Apache Flink 漫談系列(04) - State
實際問題
在流計算場景中,數據會源源不斷的流入Apache Flink系統,每條數據進入Apache Flink系統都會觸發計算。如果我們想進行一個Count聚合計算,那么每次觸發計算是將歷史上所有流入的數據重新新計算一次,還是每次計算都是在上一次計算結果之上進行增量計算呢?答案是肯定的,Apache Flink是基于上一次的計算結果進行增量計算的。那么問題來了: "上一次的計算結果保存在哪里,保存在內存可以嗎?",答案是否定的,如果保存在內存,在由于網絡,硬件等原因造成某個計算節點失敗的情況下,上一次計算結果會丟失,在節點恢復的時候,就需要將歷史上所有數據(可能十幾天,上百天的數據)重新計算一次,所以為了避免這種災難性的問題發生,Apache Flink 會利用State存儲計算結果。本篇將會為大家介紹Apache Flink State的相關內容。
什么是State
這個問題似乎有些"***"?不管問題的答案是否顯而易見,但我還是想簡單說一下在Apache Flink里面什么是State?State是指流計算過程中計算節點的中間計算結果或元數據屬性,比如 在aggregation過程中要在state中記錄中間聚合結果,比如 Apache Kafka 作為數據源時候,我們也要記錄已經讀取記錄的offset,這些State數據在計算過程中會進行持久化(插入或更新)。所以Apache Flink中的State就是與時間相關的,Apache Flink任務的內部數據(計算數據和元數據屬性)的快照。
為什么需要State
與批計算相比,State是流計算特有的,批計算沒有failover機制,要么成功,要么重新計算。流計算在 大多數場景 下是增量計算,數據逐條處理(大多數場景),每次計算是在上一次計算結果之上進行處理的,這樣的機制勢必要將上一次的計算結果進行存儲(生產模式要持久化),另外由于 機器,網絡,臟數據等原因導致的程序錯誤,在重啟job時候需要從成功的檢查點(checkpoint,后面篇章會專門介紹)進行state的恢復。增量計算,Failover這些機制都需要state的支撐。
State 實現
Apache Flink內部有四種state的存儲實現,具體如下:
- 基于內存的HeapStateBackend - 在debug模式使用,不 建議在生產模式下應用;
- 基于HDFS的FsStateBackend - 分布式文件持久化,每次讀寫都產生網絡IO,整體性能不佳;
- 基于RocksDB的RocksDBStateBackend - 本地文件+異步HDFS持久化;
- 還有一個是基于Niagara(Alibaba對 Apache Flink的增強)NiagaraStateBackend - 分布式持久化- 在Alibaba生產環境應用;
State 持久化邏輯
Apache Flink版本選擇用RocksDB+HDFS的方式進行State的存儲,State存儲分兩個階段,首先本地存儲到RocksDB,然后異步的同步到遠程的HDFS。 這樣而設計既消除了HeapStateBackend的局限(內存大小,機器壞掉丟失等),也減少了純分布式存儲的網絡IO開銷。

State 分類
Apache Flink 內部按照算子和數據分組角度將State劃分為如下兩類:
- KeyedState - 這里面的key是我們在SQL語句中對應的GroupBy/PartitioneBy里面的字段,key的值就是groupby/PartitionBy字段組成的Row的字節數組,每一個key都有一個屬于自己的State,key與key之間的State是不可見的;
- OperatorState - Apache Flink內部的Source Connector的實現中就會用OperatorState來記錄source數據讀取的offset。
State 擴容重新分配
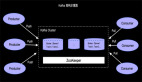
Apache Flink是一個大規模并行分布式系統,允許大規模的有狀態流處理。 為了可伸縮性,Apache Flink作業在邏輯上被分解成operator graph,并且每個operator的執行被物理地分解成多個并行運算符實例。 從概念上講,Apache Flink中的每個并行運算符實例都是一個獨立的任務,可以在自己的機器上調度到網絡連接的其他機器運行。
Apache Flink的DAG圖中只有邊相連的節點🈶網絡通信,也就是整個DAG在垂直方向有網絡IO,在水平方向如下圖的stateful節點之間沒有網絡通信,這種模型也保證了每個operator實例維護一份自己的state,并且保存在本地磁盤(遠程異步同步)。通過這種設計,任務的所有狀態數據都是本地的,并且狀態訪問不需要任務之間的網絡通信。 避免這種流量對于像Apache Flink這樣的大規模并行分布式系統的可擴展性至關重要。
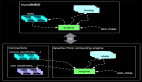
如上我們知道Apache Flink中State有OperatorState和KeyedState,那么在進行擴容時候(增加并發)State如何分配呢?比如:外部Source有5個partition,在Apache Flink上面由Srouce的1個并發擴容到2個并發,中間Stateful Operation 節點由2個并發并擴容的3個并發,如下圖所示:

在Apache Flink中對不同類型的State有不同的擴容方法,接下來我們分別介紹。
OperatorState對擴容的處理
我們選取Apache Flink中某個具體Connector實現實例進行介紹,以MetaQ為例,MetaQ以topic方式訂閱數據,每個topic會有N>0個分區,以上圖為例,加上我們訂閱的MetaQ的topic有5個分區,那么當我們source由1個并發調整為2個并發時候,State是怎么恢復的呢?
state 恢復的方式與Source中OperatorState的存儲結構有必然關系,我們先看MetaQSource的實現是如何存儲State的。首先MetaQSource 實現了ListCheckpointed
- public interface ListCheckpointed<T extends Serializable> {
- List<T> snapshotState(long var1, long var3) throws Exception;
- void restoreState(List<T> var1) throws Exception;}
我們發現 snapshotState方法的返回值是一個List
- public interface InputSplit extends Serializable {
- int getSplitNumber();
- }
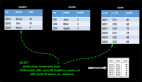
也就是說,InputSplit我們可以理解為是一個Partition索引,有了這個數據結構我們在看看上面圖所示的case是如何工作的?當Source的并行度是1的時候,所有打partition數據都在同一個線程中讀取,所有partition的state也在同一個state中維護,State存儲信息格式如下:

如果我們現在將并發調整為2,那么我們5個分區的State將會在2個獨立的任務(線程)中進行維護,在內部實現中我們有如下算法進行分配每個Task所處理和維護partition的State信息,如下:
- List<Integer> assignedPartitions = new LinkedList<>();
- for (int i = 0; i < partitions; i++) {
- if (i % consumerCount == consumerIndex) {
- assignedPartitions.add(i);
- }
- }
這個求mod的算法,決定了每個并發所處理和維護partition的State信息,針對我們當前的case具體的存儲情況如下:
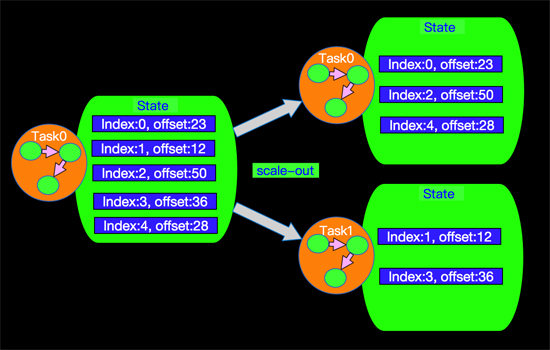
那么到現在我們發現上面擴容后State得以很好的分配得益于OperatorState采用了List
KeyedState對擴容的處理
對于KeyedState最容易想到的是hash(key) mod parallelism(operator) 方式分配state,就和OperatorState一樣,這種分配方式大多數情況是恢復的state不是本地已有的state,需要一次網絡拷貝,這種效率比較低,OperatorState采用這種簡單的方式進行處理是因為OperatorState的state一般都比較小,網絡拉取的成本很小,對于KeyedState往往很大,我們會有更好的選擇,在Apache Flink中采用的是Key-Groups方式進行分配。
什么是Key-Groups
Key-Groups 是Apache Flink中對keyed state按照key進行分組的方式,每個key-group中會包含N>0個key,一個key-group是State分配的原子單位。在Apache Flink中關于Key-Group的對象是 KeyGroupRange, 如下:
- public class KeyGroupRange implements KeyGroupsList, Serializable {
- ...
- ...
- private final int startKeyGroup;
- private final int endKeyGroup;
- ...
- ...}
KeyGroupRange兩個重要的屬性就是 startKeyGroup和endKeyGroup,定義了startKeyGroup和endKeyGroup屬性后Operator上面的Key-Group的個數也就確定了。
什么決定Key-Groups的個數
key-group的數量在job啟動前必須是確定的且運行中不能改變。由于key-group是state分配的原子單位,而每個operator并行實例至少包含一個key-group,因此operator的***并行度不能超過設定的key-group的個數,那么在Apache Flink的內部實現上key-group的數量就是***并行度的值。
GroupRange.of(0, maxParallelism)如何決定key屬于哪個Key-Group
確定好GroupRange之后,如何決定每個Key屬于哪個Key-Group呢?我們采取的是取mod的方式,在KeyGroupRangeAssignment中的assignToKeyGroup方法會將key劃分到指定的key-group中,如下:
- public static int assignToKeyGroup(Object key, int maxParallelism) {
- return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism);
- }
- public static int computeKeyGroupForKeyHash(int keyHash, int maxParallelism) {
- return HashPartitioner.INSTANCE.partition(keyHash, maxParallelism);
- }
- @Override
- public int partition(T key, int numPartitions) {
- return MathUtils.murmurHash(Objects.hashCode(key)) % numPartitions;
- }
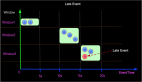
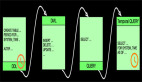
如上實現我們了解到分配Key到指定的key-group的邏輯是利用key的hashCode和maxParallelism進行取余操作來分配的。如下圖當parallelism=2,maxParallelism=10的情況下流上key與key-group的對應關系如下圖所示:
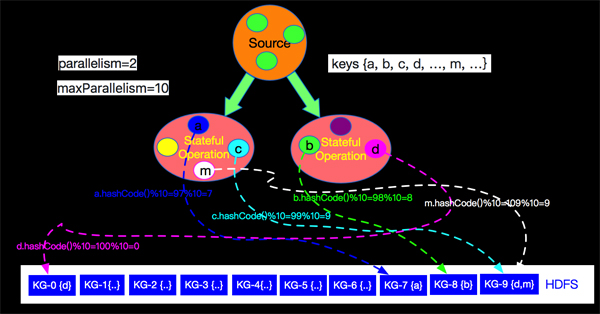
如上圖key(a)的hashCode是97,與***并發10取余后是7,被分配到了KG-7中,流上每個event都會分配到KG-0至KG-9其中一個Key-Group中。
每個Operator實例如何獲取Key-Groups
了解了Key-Groups概念和如何分配每個Key到指定的Key-Groups之后,我們看看如何計算每個Operator實例所處理的Key-Groups。 在KeyGroupRangeAssignment的computeKeyGroupRangeForOperatorIndex方法描述了分配算法:
- public static KeyGroupRange computeKeyGroupRangeForOperatorIndex(
- int maxParallelism,
- int parallelism,
- int operatorIndex) {
- GroupRange splitRange = GroupRange.of(0, maxParallelism).getSplitRange(parallelism, operatorIndex);
- int startGroup = splitRange.getStartGroup();
- int endGroup = splitRange.getEndGroup();
- return new KeyGroupRange(startGroup, endGroup - 1);
- }
- public GroupRange getSplitRange(int numSplits, int splitIndex) {
- ...
- final int numGroupsPerSplit = getNumGroups() / numSplits;
- final int numFatSplits = getNumGroups() % numSplits;
- int startGroupForThisSplit;
- int endGroupForThisSplit;
- if (splitIndex < numFatSplits) {
- startGroupForThisSplit = getStartGroup() + splitIndex * (numGroupsPerSplit + 1);
- endGroupForThisSplit = startGroupForThisSplit + numGroupsPerSplit + 1;
- } else {
- startGroupForThisSplit = getStartGroup() + splitIndex * numGroupsPerSplit + numFatSplits;
- endGroupForThisSplit = startGroupForThisSplit + numGroupsPerSplit;
- }
- if (startGroupForThisSplit >= endGroupForThisSplit) {
- return GroupRange.emptyGroupRange();
- } else {
- return new GroupRange(startGroupForThisSplit, endGroupForThisSplit);
- }}
上面代碼的核心邏輯是先計算每個Operator實例至少分配的Key-Group個數,將不能整除的部分N個,平均分給前N個實例。最終每個Operator實例管理的Key-Groups會在GroupRange中表示,本質是一個區間值;下面我們就上圖的case,說明一下如何進行分配以及擴容后如何重新分配。
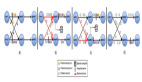
假設上面的Stateful Operation節點的***并行度maxParallelism的值是10,也就是我們一共有10個Key-Group,當我們并發是2的時候和并發是3的時候分配的情況如下圖:
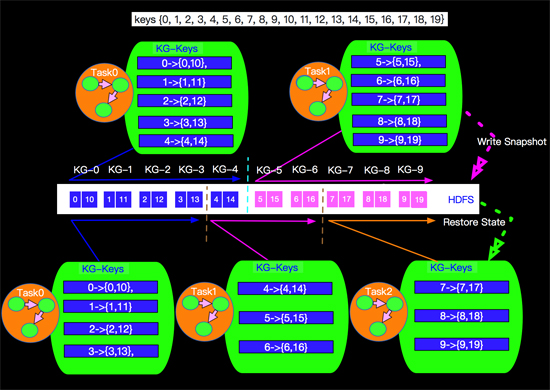
如上算法我們發現在進行擴容時候,大部分state還是落到本地的,如Task0只有KG-4被分出去,其他的還是保持在本地。同時我們也發現,一個job如果修改了maxParallelism的值那么會直接影響到Key-Groups的數量和key的分配,也會打亂所有的Key-Group的分配,目前在Apache Flink系統中統一將maxParallelism的默認值調整到4096,***程度的避免無法擴容的情況發生。
小結
本篇簡單介紹了Apache Flink中State的概念,并重點介紹了OperatorState和KeyedState在擴容時候的處理方式。Apache Flink State是支撐Apache Flink中failover,增量計算,Window等重要機制和功能的核心設施。后續介紹failover,增量計算,Window等相關篇章中也會涉及State的利用,當涉及到本篇沒有覆蓋的內容時候再補充介紹。同時本篇沒有介紹Alibaba對Apache Flink的增強的Niagara版本的State。Niagara是Alibaba精心打造的新一代適用于流計算場景的StateBackend存儲實現,相關內容后續在合適時間再向大家介紹。
關于點贊和評論
本系列文章難免有很多缺陷和不足,真誠希望讀者對有收獲的篇章給予點贊鼓勵,對有不足的篇章給予反饋和建議,先行感謝大家!
作者:孫金城,花名 金竹,目前就職于阿里巴巴,自2015年以來一直投入于基于Apache Flink的阿里巴巴計算平臺Blink的設計研發工作。
【本文為51CTO專欄作者“金竹”原創稿件,轉載請聯系原作者】