距甚大
雖然國產數據庫的專利很少,不過這不影響國產數據庫彎道超車,如果不能把Oracle拉出來吊打一番都不好意思說自己是國產數據庫。而真實的應用場景下卻反映出來我們的國產數據庫在CBO和SQL引擎方面與Oracle差距甚大。我也曾經和一些數據庫研發人員做過深度交流,他們也承認,要在數據庫上縮短與Oracle的差距是十分困難的。無論在人才積累、資金投入和實際應用案例的反饋等方面都存在巨大的差距。特別是第三點,導致Oracle可以不斷從生產環境中發現優化器的問題加以改進,而我們甚至都不知道優化器改進的目標,更不要談從架構上去規劃優化器的發展路線了。
5.HTAP成為國產數據庫的標配功能
雖然我們的國產數據庫還無法解決用戶迫切需要的SQL引擎和優化器的提升,不過并不妨礙我們在其他一些領域上進行創新。在各種宣傳資料上,HTAP已經成為了國產數據庫的標配功能,不過我想一些國產數據庫廠商自己都沒幾個人真正地懂得什么是HTAP。他們號稱的所謂HTAP大多數只是一個OLTP數據庫上具有一定的批處理能力而已。OLAP的計算場景和OLTP是完全不同的,OLTP要求資源均衡分配,每次執行的延時穩定并且盡可能段。而OLAP要求的是小并發下的大型甚至巨型計算,利用并行執行充分利用服務器的資源,盡可能把CPU/內存/IO的能力都充分壓榨出來,完成復雜的計算,大吞吐量的數據輸入和輸出。一個連資源隔離都做不好的數據庫產品,如何支持HTAP中兩種會互相傷害的計算場景呢?我見識過的大多數號稱完美解決HTAP問題的數據庫產品,實際上都不真正具備可實用的混合負載能力。僅僅是在某些測試環境可以表現出一些能力而已。
雖然如此,也并不能阻止HTAP成為很多企業招標中的參數指標,我不知道是采購單位是真正需要這種計算能力,還是僅僅以此來黨同伐異的噱頭呢?
6.評價體系的亂象
每年都會出臺各種所謂的國產數據庫排行榜,不過這種排行榜似乎有點排排坐吃果果的感覺,第一名和第二十名的評分不超過5分,前幾天我看到一個榜單,第一名和第十名的分差只有1分多。如果我是一個企業的IT主管,會有一個感覺,這個榜上的產品,隨便選都不會有多大的差別吧。
結語
國產數據庫現在迎來了最好的發展機遇,我們已經看到了芯片,服務器、安全等領域都在這個機遇到來時顯現出了勃勃生機。而在我相對熟悉的數據庫領域,我看到的只是一種表面的繁榮,并沒有看到一種良性的發展趨勢,希望這種局面很快會有所改觀,希望國產數據庫產業能夠異軍突起。?














