本文主要分享字節(jié)跳動在使用 Flink State 上的實踐經(jīng)驗,內(nèi)容包括 Flink State 相關實踐以及部分字節(jié)內(nèi)部在引擎上的優(yōu)化,希望可以給 Flink 用戶的開發(fā)及調(diào)優(yōu)提供一些借鑒意義。
前言
Flink 作業(yè)需要借助 State 來完成聚合、Join 等有狀態(tài)的計算任務,而 State 也一直都是作業(yè)調(diào)優(yōu)的一個重點。目前 State 和 Checkpoint 已經(jīng)在字節(jié)跳動內(nèi)部被廣泛使用,業(yè)務層面上 State 支持了數(shù)據(jù)集成、實時數(shù)倉、特征計算、樣本拼接等典型場景;作業(yè)類型上支持了 Map-Only 類型的通道任務、ETL 任務,窗口聚合計算的指標統(tǒng)計任務,多流 Join 等存儲數(shù)據(jù)明細的數(shù)據(jù)拼接任務。
以 WordCount 為例,假設我們需要統(tǒng)計 60 秒窗口內(nèi) Word 出現(xiàn)的次數(shù):
select
word,
TUMBLE_START(eventtime, INTERVAL '60' SECOND) as t,
count(1)
from
words_stream
group by
TUMBLE(eventtime, INTERVAL '60' SECOND), word
每個還未觸發(fā)的 60s 窗口內(nèi),每個 Word 對應的出現(xiàn)次數(shù)就是 Flink State,窗口每收到新的數(shù)據(jù)就會更新這個狀態(tài)直到最后輸出。為了防止作業(yè)失敗,狀態(tài)丟失,F(xiàn)link 引入了分布式快照 Checkpoint 的概念,定期將 State 持久化到 Hdfs 上,如果作業(yè) Failover,會從上一次成功的 checkpoint 恢復作業(yè)的狀態(tài)(比如 kafka 的 offset,窗口內(nèi)的統(tǒng)計數(shù)據(jù)等)。
在不同的業(yè)務場景下,用戶往往需要對 State 和 Checkpoint 機制進行調(diào)優(yōu),來保證任務執(zhí)行的性能和 Checkpoint 的穩(wěn)定性。閱讀下方內(nèi)容之前,我們可以回憶一下,在使用 Flink State 時是否經(jīng)常會面臨以下問題:
- 某個狀態(tài)算子出現(xiàn)處理瓶頸時,加資源也沒法提高性能,不知該如何排查性能瓶頸
- Checkpoint 經(jīng)常出現(xiàn)執(zhí)行效率慢,barrier 對齊時間長,頻繁超時的現(xiàn)象
- 大作業(yè)的 Checkpoint 產(chǎn)生過多小文件,對線上 HDFS 產(chǎn)生小文件壓力
- RocksDB 的參數(shù)過多,使用的時候不知該怎么選擇
- 作業(yè)擴縮容恢復時,恢復時間過長導致線上斷流
State 及 RocksDB 相關概念介紹
State 分類

由于 OperatorState 背后的 StateBackend 只有 DefaultOperatorStateBackend,所以用戶使用時通常指定的 FsStateBackend 和 RocksDBStateBackend 兩種,實際上指定的是 KeyedState 對應的 StateBackend 類型:
- FsStateBackend:DefaultOperatorStateBackend 和 HeapKeyedStateBackend 的組合
- RocksDBStateBackend:DefaultOperatorStateBackend 和 RocksDBKeyedStateBackend 的組合
RocksDB 介紹
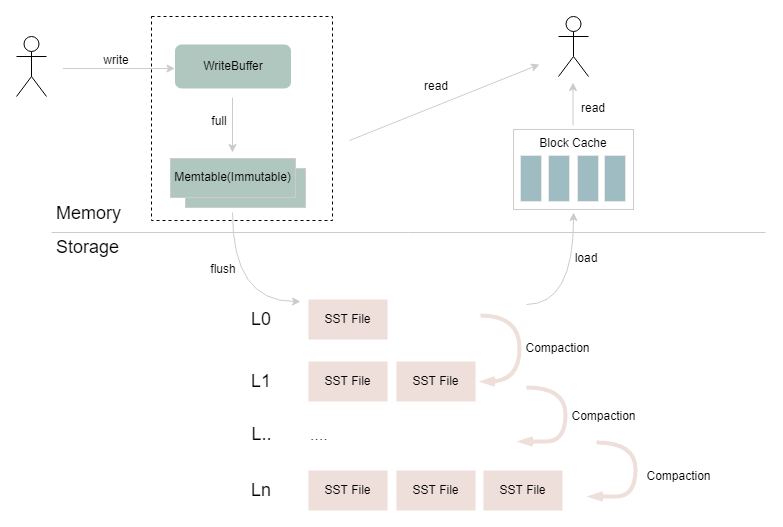
RocksDB 是嵌入式的 Key-Value 數(shù)據(jù)庫,在 Flink 中被用作 RocksDBStateBackend 的底層存儲。如下圖所示,RocksDB 持久化的 SST 文件在本地文件系統(tǒng)上通過多個層級進行組織,不同層級之間會通過異步 Compaction 合并重復、過期和已刪除的數(shù)據(jù)。在 RocksDB 的寫入過程中,數(shù)據(jù)經(jīng)過序列化后寫入到 WriteBuffer,WriteBuffer 寫滿后轉換為 Immutable Memtable 結構,再通過 RocksDB 的 flush 線程從內(nèi)存 flush 到磁盤上;讀取過程中,會先嘗試從 WriteBuffer 和 Immutable Memtable 中讀取數(shù)據(jù),如果沒有找到,則會查詢 Block Cache,如果內(nèi)存中都沒有的話,則會按層級查找底層的 SST 文件,并將返回的結果所在的 Data Block 加載到 Block Cache,返回給上層應用。
RocksDBKeyedStateBackend 增量快照介紹
這里介紹一下大家在大狀態(tài)場景下經(jīng)常需要調(diào)優(yōu)的 RocksDBKeyedStateBackend 增量快照。RocksDB 具有 append-only 特性,F(xiàn)link 利用這一特性將兩次 checkpoint 之間 SST 文件列表的差異作為狀態(tài)增量上傳到分布式文件系統(tǒng)上,并通過 JobMaster 中的 SharedStateRegistry 進行狀態(tài)的注冊和過期。
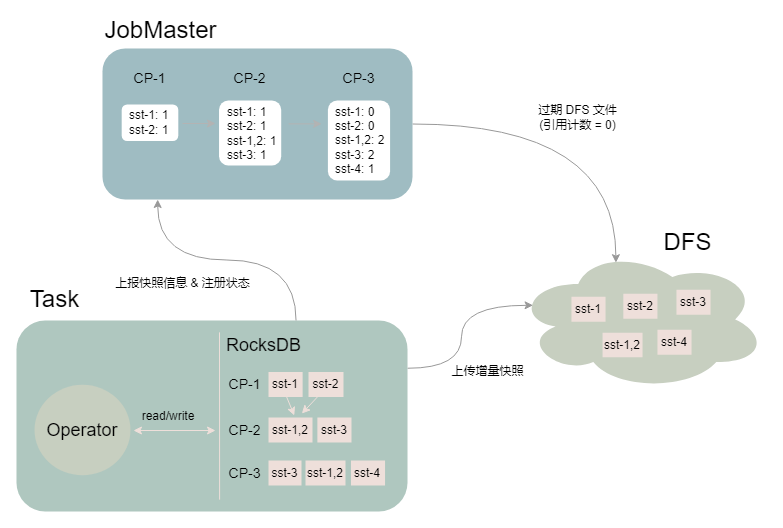
如上圖所示,Task 進行了 3 次快照(假設作業(yè)設置保留最近 2 次 Checkpoint):
- CP-1:RocksDB 產(chǎn)生 sst-1 和 sst-2 兩個文件,Task 將文件上傳至 DFS,JM 記錄 sst 文件對應的引用計數(shù)
- CP-2:RocksDB 中的 sst-1 和 sst-2 通過 compaction 生成了 sst-1,2,并且新生成了 sst-3 文件,Task 將兩個新增的文件上傳至 DFS,JM 記錄 sst 文件對應的引用計數(shù)
- CP-3:RocksDB 中新生成 sst-4 文件,Task 將增量的 sst-4 文件上傳至 DFS,且在 CP-3 完成后,由于只保留最近 2 次 CP,JobMaster 將 CP-1 過期,同時將 CP-1 中的 sst 文件對應的引用計數(shù)減 1,并刪除引用計數(shù)歸 0 的 sst 文件(sst-1 和 sst-2)
增量快照涉及到 Task 多線程上傳/下載增量文件,JobMaster 引用計數(shù)統(tǒng)計,以及大量與分布式文件系統(tǒng)的交互等過程,相對其他的 StateBackend 要更為復雜,在 100+GB 甚至 TB 級別狀態(tài)下,作業(yè)比較容易出現(xiàn)性能和穩(wěn)定性瓶頸的問題。
State 實踐經(jīng)驗
提升 State 操作性能
用戶在使用 State 時,會發(fā)現(xiàn)操作 State 并不是一件很"容易"的事情,如果使用 FsStateBackend,會經(jīng)常遇到 GC 問題、頻繁調(diào)參等問題;如果使用 RocksDBStateBackend,涉及到磁盤讀寫,對象序列化,在缺乏相關 Metrics 的情況下又不是很容易進行性能問題的定位,或者面對 RocksDB 的大量參數(shù)不知道如何調(diào)整到最優(yōu)。
目前字節(jié)跳動內(nèi)有 140+ 作業(yè)的狀態(tài)大小達到了 TB 級別,單作業(yè)的最大狀態(tài)為 60TB,在逐步支持大狀態(tài)作業(yè)的實踐中,我們積累了一些 State 的調(diào)優(yōu)經(jīng)驗,也做了一些引擎?zhèn)鹊母脑煲灾С指玫男阅芎徒档妥鳂I(yè)調(diào)優(yōu)成本。
選擇合適的 StateBackend
我們都知道 FsStateBackend 適合小狀態(tài)的作業(yè),而 RocksDBStateBackend 適合大狀態(tài)的作業(yè),但在實際選擇 FsStateBackend 時會遇到以下問題:
- 進行開發(fā)之前,對狀態(tài)大小無法做一個準確的預估,或者做狀態(tài)大小預估的復雜度較高
- 隨著業(yè)務增長,所謂的 "小狀態(tài)" 很快就變成了 "大狀態(tài)",需要人工介入做調(diào)整
- 同樣的狀態(tài)大小,由于狀態(tài)過期時間不同,使用 FsStateBackend 產(chǎn)生 GC 壓力也不同
針對上面 FsStateBackend 中存在的若干個問題,可以看出 FsStateBackend 的維護成本還是相對較高的。在字節(jié)內(nèi)部,我們暫時只推薦部分作業(yè)總狀態(tài)小于 1GB 的作業(yè)使用 FsStateBackend,而對于大流量業(yè)務如短視頻、直播、電商等,我們更傾向于推薦用戶使用 RocksDBStateBackend 以減少未來的 GC 風險,獲得更好的穩(wěn)定性。
隨著內(nèi)部硬件的更新迭代,ssd 的推廣,長遠來看我們更希望將 StateBackend 收斂到 RocksDBStateBackend 來提高作業(yè)穩(wěn)定性和減少用戶運維成本;性能上期望在小狀態(tài)場景下,RocksDBStateBackend 可以和 FsStateBackend 做到比較接近或者打平。
觀測性能指標,使用火焰圖分析瓶頸
社區(qū)版本的 Flink 使用 RocksDBStateBackend 時,如果遇到性能問題,基本上是很難判斷出問題原因,此時建議打開相關指標進行排查[1]。另外,在字節(jié)跳動內(nèi)部,造成 RocksDBStateBackend 性能瓶頸的原因較多,我們構建了一套較為完整的 RocksDB 指標體系,并在 Flink 層面上默認透出了部分關鍵的 RocksDB 指標,并新增了 State 相關指標,部分指標的示意圖如下:
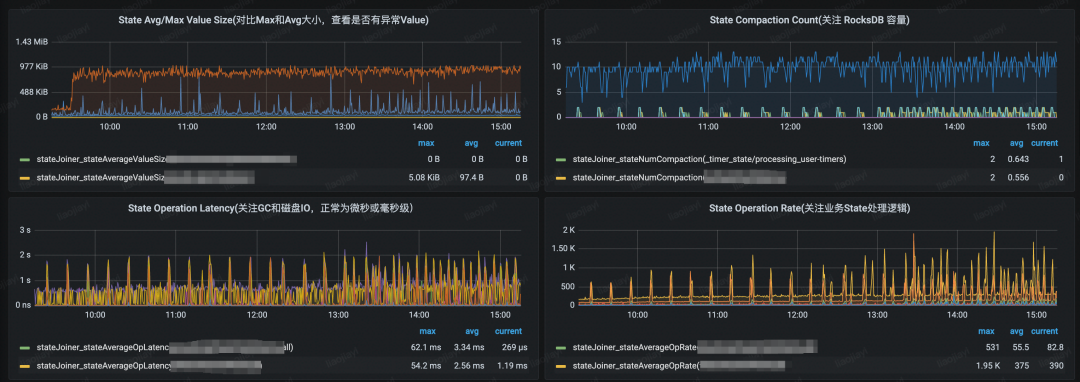
造成 RocksDB 性能瓶頸的常見如下:
- 單條記錄的 State Size 過大,由于 RocksDB 的 append-only 的特性,write buffer 很容易打滿,造成數(shù)據(jù)頻繁刷盤和 Compaction,搶占作業(yè) CPU
- Operator 內(nèi)部的 RocksDB 容量過大,如 Operator 所在的 RocksDB 實例大小超過 15GB 我們就會比較明顯地看到 Compaction 更加頻繁,并且造成 RocksDB 頻繁的 Write Stall
- 硬件問題,如磁盤 IO 打滿,從 State 操作的 Latency 指標可以看出來,如果長時間停留在秒級別,說明硬件或者機器負載偏高
除了以上指標外,另外一個可以相配合的方法是火焰圖,常見方法比如使用阿里的 arthas[2]。火焰圖內(nèi)部會展示 Flink 和 RocksDB 的 CPU 開銷,示意圖如下:

如上所示,可以看出火焰圖中 Compaction 開銷是占比非常大的,定位到 Compaction 問題后,我們可以再根據(jù) Value Size、RocksDB 容量大小、作業(yè)并行度和資源等進行進一步的分析。
使用合理的 RocksDB 參數(shù)
除了 Flink 中提供的 RocksDB 參數(shù)[3]之外,RocksDB 還有很多調(diào)優(yōu)參數(shù)可供用戶使用。用戶可以通過自定義 RocksDBOptionsFactory 來做 RocksDB 的調(diào)優(yōu)[4]。經(jīng)過內(nèi)部的一些實踐,我們列舉兩個比較有效的參數(shù):
- 關閉 RocksDB 的 compression(需要自定義 RocksDBOptionsFactory):RocksDB 默認使用 snappy 算法對數(shù)據(jù)進行壓縮,由于 RocksDB 的讀寫、Compaction 都存在壓縮的相關操作,所以在對 CPU 敏感的作業(yè)中,可以通過ColumnFamilyOptions.setCompressionType(CompressionType.NO_COMPRESSION) 將壓縮關閉,采用磁盤空間容量換 CPU 的方式來減少 CPU 的損耗
- 開啟 RocksDB 的 bloom-filter(需要自定義 RocksDBOptionsFactory):RocksDB 默認不使用 bloom-filter[5],開啟 bloom-filter 后可以節(jié)省一部分 RocksDB 的讀開銷
- 其他 cache、writebuffer 和 flush/compaction 線程數(shù)的調(diào)整,同樣可以在不同場景下獲得不同的收益,比如在寫少多讀的場景下,我們可以通過調(diào)大 Cache 來減少磁盤 IO
這里要注意一點,由于很多參數(shù)都以內(nèi)存或磁盤來換取性能上的提高,所以以上參數(shù)的使用需要結合具體的性能瓶頸分析才能達到最好的效果,比如在上方的火焰圖中可以明顯地看到 snappy 的壓縮占了較大的 CPU 開銷,此時可以嘗試 compression 相關的參數(shù)。
關注 RocksDBStateBackend 的序列化開銷
使用 RocksDB State 的相關 API,Key 和 Value 都是需要經(jīng)過序列化和反序列化,如果 Java 對象較復雜,并且用戶沒有自定義 Serializer,那么它的序列化開銷也會相對較大。比如去重操作中常用的 RoaringBitmap,在序列化和反序列化時,MB 級別的對象的序列化開銷達到秒級別,這對于作業(yè)性能是非常大的損耗。因此對于復雜對象,我們建議:
- 業(yè)務上嘗試在 State 中使用更精簡的數(shù)據(jù)結構,去除不需要存儲的字段
- StateDescriptor 中通過自定義 Serializer 來減小序列化開銷
- 在 KryoSerializer 顯式注冊 PB/Thrift Serializer[6]
- 減小 State 的操作次數(shù),比如下方的示例代碼,如果是使用 FsStateBackend ,則沒有太多性能損耗;但是在 RocksDBStateBackend 上因為兩次 State 的操作導致 userKey 產(chǎn)生了額外一次序列化的開銷,如果 userKey 本身是個相對復雜的對象就要注意了
if (mapState.contains(userKey)) {
UV userValue = mapState.get(userKey);
}更多關于序列化的性能和指導可以參考社區(qū)的調(diào)優(yōu)文檔[7]。
構建 RocksDB State 的緩存
上面提到 RocksDB 的序列化開銷可能會比較大,字節(jié)跳動內(nèi)部在 StateBackend 和 Operator 中間構建了 StateBackend Cache Layer,負責緩存算子內(nèi)部的熱點數(shù)據(jù),并且根據(jù) GC 情況進行動態(tài)擴縮容,對于有熱點的作業(yè)收益明顯。
同樣,對于用戶而言,如果作業(yè)熱點明顯的話,可以嘗試在內(nèi)存中構建一個簡單的 Java 對象的緩存,但是需要注意以下幾點:
- 控制緩存的閾值,防止緩存對象過多造成 GC 壓力過大
- 注意緩存中 State TTL 邏輯處理,防止出現(xiàn)臟讀的情況
降低 Checkpoint 耗時
Checkpoint 持續(xù)時間和很多因素相關,比如作業(yè)反壓、資源是否足夠等,在這里我們從 StateBackend 的角度來看看如何提高 Checkpoint 的成功率。一次 Task 級別的快照可以劃分為以下幾個步驟:

等待 checkpointLock:Source Task 中,觸發(fā) Checkpoint 的 Rpc 線程需要等待 Task 線程完成當前數(shù)據(jù)處理后,釋放 checkpointLock 后才能觸發(fā) checkpoint,這一步的耗時主要取決于用戶的處理邏輯及每條數(shù)據(jù)的處理時延
收集 Barrier: 非 Source 的 Task 中,這一步是將上游所有 Task 發(fā)送的 checkpoint barrier 收集齊,這一步的耗時主要在 barrier 在 buffer 隊列中的排隊時間
同步階段:執(zhí)行用戶自定義的 snapshot 方法以及 StateBackend 上的元信息快照,比如 FsStateBackend 在同步階段會對內(nèi)存中的狀態(tài)結構做淺拷貝
異步階段:將狀態(tài)數(shù)據(jù)或文件上傳到 DFS
字節(jié)跳動內(nèi)部,我們也針對這四個步驟構建了相關的監(jiān)控看板:
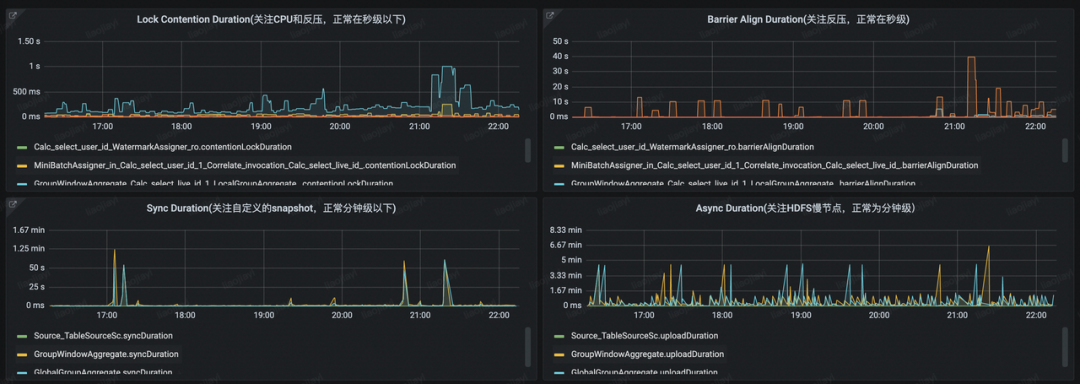
生產(chǎn)環(huán)境中,「等待 checkpointLock」和「同步階段」更多是在業(yè)務邏輯上的耗時,通常耗時也會相對較短;從 StateBackend 的層面上,我們可以對「收集 Barrier」和「異步階段」這兩個階段進行優(yōu)化來降低 Checkpoint 的時長。
減少 Barrier 對齊時間
減少 Barrier 對齊時間的核心是降低 in-flight 的 Buffer 總大小,即使是使用社區(qū)的 Unaligned Checkpoint 特性,如果 in-flight 的 Buffer 數(shù)量過多,會導致最后寫入到分布式存儲的狀態(tài)過大,有時候 in-flight 的 Buffer 大小甚至可能超過 State 本身的大小,反而會對異步階段的耗時產(chǎn)生負面影響。
- 降低 channel 中 Buffer 的數(shù)量:Flink 1.11 版本支持在數(shù)據(jù)傾斜的環(huán)境下限制單個 channel 的最大 Buffer 數(shù)量,可以通過 taskmanager.network.memory.max-buffers-per-channel 參數(shù)進行調(diào)整
- 降低單個 Buffer 的大小:如果單條數(shù)據(jù) Size 在 KB 級別以下,我們可以通過降低 taskmanager.memory.segment-size 來減少單個 Buffer 的大小,從而減少 Barrier 的排隊時間
結合業(yè)務場景降低 DFS 壓力
如果在你的集群中,所有 Flink 作業(yè)都使用同一個 DFS 集群,那么業(yè)務增長到一定量級后,DFS 的 IO 壓力和吞吐量會成為「異步階段」中非常重要的一個參考指標。尤其是在 RocksDBStateBackend 的增量快照中,每個 Operator 產(chǎn)生的狀態(tài)文件會上傳到 DFS中,上傳文件的數(shù)量和作業(yè)并行度、作業(yè)狀態(tài)大小呈正比。而在 Flink 并行度較高的作業(yè)中,由于各個 Task 的快照基本都在同一時間發(fā)生,所以幾分鐘內(nèi),對 DFS 的寫請求數(shù)往往能夠達到幾千甚至上萬。
合理設置 state.backend.fs.memory-threshold 減小 DFS 文件數(shù)量:此參數(shù)表示生成 DFS 文件的最小閾值,小于此閾值的狀態(tài)會以 byte[] 的形式封裝在 RPC 請求內(nèi)傳給 JobMaster 并持久化在 _metadata 里)。
- 對于 Map-Only 類型的任務,通常狀態(tài)中存儲的是元信息相關的內(nèi)容(如 Kafka 的消費位移),狀態(tài)相對較小,我們可以通過調(diào)大此參數(shù)避免將這些狀態(tài)落盤。Flink 1.11 版本之前,state.backend.fs.memory-threshold 默認的 1kb 閾值較小,比較容易地導致每個并行度都需要上傳自己的狀態(tài)文件,上傳文件個數(shù)和并行度成正比。我們可以結合業(yè)務場景調(diào)整此參數(shù),將 DFS 的請求數(shù)從 N(N=并行度) 次優(yōu)化到 1 次
- 這里需要注意,如果閾值設置過高(MB級別),可能會導致 _metadata 過大,從而增大 JobMaster 恢復 Checkpoint 元信息和部署 Task 時的 GC 壓力,導致 JobMaster 頻繁 Full GC
合理設置 state.backend.rocksdb.checkpoint.transfer.thread.num 線程數(shù)減少 DFS 壓力:此參數(shù)表示制作快照時上傳和恢復快照時下載 RocksDB 狀態(tài)文件的線程數(shù)。
- 在狀態(tài)較大的情況下,用戶為了提高 Checkpoint 效率,可能會將此線程數(shù)設置的比較大,比如超過 10,在這種情況下快照制作和快照恢復都會給 DFS 帶來非常大的瞬時壓力,尤其是對 HDFS NameNode,很有可能瞬間占滿 NameNode 的請求資源,影響其他正在執(zhí)行的作業(yè)
調(diào)大 state.backend.rocksdb.writebuffer.size:此參數(shù)表示 RocksDB flush 到磁盤之前,在內(nèi)存中存儲的數(shù)據(jù)大小。
- 如果作業(yè)的吞吐比較高,Update 比較頻繁,造成了 RocksDB 目錄下的文件過多,通過調(diào)大此參數(shù)可以一定程度上通過加大文件大小來減少上傳的文件數(shù)量,減少 DFS IO 次數(shù)。
合并 RocksDBKeyedStateBackend 上傳的文件(FLINK-11937)
在社區(qū)版本的增量快照中,RocksDB 新生成的每個 SST 文件都需要上傳到 DFS,以 HDFS 為例,HDFS 的默認 Block 大小通常在 100+MB(字節(jié)跳動內(nèi)部是 512MB),而 RocksDB 生成的文件通常為 100MB 以下,對于小數(shù)據(jù)量的任務甚至是 KB 級別的文件大小,Checkpoint 產(chǎn)生的大量且頻繁的小文件請求,對于 HDFS 的元數(shù)據(jù)管理和 NameNode 訪問都會產(chǎn)生比較大的壓力。
社區(qū)在 FLINK-11937 中提出了將小文件合并上傳的思路,類似的,在字節(jié)內(nèi)部的實現(xiàn)中,我們將小文件合并的邏輯抽象成 Strategy,這樣我們可以根據(jù) SST 文件數(shù)量、大小、存活時長等因素實現(xiàn)符合我們自己業(yè)務場景的上傳策略。
提高 StateBackend 恢復速度
除了 State 性能以及 DFS 瓶頸之外,StateBackend 的恢復速度也是實際生產(chǎn)過程中考慮的一個很重要的點,我們在生產(chǎn)過程中會發(fā)現(xiàn),由于某些參數(shù)的設置不合理,改變作業(yè)配置和并發(fā)度會導致作業(yè)在重啟時,從快照恢復時性能特別差,恢復時間長達十分鐘以上。
謹慎使用 Union State
Union State 的特點是在作業(yè)恢復時,每個并行度恢復的狀態(tài)是所有并行度狀態(tài)的并集,這種特性導致 Union State 在 JobMaster 狀態(tài)分配和 TaskManager 狀態(tài)恢復上都比較重:
- JobMaster 需要完成一個 NN 的遍歷,將每個并行度的狀態(tài)都賦值成所有并行度狀態(tài)的并集。(這里實際上可以使用 HashMap 將遍歷優(yōu)化成 N1 的復雜度[8])
- TaskManager 需要讀取全量 Union State 的狀態(tài)文件,比如 1000 并行度的作業(yè)在恢復時,每個并行度中的 Union State 在恢復狀態(tài)時都需要讀取 1000 個并行度 Operator 所產(chǎn)生的狀態(tài)文件,這個操作是非常低效的。(我們內(nèi)部的優(yōu)化是將 Union State 狀態(tài)在 JobMaster 端聚合成 1 個文件,這樣 TaskManager 在恢復時只需要讀取一個文件即可)
Union State 在實際使用中,除恢復速度慢的問題外,如果使用不當,對于 DFS 也會產(chǎn)生大量的壓力,所以建議在高并行度的作業(yè)中,盡量避免使用 Union State 以降低額外的運維負擔。
增量快照 vs 全量快照恢復
RocksDBStateBackend 中支持的增量快照和全量快照(或 Savepoint),這兩種快照的差異導致了它們在不同場景下的恢復速度也不同。其中增量快照是將 RocksDB 底層的增量 SST 文件上傳到 DFS;而全量快照是遍歷 RocksDB 實例的 Key-Value 并寫入到 DFS。
以是否擴縮容來界定場景,這兩種快照下的恢復速度如下:

非擴縮容場景:
- 增量快照的恢復只需將 SST 文件拉到本地即可完成 RocksDB 的初始化*(多線程)
- 全量快照的恢復需要遍歷屬于當前 Subtask 的 KeyGroup Range 下的所有鍵值對,寫入到本地磁盤并完成 RocksDB 初始化(單線程)
擴縮容場景:
- 增量快照的恢復涉及到多組 RocksDB 的數(shù)據(jù)合并,涉及到多組 RocksDB 文件的下載以及寫入到同一個 RocksDB 中產(chǎn)生的大量 Compaction,Compaction 過程中會產(chǎn)生嚴重的寫放大
- 全量快照的恢復和上面的非擴縮容場景一致(單線程)
這里比較麻煩的一點是擴縮容恢復時比較容易遇到長尾問題,由于單個并行度狀態(tài)過大而導致整體恢復時間被拉長,目前在社區(qū)版本下還沒有比較徹底的解決辦法,我們也在針對大狀態(tài)的作業(yè)進行恢復速度的優(yōu)化,在這里基于社區(qū)已支持的功能,在擴縮容場景下給出一些加快恢復速度的建議:
- 擴縮容恢復時盡量選擇從 Savepoint 進行恢復,可以避免增量快照下多組 Task 的 RocksDB 實例合并產(chǎn)生的 Compaction 開銷
- 調(diào)整 RocksDB 相關參數(shù),調(diào)大 WriteBuffer 大小和 Flush/Compaction 線程數(shù),增強 RocksDB 批量將數(shù)據(jù)刷盤的能力

總結
本篇文章中,我們介紹了 State 和 RocksDB 的相關概念,并針對字節(jié)跳動內(nèi)部在 State 應用上遇到的問題,給出了相關實踐的建議,希望大家在閱讀本篇文章之后,對于 Flink State 在日常開發(fā)工作中的應用,會有更加深入的認識和了解。