14天才恢復,業界近年最大SaaS宕機事件
如果你用來管理所有開發項目的平臺,企業內部文件的共享知識庫,還有業務、銷售、和行政部門合作的項目平臺,突然都宕機了,甚至廠商告訴你,要2周后才能修復,這段期間,所有數據無法存取,也沒有備份版本可用,你會怎么辦?這正是775家企業在Atlassian四月大宕機事件,所遭遇的處境。

Atlassian是20歲的澳洲老牌軟件開發商,旗下擁有知名的企業項目管理平臺Jira,企業文件協作平臺Confluence,還有看板協作工具Trello。許多大型企業都采用Jira來管理公司的敏捷開發項目,甚至Atllassian還推出給非技術團隊用的敏捷項目平臺,不少企業用于業務、銷售、商業分析團隊的敏捷管理。
根據Atlassian今年3月財報數據,超過75%的財富五百強企業都是他們的企業用戶,全球更有23萬家企業采用,光是用Jira Service Management服務來進行企業內部大型系統開發項目生命周期管理的企業,就超過了4萬家,不少是大型企業,更有178家企業每年授權訂閱費用超過百萬美元,相當于有數千人訂閱授權數的規模,甚至訂閱數最多的一家超大型企業,訂閱了5萬個授權。Atlassian一年光是訂閱費用的營收就超過了13億美元。
雖然Atlassian沒有公開這次事故受影響的企業名單,只披露受影響企業家數是775家,但其中有400家是活躍使用的企業。根據國外媒體采訪受影響企業的結果,小則有150個授權,大則有訂閱多達4千個授權的企業。根據非官方估算,775家受影響企業下,累積受到沖擊的個人使用者超過了5萬人。這起事件也大大重挫了Atlassian市值,從宕機事件到完全復原這2周期間,Atlassian股價足足下滑了近2成,后續到5月下旬仍持續下滑中。
Atlassian擁有十多年SaaS服務的運維經驗,6年SRE經驗,以及云上業界標準常見的災備和恢復計劃,都無法事前發現,及時阻止4月大宕機,無法在99.9%服務水準承諾(SLA) 承諾的8.76小時內復原,甚至有不少企業遲遲等到14天后,才能打開自己的敏捷項目數據。
為何這家云服務廠商,SRE運維專家,無法避免這次大宕機的發生?
大宕機事件發生過程追追追,一只刪除程序的誤用而釀災
回到事件發生當天,4月5日早上,這一天是Atlassian年度大會Team22的前一天,Atlassian要淘汰一些舊版App,在4月5日這一天刪除這些舊版應用的程序。正是這支刪除舊版AP的腳本程序造成了這起宕機事故。早在實際執行刪除之前,Atlassian測試過這只腳本沒有問題,甚至在正式環境中試刪除了30個顧客所用的舊版Ap,也沒有發生問題。
提出刪除申請的業務團隊,提供了一份目前還在使用這些舊版AP的企業顧客名單,作為腳本自動執行刪除的目標清單。但是,關鍵的出錯環節是,他們提供的ID清單,不是直接提供要刪除AP的ID,而是給了這些待刪除AP ID所在的網站ID清單,再告訴執行刪除指令的工程團隊,要刪除這些網站ID中的老舊AP。但是,雙方發生了溝通落差,工程團隊誤以為,這批網站ID就是要刪除的清單,直接套用到刪除腳本來執行。到了4月5日,這只腳本刪除的不是舊版AP,而是刪除了那些還在使用舊版AP的企業的全部網站數據。
釀災起因:想刪除老舊App,為何反而刪除顧客全站數據?
要了解誤刪的影響,得先知道用APP ID來刪除,和使用網站ID來刪除,有何差別?這得從Atlassiant技術架構說起。
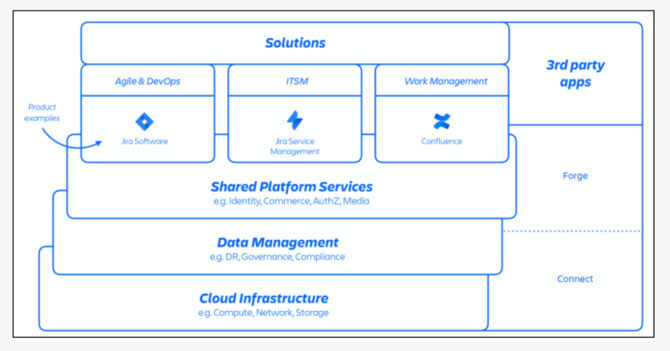
Atlassiant所有服務都部署在AWS上,在數據儲存上和服務架構上,都采取了高度分布式架構,以及容易組合再利用的微服務架構,并在云上基礎架構上來設計了書架管理層和共用的平臺服務層,也通過API串連到許多第三方廠商的應用。所有微服務都布建在AWS的容器化服務上,更搭配了一套PaaS服務,稱為Micros,來提供內部微服務的自動化構建。從公共服務部署、基礎架構資源調度、數據儲存管理、合規性管制都靠這個平臺自動完成。
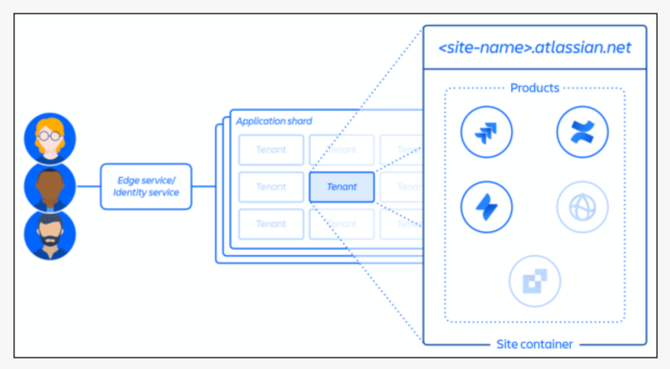
另外在管理架構上,Atlassian采取了多租戶架構,并以網域作為單一用戶的最基本管理單位,這就是網站ID。企業要指定一個網址作為登入Atlassian服務的主要入口網站,也把他們所訂閱的所有Atlassian服務,都登記到這個網址下。Atlassian也稱這個網址是一個網站容器,用來容納屬于這個企業顧客的所有數據、配置和所用的APP。網站ID就是用來識別一家企業的網站容器的代號。
Atlassian的技術架構采取了分布式架構,不只在云端基礎架構采取分布式架構來提高可用性,在應用系統層次,也采取了多租戶微服架構設計來兼顧彈性和可用性。
圖片來源/Atlassian
Atlassian的網站ID(企業顧客網站URL網址)也是一個網站容器,將一家企業的所有數據、配置和所用的APP,都登記到這個網站ID來管理。
圖片來源/Atlassian
Atlassian也用這個網站ID來作為識別一個企業用戶帳號的代號,所有與這家企業有關的數據、表單、帳單,也都用這個網站ID來作為識別客戶的索引,例如企業顧客提出支持工單時,這張工單就會用網站ID作為所屬客戶的代號。
當Atlassian業務單位提出了一份要刪除老舊APP的網站ID,希望刪除他們所用的老舊AP。但是負責執行的團隊,誤以為要刪除這一批AP ID所在的網站ID。這就不只是刪除了AP,而是刪除了采用這些AP的企業所擁有的全部AP和數據。
4月5日7:38,開始執行舊版AP刪除腳本,工程團隊也沒有接到任何通知,警告有企業顧客的網站遭刪除,因為這是一只獲得合法授權的刪除。但是,不到10分鐘,就有企業發現自己所用的Jira網站失聯,提出第一張宕機支持工單。刪除腳本在8點多執行完畢,事后調查,一口氣刪除了775家企業所擁有的883個網站。受影響的產品包括了Jira 產品系列、Confluence文件協作平臺、Atlassian Access登入機制、Opsgenie 事件應變服務,甚至是網站狀態查詢頁Statuspage。這些受影響企業,不只無法連線登入,甚至連要檢視所用服務的運作狀態頁都打不開。
接連有不少顧客提出宕機工單,Atlassian決定在8:17啟動重大事件管理流程,也組織了跨部門事件管理團隊,找來工程部門、客戶支持團隊、項目管理團隊和對外溝通部門,聯手展開事故調查,每3小時開會一次,并在8:24將事件狀態提升到「危急」狀態。不到20分鐘,工程團隊就發現了事故的根本原因,是腳本誤刪數據而非黑客攻擊,9:03時首度在服務狀態網頁中揭露發生宕機事故。
找出事故原因之后,下一步就是要盡快解決問題,恢復顧客所訂閱的服務。Atlassian開始嘗試建立一套標準化的復原方法,但卻發現,要復原一個遭到刪除的網站,得建立新網站、復原每個下游產品、服務及還原數據所需的資料,還須與各網站所用第三方生態系廠商重建連結,相關復原步驟高達70個。他們才發現,要復原這些網站的復雜性遠超過他們的想像,所以在12:38時將這起事件的嚴重等級提升到「最高等級」,這時距離事故發生,已經超過了5小時。
Atlassian宕機后不久,越來越多顧客在Twitter上抱怨,因為Jira是許多企業用來管理敏捷開發項目的主要平臺,無法使用,就等于無法進行敏捷項目的開發,連要打開項目工單來知道該處理哪些工作都沒有辦法。這股抱怨聲浪越來越大,越來越多人發現,這起宕機事件持續時間越來越久,超過了8、9個小時,Atlassian所承諾的99.9%可用性承諾已經失守。
不少受影響的企業用戶在Twitter上抱怨,他們連要向Atlassian通報宕機問題,或是申請支持工單都做不到,也有人是發出申請后,遲遲沒有得到官方回應,仿佛Atlassian的服務窗口失聯一樣,無法通過原本的線上管道來接觸。
直到事故發生后17個小時,Atlassian才發電子郵件通知受影響顧客,并開始打電話聯系,對他們說明,而這時已經引起不少媒體的關注,開始大舉報導這起大宕機事件。
直到事件發生后快2天,Atlassian才發布第一份宕機事件的官方公開聲明。而Atlassian的合作伙伴,則還等到事故后第2天快結束時,才開始接到通知。因為宕機事故遲遲無法解決,Atlassian共同創辦人也以個人名義發信,親自向顧客說明復原進度緩慢的原因。
4月8日,也就是事件發生后的第四天,Atlassian終于成功復原了第一家受影響顧客的網站。可是,復原團隊這才發現,采用第一版復原方法,需要48小時才能恢復一批網站,因為需要大量人工操作,只能分批復原,若要全面復原剩下的網站,還需要3周時間,所以,也開始改良復原程序。同一天,Atlassian也對所有工程部門實施代碼凍結,禁止任何異動,來降低顧客數據不一致的變更風險
過了一天,4月9日開始啟用第二套復原方法,將原本70道程序,大幅減少到只剩下30道程序。第二套做法重建顧客網站時,不是建立新的網站ID,而是直接沿用了顧客的舊網站ID,因此,大幅減少新舊ID比對的步驟,也不用再逐一與第三方程式供應商溝通,節省大量時間。這時有771個誤刪網站,可以改用第二套方法來復原。
不過,第二套方法還是需要大量手動操作,直到4月11日,Atlassian工程團隊打造出自動化復原工具,來加速第二套方法的時間,才將復原時間縮短到12小時,這時候,Atlassian才在工單中向顧客承諾,可以在事故后2周內復原。
到了4月14日,采用第一版復原方法復原的網站達到112個網站,不再繼續使用。Atlassian也打造出復原網站的完整驗證腳本,不再需要人工驗證,更加快了其他網站的復原速度,到了4月16日10:05 ,就完成所有網站的復原和自動驗證,但還沒經過顧客確認。隔天21:48,最后一位受影響顧客完成復原確認。Atlassian就在4月18日1:00宣布,受影響網站100%復原。這時,距離事故發生已經近14天,不過,宣布當時,仍有57個網站,因為復原資料的時間點過早,比原訂「當機前5分鐘」的復原時間點,還要更早,還需要追補后來異動的資料。
到了4月底,Atlassian發布了四月大宕機事件的完整事后分析報告。