解Bug之路-TCP使用不當引起的Bug
前言
筆者很熱衷于解決Bug,同時比較擅長(網絡/協議)部分,所以經常被喚去解決一些網絡IO方面的Bug。現在就挑一個案例出來,寫出分析思路,以饗讀者,希望讀者在以后的工作中能夠少踩點坑。
關于TCP流
TCP是流的概念,解釋如下
- TCP窗口的大小取決于當前的網絡狀況、對端的緩沖大小等等因素,
- TCP將這些都從底層屏蔽。開發者無法從應用層獲取這些信息。
- 這就意味著,當你在接收TCP數據流的時候無法知道當前接收了
- 有多少數據流,數據可能在任意一個比特位(seq)上。
Bug現場
出Bug的系統是做與外部系統進行對接之用。這兩者并不通過http協議進行交互,而是在通過TCP協議之上封裝一層自己的報文進行通訊。如下圖示:

通過監控還發現,此系統的業務量出現了不正常的飆升,大概有4倍的增長。而且在監控看來,這些業務還是成功的。
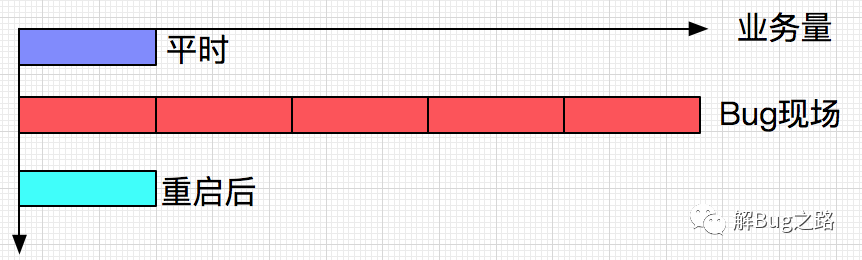
第一反應,當然是祭出重啟大法,第一時間重啟了機器。此后一切正常,交易量也回歸正常,仿佛剛才的Bug從來沒有發生過。在此之前,此系統已經穩定運行了好幾個月,從來沒出現過錯誤。
但是,這事不能就這么過去了,下次又出這種Bug怎么辦,繼續重啟么?由于筆者對分析這種網絡協議比較在行,于是Bug就拋到了筆者這。
錯誤日志
線上系統用的框架為Mina,不停的Dump出其一堆以16進制表示的二進制字節流。

,并拋出異常

首先定位異常拋出點
以下代碼僅為筆者描述Bug之用,和當時代碼有較大差別。
- private boolean handeMessage(IoBuffer in,ProtocolDecoderOutput out){
- int lenDes = 4;
- byte[] data = new byte[lenDes];
- in.mark();
- in.get(data,0,lenDes);
- int messageLen = decodeLength(data);
- if(in.remaining() < messageLen){
- logger.warn("未接收完畢");
- in.reset();
- return false;
- }else{
- ......
- }
- }
筆者本身經常寫這種拆包代碼,第一眼就發現有問題。讓我們再看一眼報文結構:

上面的代碼首先從報文前4個字節中獲取到報文長度,同時檢測在buffer中的存留數據是否夠報文長度。
- if(in.remaining() < messageLen)
為何沒有在一開始檢測buffer中是否有足夠的4byte字節呢。此處有蹊蹺。直覺上就覺的是這導致了后來的種種現象。
事實上,在筆者解決各種Bug的過程中,經常通過猜想等手段定位出Bug的原因。但是從現場取證,通過證據去解釋發生的現象,通過演繹去說服同事,并對同事提出的種種問題做出合理的解釋才是最困難的。
猜想總歸是猜想,必須要有實錘,沒有證據也說服不了自己。
為何會拋出異常
這個異常由這句代碼拋出:
- int messageLen = decodeLength(data);
從上面的Mina框架Dump出的數據來看,是解析前四個字節出了問題,前4個字節為30,31,2E,01(16進制)
最前面的包長度是通過字符串來表示的,翻譯成十進制就是48、49、46、1,再翻譯為字符串就是('0','1', 非數字, 非數字)
- 30, 31, 2E, 01 (16進制)
- 48, 49, 46, 1 (10進制)
- '0','1',非數字, 非數字 (字符串)
很明顯,解析字符串的時候遇到前兩個byte,0和1可以解析出來,但是遇到后面兩個byte就報錯了。至于為什么是For input String,'01',而不是2E,是由于傳輸用的是小端序。
為何報文會出現非數字的字符串
鑒于上面的錯誤代碼,筆者立馬意識到,應該是TCP流處理不當了。這時候就應該去找發生Bug的最初時間點的日志,去分析為何那個時間會gg。
由于最初那個錯誤日志Dump數來的數據過于長,在此就不貼出來了,以下示意圖是筆者當時人肉decode的結果:

拋出的異常為:

這個異常拋出點恰恰就在筆者懷疑的
- in.get(data,0,lenDes);
這里。至此,筆者就幾乎已經確定是這個Bug導致的。
演繹
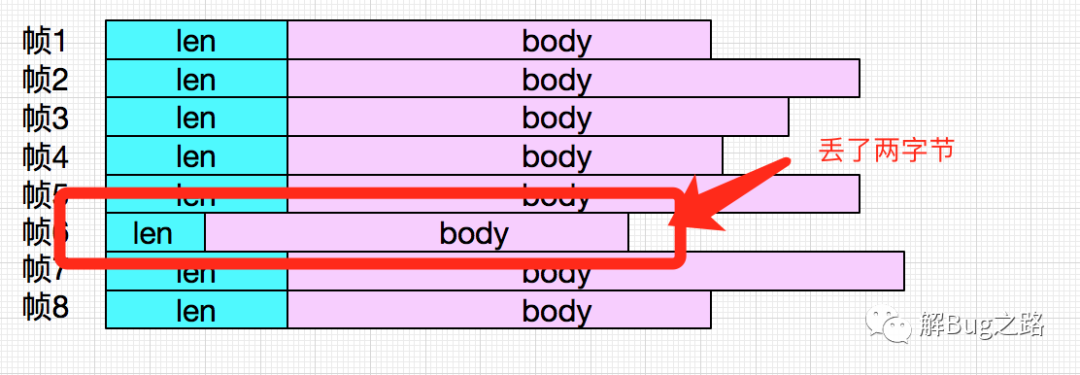
Mina框架在Buffer中解幀,前5幀正常。但是到第六幀的時候,只有兩個字節,無法組成報文的4byte長度頭,而代碼沒有針對此種情況做處理,于是報錯。為何會出現這種情況:
- TCP窗口的大小取決于當前的網絡狀況、對端的緩沖大小等等因素,
- TCP將這些都從底層屏蔽。開發者無法從應用層獲取這些信息。
- 這就意味著,當你在接收TCP數據流的時候無法知道當前接收了
- 有多少數據流,數據可能在任意一個比特位(seq)上。
第六幀的頭兩個字節是30,32正好和后面dump出來的30 31 2e 01中的30、31組成報文長度
- 30,32,30,31 (16進制)
- 48,50,48,49 (10進制)
- 0, 2, 0, 1 (字符串)
- 2, 0, 1, 0 (整理成大端序)
這四個字節組合起來才是正常的報文頭,再經過運算得到整個Body的長度。
第一次Mina解析的時候,后面的兩個30,31尚未放到buffer中,于是出錯:
- public ByteBuffer get(byte[] dst, int offset, int length) {
- checkBounds(offset, length, dst.length);
- // 此處拋出異常
- if (length > remaining())
- throw new BufferUnderflowException();
- int end = offset + length;
- for (int i = offset; i < end; i++)
- dst[i] = get();
- return this;
- }
為何流量會飆升
解釋這個問題前,我們先看一段Mina源碼:
- // if there is any data left that cannot be decoded, we store
- // it in a buffer in the session and next time this decoder is
- // invoked the session buffer gets appended to
- if (buf.hasRemaining()) {
- if (usingSessionBuffer && buf.isAutoExpand()) {
- buf.compact();
- } else {
- storeRemainingInSession(buf, session);
- }
- } else {
- if (usingSessionBuffer) {
- removeSessionBuffer(session);
- }
- }
Mina框架為了解決這種問題,會將這種尚未接收完全的包放到sessionBuffer里面,待解析完畢后把這份Buffer刪除。
如果代碼正確,對報文頭做了校驗,那么前5個報文的buffer將經由這幾句代碼刪除,只留下最后兩個沒有被decode的兩字節。
- if (usingSessionBuffer && buf.isAutoExpand()) {
- buf.compact();
- } else {
- storeRemainingInSession(buf, session);
- }
但是,由于decode的時候拋出了異常,沒有走到這段邏輯,所以前5個包還留在sessionBuffer中,下一次解包的時候,又會把這5個包給解析出來,發送給后面的系統。
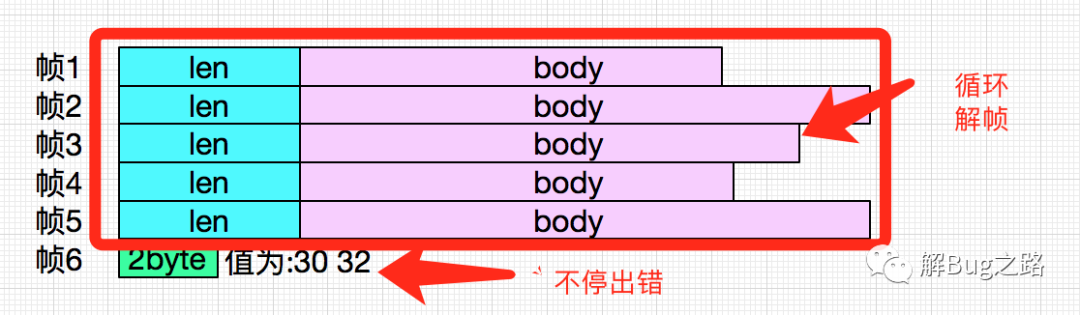
這也很好的解釋了為什么業務量激增,因為系統不停的發相同的5幀給后面系統,導致監控認為業務量飆升。后查詢另一個系統的日志,發現一直同樣的5個序列號坐實了這個猜想。
完結了么?
NO,整個演繹還有第二段日志的推演
就是系統后來不停dump出的日志,再貼一次:

這個buffer應該是Mina繼續接收外部系統的數據到buffer中導致,
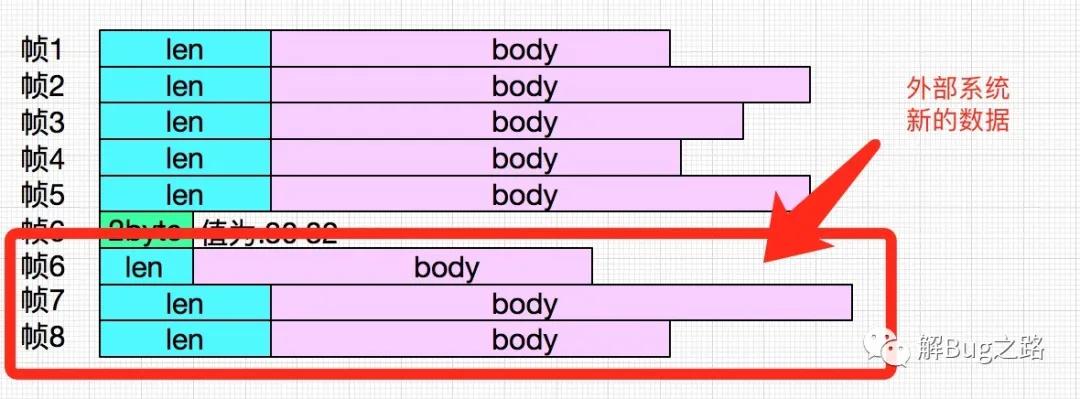
Mina框架不停的接收數據,直到buffer區滿,然后整個框架不停的解析出前5幀,到第6幀的時候,出錯,然后dump出其尚未被解幀的數據。這就是第二段日志。
最后的高潮
到現在推理似乎很完美了,但是我突然覺得不對(另一位同事也提出了相同的疑問):
如果說Mina接收到新的數據放到buffer中的話,第6幀的前兩個字節和后來發過來的若干字節不是又拼成了完整的一幀了么,那么后來為什么會一直出錯了呢。如下圖所示:
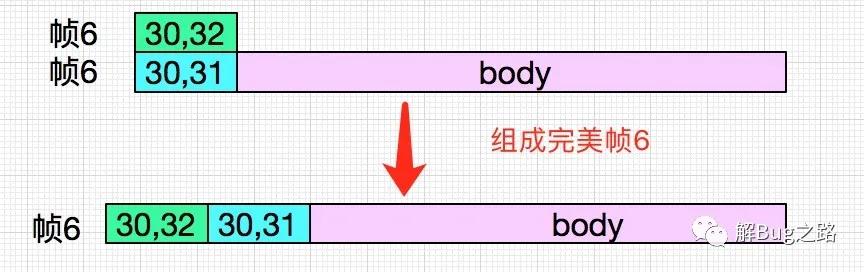
丟失的兩字節
按照前面的推理,幀6的前兩個字節30、32肯定是丟了,那么怎么丟的呢?推理又陷入了困境,怎么辦?日志已經幫不了筆者了,畢竟日志的表現都已解釋清楚。翻源碼吧:
Bug的源頭:
如果有問題,肯定出在將數據放在Buffer中的環節,于是筆者找到了這段代碼:
- if (appended) {
- buf.flip();
- } else {
- // Reallocate the buffer if append operation failed due to
- // derivation or disabled auto-expansion.
- buf.flip();
- ......
- }
問題出在buf.flip()上面,這段代碼最后調用的代碼是Java的Nio的Buffer的flip,代碼如下:
- public final Buffer flip() {
- // 下面這一句導致了最終的Bug現象
- limit = position;
- position = 0;
- mark = -1;
- return this;
- }
為什么呢?首先我們需要了解一下Nio Buffer的一些特點:
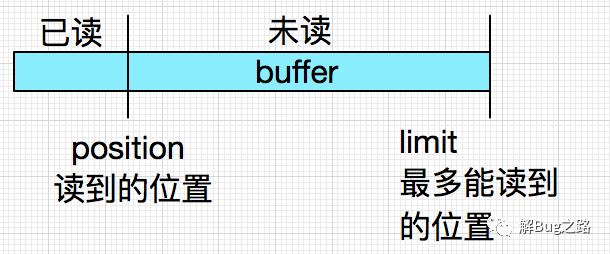
同時當Mina框架將數據(數據本身也是一個buffer)放到sessionBuffer的時候,也是將position到limit的數據放到新buffer中,
下面我們演繹一下第一次拋異常時候的flip前和flip后:
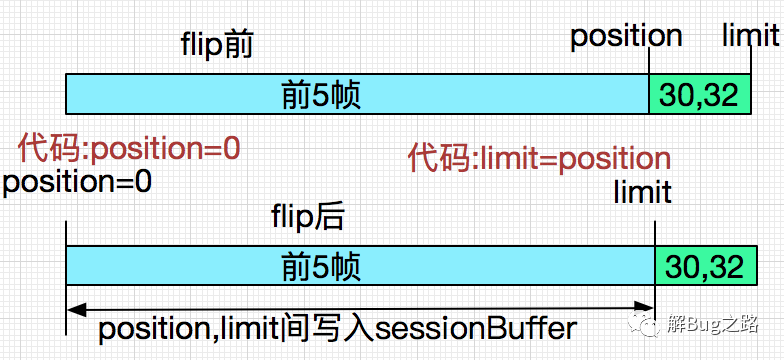
這樣就清楚了,在buf.flip()后,由于limit變成了原position的位置,這樣最后的兩個字節30,32就被無情的丟棄了。這樣整個sessionBuffer就變成:
為什么position在flip前沒有指向limit的位置,是由于在每次讀取前有一個checkBound的動作,在檢查buffer數據不夠后,不會推進position的位置,直接拋出異常:
- static void checkBounds(int off, int len, int size) { // package-private
- if ((off | len | (off + len) | (size - (off + len))) < 0)
- throw new IndexOutOfBoundsException();
- }
- 這樣所有的都
這樣所有的都說的通了,也完美了解釋了所有的現象。
正確代碼
- private boolean handeMessage(IoBuffer in,ProtocolDecoderOutput out){
- int lenDes = 4;
- byte[] data = new byte[lenDes];
- in.mark();
- // 前4字節校驗代碼
- if(in.remaining() < lenDes){
- // 由于未消費字節,無需reset
- return false;
- }
- in.get(data,0,lenDes);
- int messageLen = decodeLength(data);
- if(in.remaining() < messageLen){
- logger.warn("未接收完畢");
- in.reset();
- return false;
- }else{
- ......
- }
- }
為什么線上一直穩定
隨著網絡不斷發展的今天,一些短小的幀很難出現中間斷開的現象。而在一個好幾百字節的包中,前4個字節正好出錯的概率那更是微乎其微。這樣就導致Bug難復現,很難抓住。即使猜到是這里,也沒有足夠的證據來證明。
總結
Mina/Netty等各種網絡框架給我們處理TCP流問題提供了非常好的解決方案。但是我們寫代碼的時候也不能掉以輕心,必須時刻以當前可能讀不夠字節的心態去讀取buffer中的數據,不然就可能遭重。
在此感謝給力的各位同事們,是你們的各種反駁讓我能夠找到最終的源頭,也讓我對網絡框架有了更加深刻的理解。
本文轉載自微信公眾號「解Bug之路」,可以通過以下二維碼關注。轉載本文請聯系解Bug之路公眾號。