同事多線程使用不當導致OOM,被我怒懟了
老規矩,我們先看下事故過程:某日,從 6 點 32 分開始少量用戶訪問 app 時會出現首頁訪問異常,到 7 點 20 分首頁服務大規模不可用,7 點 36 分問題解決。
整體經過
事故的整個經過如下:
6:58,發現報警,同時發現群里反饋首頁出現網絡繁忙,考慮到前幾日晚上門店列表服務上線發布過,所以考慮回滾代碼緊急處理問題。
7:07,開始先后聯系 XXX 查看解決問題。
7:36,代碼回滾完,服務恢復正常。
事故根本原因
事故代碼模擬如下:
public static void test() throws InterruptedException, ExecutionException {
Executor executor = Executors.newFixedThreadPool(3);
CompletionService<String> service = new ExecutorCompletionService<>(executor);
service.submit(new Callable<String>() {
@Override
public String call() throws Exception {
return "HelloWorld--" + Thread.currentThread().getName();
}
});
}
先拋出問題,我們后面會詳細闡述。問題的根源就在于 ExecutorCompletionService 結果沒調用 take,poll 方法。
正確的寫法如下所示:
public static void test() throws InterruptedException, ExecutionException {
Executor executor = Executors.newFixedThreadPool(3);
CompletionService<String> service = new ExecutorCompletionService<>(executor);
service.submit(new Callable<String>() {
@Override
public String call() throws Exception {
return "HelloWorld--" + Thread.currentThread().getName();
}
});
service.take().get();
}
一行代碼引發的血案,而且不容易被發現,因為 OOM 是一個內存緩慢增長的過程,稍微粗心大意就會忽略,如果是這個代碼塊的調用量少的話,很可能幾天甚至幾個月后暴雷。
操作人回滾 or 重啟服務器確實是最快的方式,但是如果不是事后快速分析出 OOM 的代碼,而且不巧回滾的版本也是帶 OOM 代碼的,就比較悲催了。
如剛才所說,流量小了,回滾或者重啟都可以釋放內存;但是流量大的情況下,除非回滾到正常的版本,否則 GG。
探討問題的根源
接下來我們來探討問題的根源,為了更好的理解 ExecutorCompletionService 的 “套路”,我們用 ExecutorService 來作為對比,可以讓我們更好的清楚,什么場景下用 ExecutorCompletionService。
先看 ExecutorService 代碼:(建議 down 下來跑一跑,以下代碼建議吃飯的時候不要去看,味道略重!不過便于理解 orz)
public static void test1() throws Exception{
ExecutorService executorService = Executors.newCachedThreadPool();
ArrayList<Future<String>> futureArrayList = new ArrayList<>();
System.out.println("公司讓你通知大家聚餐 你開車去接人");
Future<String> future10 = executorService.submit(() -> {
System.out.println("總裁:我在家上大號 我最近拉肚子比較慢 要蹲1個小時才能出來 你等會來接我吧");
TimeUnit.SECONDS.sleep(10);
System.out.println("總裁:1小時了 我上完大號了。你來接吧");
return "總裁上完大號了";
});
futureArrayList.add(future10);
Future<String> future3 = executorService.submit(() -> {
System.out.println("研發:我在家上大號 我比較快 要蹲3分鐘就可以出來 你等會來接我吧");
TimeUnit.SECONDS.sleep(3);
System.out.println("研發:3分鐘 我上完大號了。你來接吧");
return "研發上完大號了";
});
futureArrayList.add(future3);
Future<String> future6 = executorService.submit(() -> {
System.out.println("中層管理:我在家上大號 要蹲10分鐘就可以出來 你等會來接我吧");
TimeUnit.SECONDS.sleep(6);
System.out.println("中層管理:10分鐘 我上完大號了。你來接吧");
return "中層管理上完大號了";
});
futureArrayList.add(future6);
TimeUnit.SECONDS.sleep(1);
System.out.println("都通知完了,等著接吧。");
try {
for (Future<String> future : futureArrayList) {
String returnStr = future.get();
System.out.println(returnStr + ",你去接他");
}
Thread.currentThread().join();
} catch (Exception e) {
e.printStackTrace();
}
}
三個任務,每個任務執行時間分別是 10s、3s、6s。
通過 JDK 線程池的 submit 提交這三個 Callable 類型的任務:
- step1:主線程把三個任務提交到線程池里面去,把對應返回的 Future 放到 List 里面存起來,然后執行“都通知完了,等著接吧。”這行輸出語句。
- step2:在循環里面執行 future.get() 操作,阻塞等待。
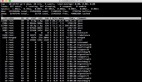
最后結果如下:

先通知到總裁,也是先接總裁,足足等了 1 個小時,接到總裁后再去接研發和中層管理,盡管他們早就完事兒了,也得等總裁拉完~~
耗時最久的-10s 異步任務最先進入 list 執行,所以在循環過程中獲取這個 10s 的任務結果的時候,get 操作會一直阻塞,直到 10s 異步任務執行完畢。即使 3s、5s 的任務早就執行完了,也得阻塞等待 10s 任務執行完。
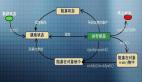
看到這里,尤其是做網關業務的同學可能會產生共鳴,一般來說網關 RPC 會調用下游 N 多個接口,如下圖:

如果都按照 ExecutorService 這種方式,并且恰巧前幾個任務調用的接口耗時比較久,同時阻塞等待,那就比較悲催了。
所以 ExecutorCompletionService 應景而出。它作為任務線程的合理管控者,“任務規劃師”的稱號名副其實。
相同場景 ExecutorCompletionService 代碼:
public static void test2() throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
ExecutorCompletionService<String> completionService = new ExecutorCompletionService<>(executorService);
System.out.println("公司讓你通知大家聚餐 你開車去接人");
completionService.submit(() -> {
System.out.println("總裁:我在家上大號 我最近拉肚子比較慢 要蹲1個小時才能出來 你等會來接我吧");
TimeUnit.SECONDS.sleep(10);
System.out.println("總裁:1小時了 我上完大號了。你來接吧");
return "總裁上完大號了";
});
completionService.submit(() -> {
System.out.println("研發:我在家上大號 我比較快 要蹲3分鐘就可以出來 你等會來接我吧");
TimeUnit.SECONDS.sleep(3);
System.out.println("研發:3分鐘 我上完大號了。你來接吧");
return "研發上完大號了";
});
completionService.submit(() -> {
System.out.println("中層管理:我在家上大號 要蹲10分鐘就可以出來 你等會來接我吧");
TimeUnit.SECONDS.sleep(6);
System.out.println("中層管理:10分鐘 我上完大號了。你來接吧");
return "中層管理上完大號了";
});
TimeUnit.SECONDS.sleep(1);
System.out.println("都通知完了,等著接吧。");
//提交了3個異步任務)
for (int i = 0; i < 3; i++) {
String returnStr = completionService.take().get();
System.out.println(returnStr + ",你去接他");
}
Thread.currentThread().join();
}
跑完結果如下:

這次就相對高效了一些,雖然先通知的總裁,但是根據大家上大號的速度,誰先拉完先去接誰,不用等待上大號最久的總裁了(現實生活里,建議采用第一種,不等總裁的后果 emmm 哈哈哈)。
放在一起對比下輸出結果:

兩段代碼的差異非常小,獲取結果的時候 ExecutorCompletionService 使用了:
completionService.take().get();
為毛要用 take() 然后再 get() 呢????我們看看源碼:
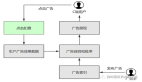
CompletionService 接口以及接口的實現類
ExecutorCompletionService 是 CompletionService 接口的實現類:

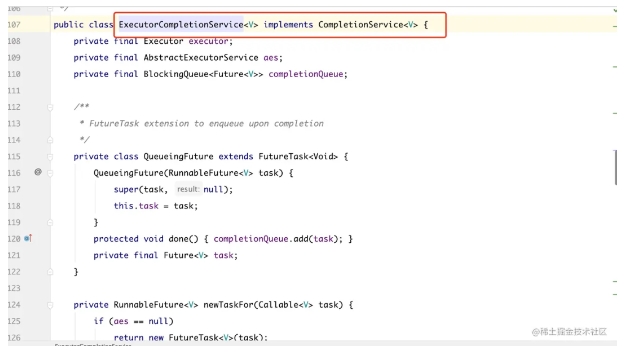
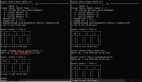
接著跟一下 ExecutorCompletionService 的構造方法,可以看到入參需要傳一個線程池對象,默認使用的隊列是 LinkedBlockingQueue,不過還有另外一個構造方法可以指定隊列類型,如下兩張圖,兩個構造方法。
默認 LinkedBlockingQueue 的構造方法:

可選隊列類型的構造方法:

submit 任務提交的兩種方式,都是有返回值的,我們例子中用到的就是第一種 Callable 類型的方法。

對比 ExecutorService 和 ExecutorCompletionService submit 方法,可以看出區別。
ExecutorService:

ExecutorCompletionService:

差異就在 QueueingFuture,這個到底作用是啥?
我們繼續跟進去看:
- QueueingFuture 繼承自 FutureTask,而且紅線部分標注的位置,重寫了 done() 方法。
- 把 task 放到 completionQueue 隊列里面,當任務執行完成后,task 就會被放到隊列里面去了。
- 此時此刻 completionQueue 隊列里面的 task 都是已經 done() 完成了的 task,而這個 task 就是我們拿到的一個個的 future 結果。
- 如果調用 completionQueue 的 task 方法,會阻塞等待任務。等到的一定是完成了的 future,我們調用 .get() 方法就能立馬獲得結果。

看到這里,相信大家伙都應該多少明白點了:
- 我們在使用 ExecutorService submit 提交任務后需要關注每個任務返回的 future,然而 CompletionService 對這些 future 進行了追蹤,并且重寫了 done 方法,讓你等的 CompletionQueue 隊列里面一定是完成了的 task。
- 作為網關 RPC 層,我們不用因為某一個接口的響應慢拖累所有的請求,可以在處理最快響應的業務場景里使用 CompletionService。
but,注意、注意、注意,也是本次事故的核心
當只有調用了 ExecutorCompletionService 下面的 3 個方法的任意一個時,阻塞隊列中的 task 執行結果才會從隊列中移除掉,釋放堆內存。
由于該業務不需要使用任務的返回值,則沒進行調用 take,poll 方法。從而導致沒有釋放堆內存,堆內存會隨著調用量的增加一直增長。

所以,業務場景中不需要使用任務返回值的 別沒事兒使用 CompletionService,假如使用了,記得一定要從阻塞隊列中移除掉 task 執行結果,避免 OOM!
總結
知道事故的原因,我們來總結下方法論,畢竟孔子他老人家說過:自省吾身,常思己過,善修其身!
上線前:
- 嚴格的代碼 review 習慣,一定要交給 back 人去看,畢竟自己寫的代碼自己是看不出問題的,相信每個程序猿都有這個自信(這個后續事故里可能會反復提到,很重要)
- 上線記錄-備注好上一個可回滾的包版本(給自己留一個后路)
- 上線前確認回滾后,業務是否可降級,如果不可降級,一定要嚴格拉長這次上線的監控周期
上線后:
- 持續關注內存增長情況(這部分極容易被忽略,大家對內存的重視度不如 CPU 使用率)
- 持續關注 CPU 使用率增長情況
- GC 情況、線程數是否增長、是否有頻繁的 FullGC 等
- 關注服務性能報警,tp99、999 、max 是否出現明顯的增高?