提升支付寶搜索體驗(yàn),螞蟻、北大基于層次化對(duì)比學(xué)習(xí)文本生成框架
文本生成任務(wù)通常采用 teacher forcing 的方式進(jìn)行訓(xùn)練,這種訓(xùn)練方式使得模型在訓(xùn)練過(guò)程中只能見(jiàn)到正樣本。然而生成目標(biāo)與輸入之間通常會(huì)存在某些約束,這些約束通常由句子中的關(guān)鍵元素體現(xiàn),例如在 query 改寫任務(wù)中,“麥當(dāng)勞點(diǎn)餐” 不能改成 “肯德基點(diǎn)餐”,這里面起到約束作用的關(guān)鍵元素是品牌關(guān)鍵詞。通過(guò)引入對(duì)比學(xué)習(xí)給生成的過(guò)程中加入負(fù)樣本的模式使得模型能夠有效地學(xué)習(xí)到這些約束。
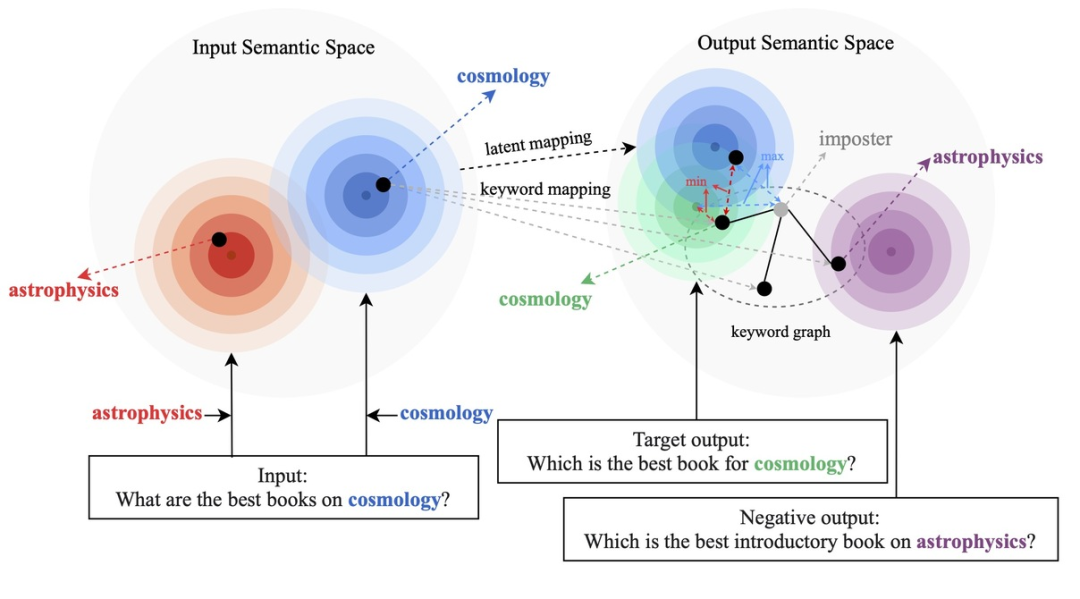
現(xiàn)有的基于對(duì)比學(xué)習(xí)方法主要集中在整句層面實(shí)現(xiàn) [1][2],而忽略了句子中的詞粒度的實(shí)體的信息,下圖中的例子展示了句子中關(guān)鍵詞的重要意義,對(duì)于一個(gè)輸入的句子,如果對(duì)它的關(guān)鍵詞進(jìn)行替換(e.g. cosmology->astrophysics),句子的含義會(huì)發(fā)生變化,從而在語(yǔ)義空間中的位置(由分布來(lái)表示)也會(huì)變化。而關(guān)鍵詞作為句子中最重要的信息,對(duì)應(yīng)于語(yǔ)義分布上的一個(gè)點(diǎn),它很大程度上也決定了句子分布的位置。同時(shí),在某些情況下,現(xiàn)有的對(duì)比學(xué)習(xí)目標(biāo)對(duì)模型來(lái)說(shuō)顯得過(guò)于容易,導(dǎo)致模型無(wú)法真正學(xué)習(xí)到區(qū)分正負(fù)例之間的關(guān)鍵信息。
基于此,來(lái)自螞蟻集團(tuán)、北大等機(jī)構(gòu)的研究者提出了一種多粒度對(duì)比生成方法,設(shè)計(jì)了層次化對(duì)比結(jié)構(gòu),在不同層級(jí)上進(jìn)行信息增強(qiáng),在句子粒度上增強(qiáng)學(xué)習(xí)整體的語(yǔ)義,在詞粒度上增強(qiáng)局部重要信息。研究論文已被 ACL 2022 接收。

論文地址:https://aclanthology.org/2022.acl-long.304.pdf
方法
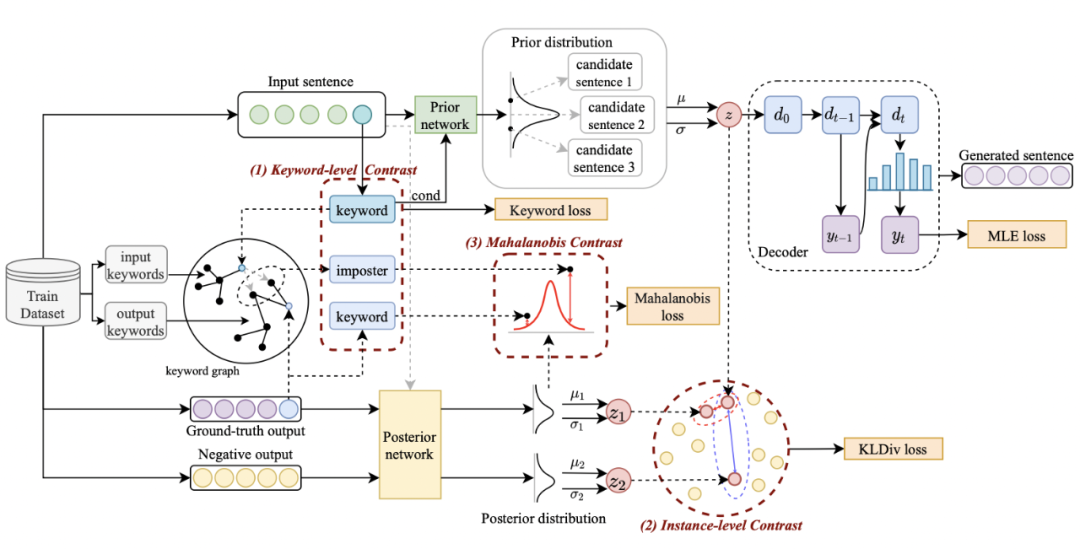
我們的方法基于經(jīng)典的 CVAE 文本生成框架 [3][4],每個(gè)句子都可以映射成為向量空間中的一個(gè)分布,而句子中的關(guān)鍵詞則可以看成是這個(gè)分布上采樣得到的一個(gè)點(diǎn)。我們一方面通過(guò)句子粒度的對(duì)比來(lái)增強(qiáng)隱空間向量分布的表達(dá),另一方面通過(guò)構(gòu)造的全局關(guān)鍵詞 graph 來(lái)增強(qiáng)關(guān)鍵詞點(diǎn)粒度的表達(dá),最后通過(guò)馬氏距離對(duì)關(guān)鍵詞的點(diǎn)和句子的分布構(gòu)造層次間的對(duì)比來(lái)增強(qiáng)兩個(gè)粒度的信息表達(dá)。最終的損失函數(shù)由三種不同的對(duì)比學(xué)習(xí) loss 相加而得到。
句子粒度對(duì)比學(xué)習(xí)
在 Instance-level,我們利用原始輸入 x、目標(biāo)輸出
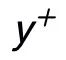
及對(duì)應(yīng)的輸出負(fù)樣本構(gòu)成了句子粒度的對(duì)比 pair
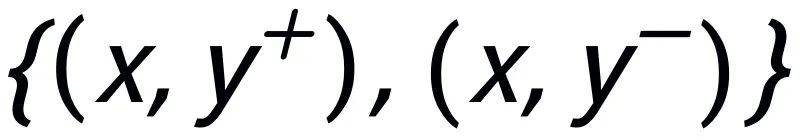
。我們利用一個(gè)先驗(yàn)網(wǎng)絡(luò)學(xué)習(xí)到先驗(yàn)分布
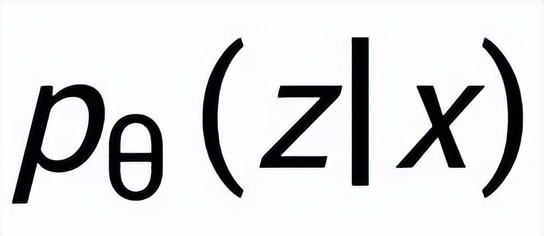
,記為
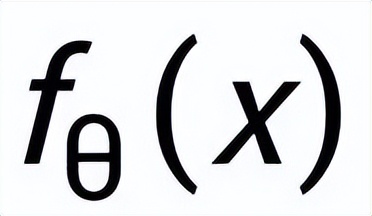
;通過(guò)一個(gè)后驗(yàn)網(wǎng)絡(luò)學(xué)習(xí)到近似的后驗(yàn)分布
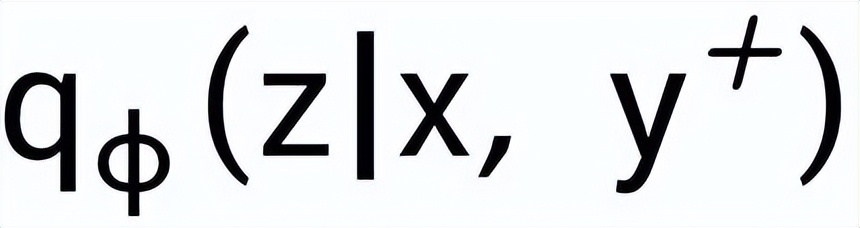
和
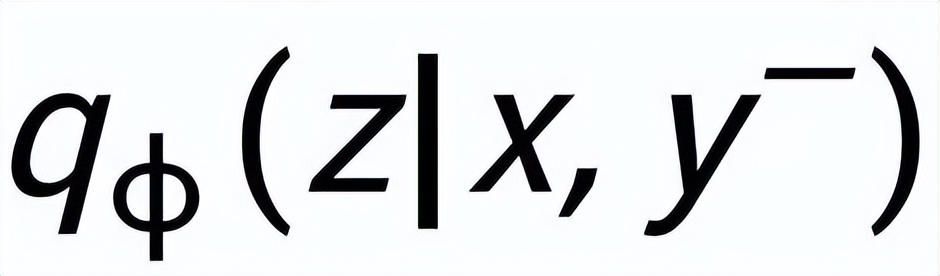
,分別記為
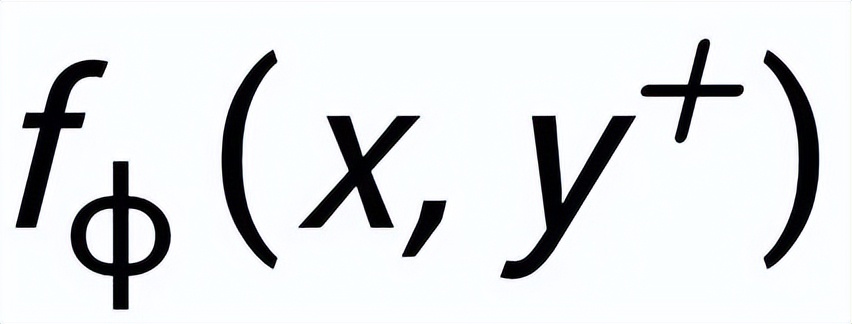
和
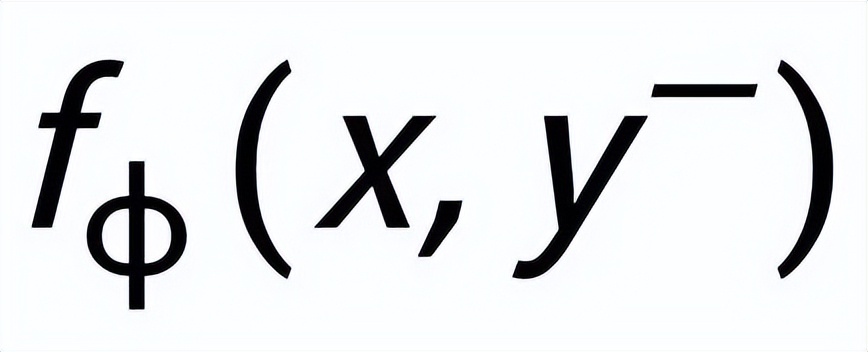
。句子粒度對(duì)比學(xué)習(xí)的目標(biāo)就是盡可能的縮小先驗(yàn)分布和正后驗(yàn)分布的距離,同時(shí)盡可能的推大先驗(yàn)分布和負(fù)后驗(yàn)分布的距離,相應(yīng)的損失函數(shù)如下:
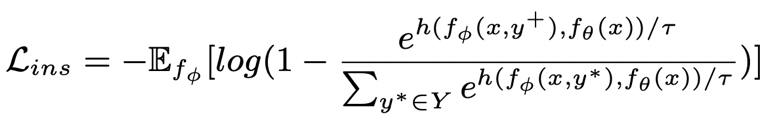
其中為正樣本或負(fù)樣本,為溫度系數(shù),用來(lái)表示距離度量,這里我們使用 KL 散度(Kullback–Leibler divergence )[5] 來(lái)度量?jī)蓚€(gè)分布直接的距離。
關(guān)鍵詞粒度對(duì)比學(xué)習(xí)
- 關(guān)鍵詞網(wǎng)絡(luò)
關(guān)鍵詞粒度的對(duì)比學(xué)習(xí)是用來(lái)讓模型更多的關(guān)注到句子中的關(guān)鍵信息,我們通過(guò)利用輸入輸出文本對(duì)應(yīng)的正負(fù)關(guān)系構(gòu)建一個(gè) keyword graph 來(lái)達(dá)到這個(gè)目標(biāo)。具體來(lái)說(shuō),根據(jù)一個(gè)給定的句對(duì)
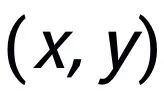
,我們可以分別從其中確定一個(gè)關(guān)鍵詞
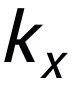
和
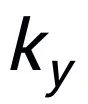
(關(guān)鍵詞抽取的方法我采用經(jīng)典的 TextRank 算法 [6]);對(duì)于一個(gè)句子
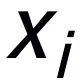
,可能存在與其關(guān)鍵詞
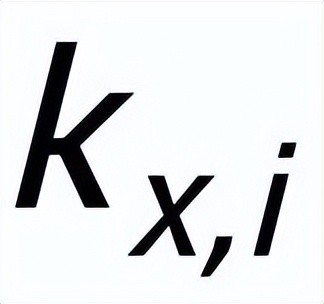
相同的其他句子,這些句子共同組成一個(gè)集合
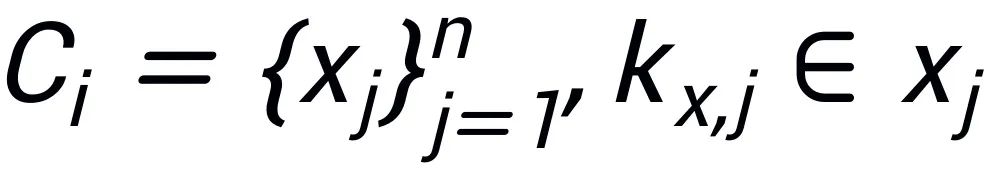
,這里面每一個(gè)句子

都有一對(duì)正負(fù)例輸出句子
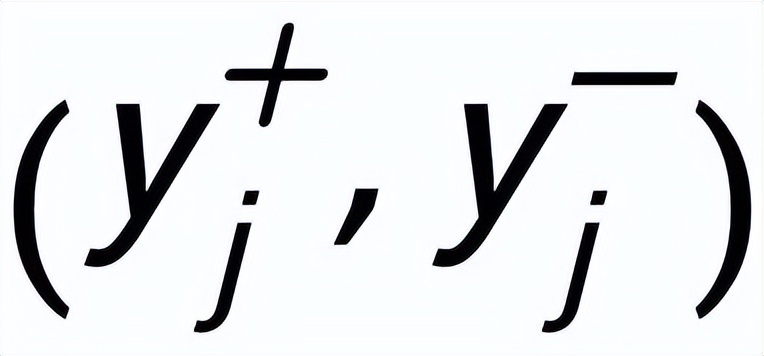
,他們分別又有一個(gè)正例關(guān)鍵詞

和負(fù)例關(guān)鍵詞

。這樣在整個(gè)集合中,對(duì)任何一個(gè)輸出的句子

,可以認(rèn)為它所對(duì)應(yīng)的關(guān)鍵詞
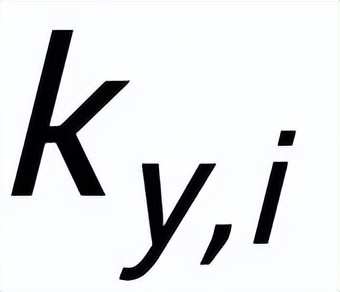
和每一個(gè)周圍的
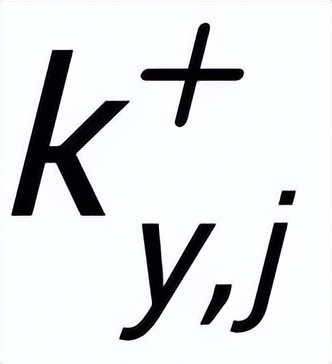
(通過(guò)句子之間的正負(fù)關(guān)系關(guān)聯(lián))之間都存在一條正邊

,和每一個(gè)周圍的

之間都存在一條負(fù)邊

。基于這些關(guān)鍵詞節(jié)點(diǎn)和他們直接的邊,我們就可以構(gòu)建一個(gè) keyword graph

我們使用 BERT embedding[7] 來(lái)作為每個(gè)節(jié)點(diǎn)
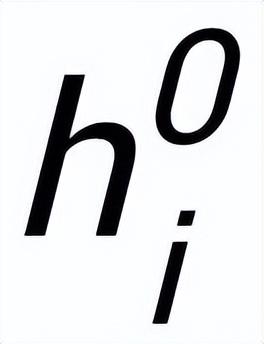
的初始化,并使用一個(gè) MLP 層來(lái)學(xué)習(xí)每條邊的表示
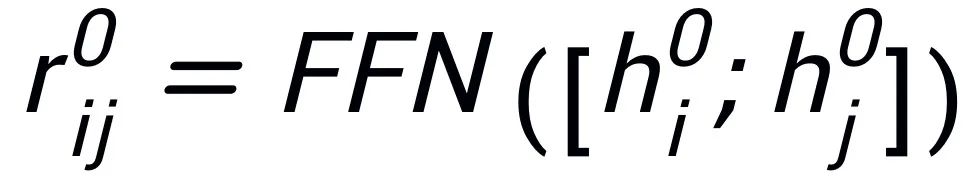
。我們通過(guò)一個(gè) graph attention (GAT) 層和 MLP 層來(lái)迭代式地更新關(guān)鍵詞網(wǎng)絡(luò)中的節(jié)點(diǎn)和邊,每個(gè)迭代中我們先通過(guò)如下的方式更新邊的表示:
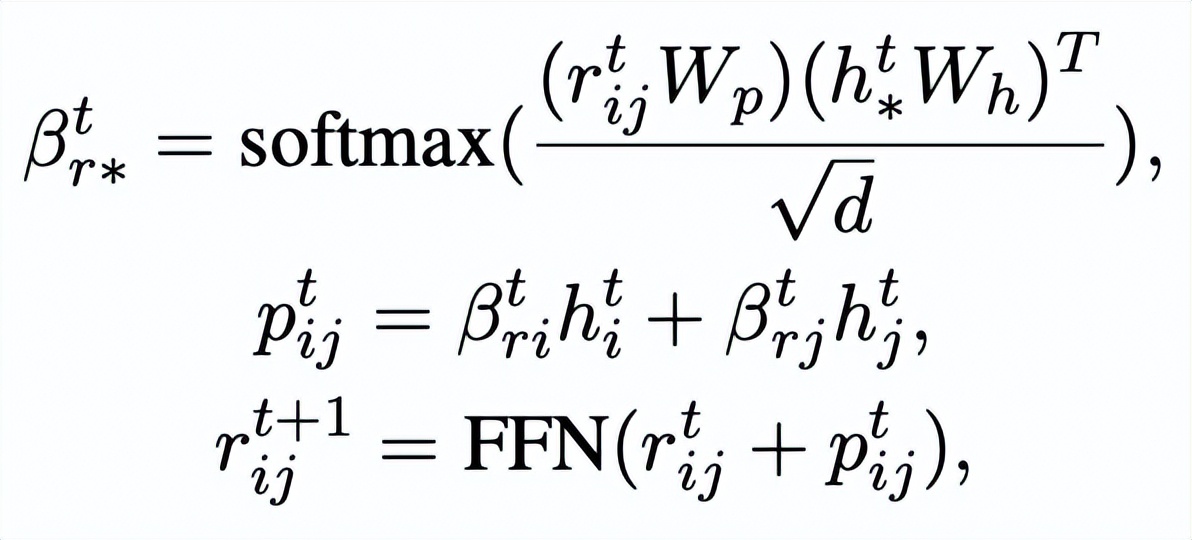
這里
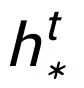
可以是
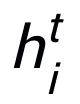
或者
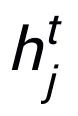
。
然后根據(jù)更新后的邊
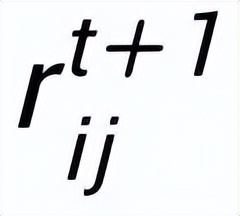
,我們通過(guò)一個(gè) graph attention 層來(lái)更新每個(gè)節(jié)點(diǎn)的表示:
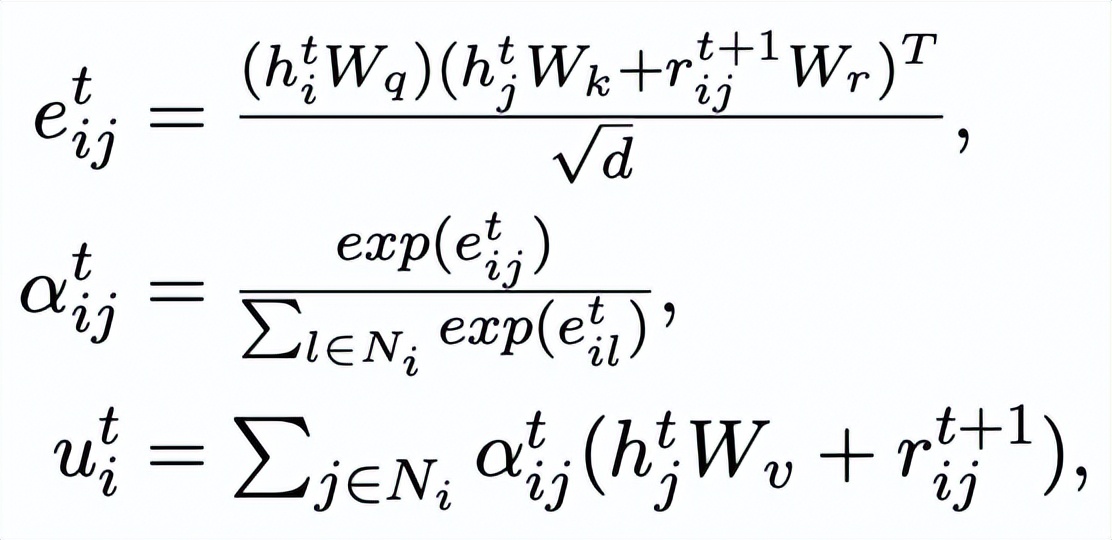
這里
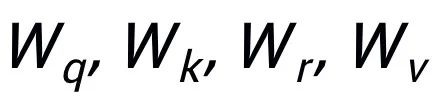
都是可學(xué)習(xí)的參數(shù),
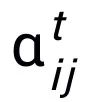
為注意力權(quán)重。為了防止梯度消失的問(wèn)題,我們?cè)?/span>
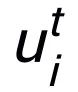
上加上了殘差連接,得到該迭代中節(jié)點(diǎn)的表示
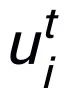
。我們使用最后一個(gè)迭代的節(jié)點(diǎn)表示作為關(guān)鍵詞的表示,記為 u。
- 關(guān)鍵詞對(duì)比
關(guān)鍵詞粒度的對(duì)比來(lái)自于輸入句子的關(guān)鍵詞

和一個(gè)偽裝(impostor)節(jié)點(diǎn)
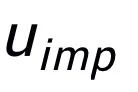
。我們將輸入句子的輸出正樣本中提取的關(guān)鍵詞記為
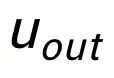
,它在上述關(guān)鍵詞網(wǎng)絡(luò)中的負(fù)鄰居節(jié)點(diǎn)記為
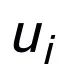
,則
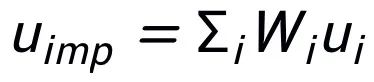
,關(guān)鍵詞粒度的對(duì)比學(xué)習(xí) loss 計(jì)算如下:
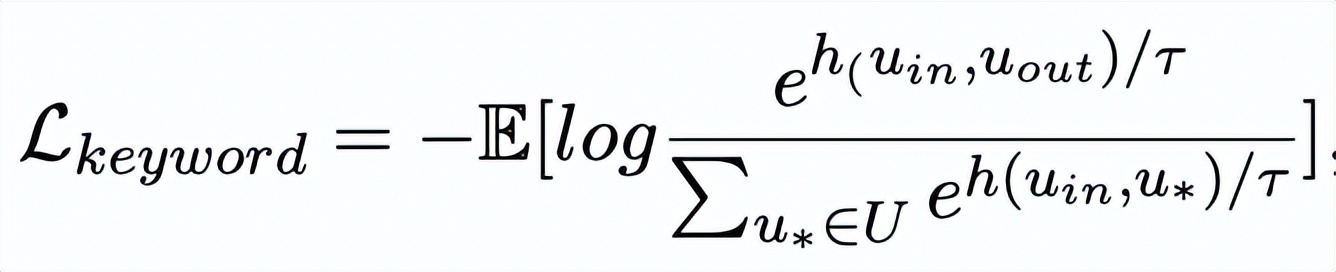
這里
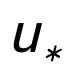
用來(lái)指代
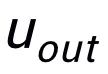
或者
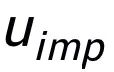
,h(·) 用來(lái)表示距離度量,在關(guān)鍵詞粒度的對(duì)比學(xué)習(xí)中我們選用了余弦相似度來(lái)計(jì)算兩個(gè)點(diǎn)之間的距離。
- 跨粒度對(duì)比學(xué)習(xí)
可以注意到上述句子粒度和關(guān)鍵詞粒度的對(duì)比學(xué)習(xí)分別是在分布和點(diǎn)上實(shí)現(xiàn),這樣兩個(gè)粒度的獨(dú)立對(duì)比可能由于差異較小導(dǎo)致增強(qiáng)效果減弱。對(duì)此,我們基于點(diǎn)和分布之間的馬氏距離(Mahalanobis distance)[8] 構(gòu)建不同粒度之間對(duì)比關(guān)聯(lián),使得目標(biāo)輸出關(guān)鍵詞到句子分布的距離盡可能小于 imposter 到該分布的距離,從而彌補(bǔ)各粒度獨(dú)立對(duì)比可能帶來(lái)的對(duì)比消失的缺陷。具體來(lái)說(shuō),跨粒度的馬氏距離對(duì)比學(xué)習(xí)希望盡可能縮小句子的后驗(yàn)語(yǔ)義分布
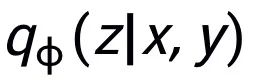
和
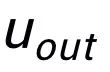
之間的距離,同時(shí)盡可能拉大其與
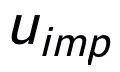
之間的距離,損失函數(shù)如下:
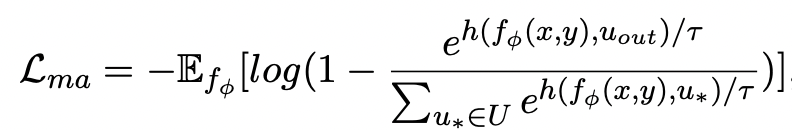
這里
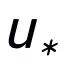
同樣用來(lái)指代
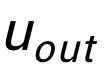
或者
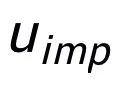
,而 h(·) 為馬氏距離。
實(shí)驗(yàn) & 分析
實(shí)驗(yàn)結(jié)果
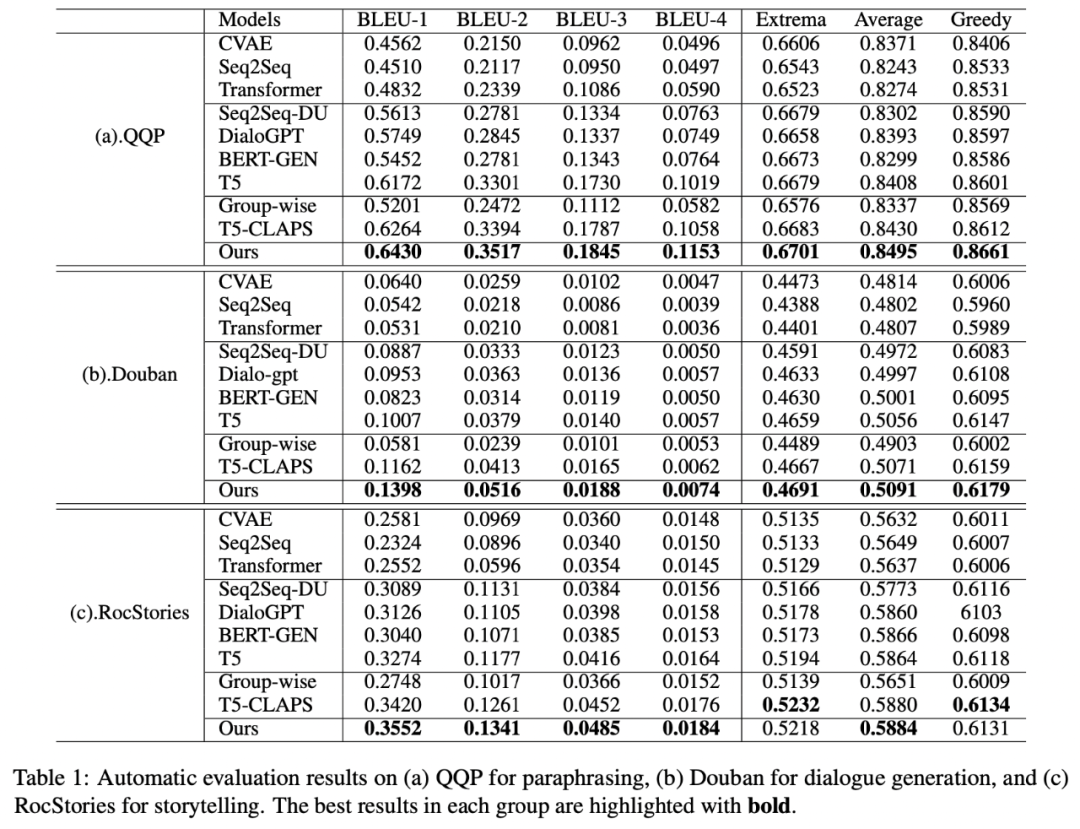
我們?cè)谌齻€(gè)公開(kāi)數(shù)據(jù)集 Douban(Dialogue)[9],QQP(Paraphrasing)[10][11] 和 RocStories(Storytelling)[12] 上進(jìn)行了實(shí)驗(yàn),均取得了 SOTA 的效果。我們對(duì)比的基線包括傳統(tǒng)的生成模型(e.g. CVAE[13],Seq2Seq[14],Transformer[15]),基于預(yù)訓(xùn)練模型的方法(e.g. Seq2Seq-DU[16],DialoGPT[17],BERT-GEN[7],T5[18])以及基于對(duì)比學(xué)習(xí)的方法(e.g. Group-wise[9],T5-CLAPS[19])。我們通過(guò)計(jì)算 BLEU score[20] 和句對(duì)之間的 BOW embedding 距離(extrema/average/greedy)[21] 來(lái)作為自動(dòng)化評(píng)價(jià)指標(biāo),結(jié)果如下圖所示:
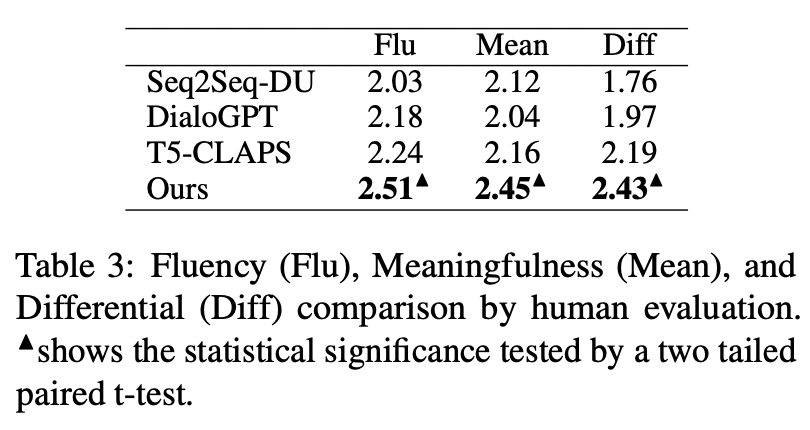
我們?cè)?QQP 數(shù)據(jù)集上還采用了人工評(píng)估的方式,3 個(gè)標(biāo)注人員分別對(duì) T5-CLAPS,DialoGPT,Seq2Seq-DU 以及我們的模型產(chǎn)生的結(jié)果進(jìn)行了標(biāo)注,結(jié)果如下圖所示:
消融分析
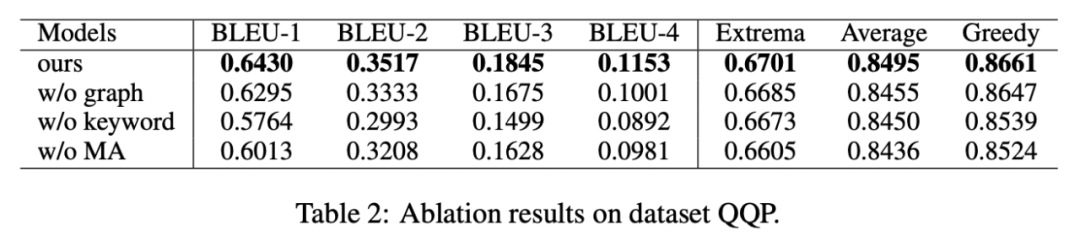
我們對(duì)是否采用關(guān)鍵詞、是否采用關(guān)鍵詞網(wǎng)絡(luò)以及是否采用馬氏距離對(duì)比分布進(jìn)行了消融分析實(shí)驗(yàn),結(jié)果顯示這三種設(shè)計(jì)對(duì)最后的結(jié)果確實(shí)起到了重要的作用,實(shí)驗(yàn)結(jié)果如下圖所示。
可視化分析
為了研究不同層級(jí)對(duì)比學(xué)習(xí)的作用,我們對(duì)隨機(jī)采樣的 case 進(jìn)行了可視化,通過(guò) t-sne[22] 進(jìn)行降維處理后得到下圖。圖中可以看出,輸入句子的表示與抽取的關(guān)鍵詞表示接近,這說(shuō)明關(guān)鍵詞作為句子中最重要的信息,通常會(huì)決定語(yǔ)義分布的位置。并且,在對(duì)比學(xué)習(xí)中我們可以看到經(jīng)過(guò)訓(xùn)練,輸入句子的分布與正樣本更接近,與負(fù)樣本遠(yuǎn)離,這說(shuō)明對(duì)比學(xué)習(xí)可以起到幫助修正語(yǔ)義分布的作用。
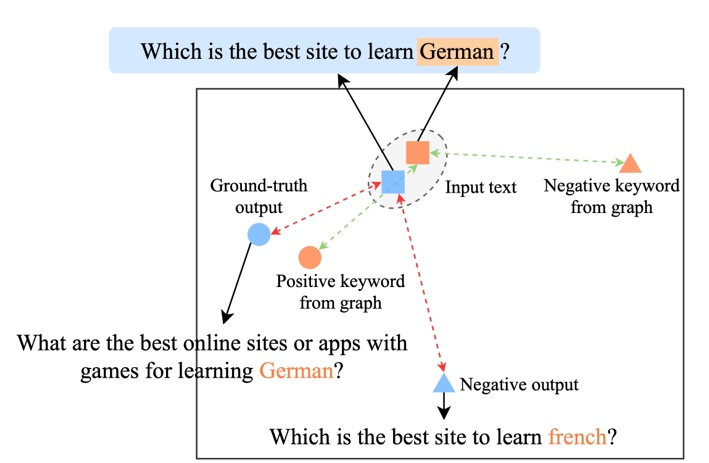
關(guān)鍵詞重要性分析
最后,我們探索采樣不同關(guān)鍵詞的影響。如下表所示,對(duì)于一個(gè)輸入問(wèn)題,我們通過(guò) TextRank 抽取和隨機(jī)選擇的方法分別提供關(guān)鍵詞作為控制語(yǔ)義分布的條件,并檢查生成文本的質(zhì)量。關(guān)鍵詞作為句子中最重要的信息單元,不同的關(guān)鍵詞會(huì)導(dǎo)致不同的語(yǔ)義分布,產(chǎn)生不同的測(cè)試,選擇的關(guān)鍵詞越多,生成的句子越準(zhǔn)確。同時(shí),其他模型生成的結(jié)果也展示在下表中。

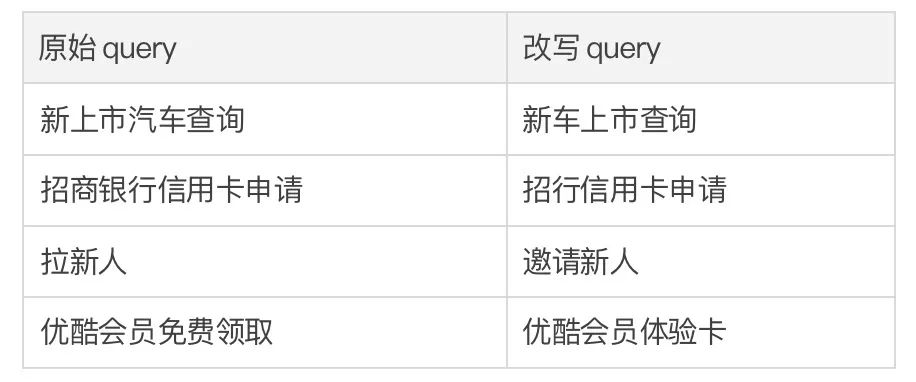
業(yè)務(wù)應(yīng)用
這篇文章中我們提出了一種跨粒度的層次化對(duì)比學(xué)習(xí)機(jī)制,在多個(gè)文本生成的數(shù)據(jù)集上均超過(guò)了具有競(jìng)爭(zhēng)力的基線工作。基于該工作的 query 改寫模型在也在支付寶搜索的實(shí)際業(yè)務(wù)場(chǎng)景成功落地,取得了顯著的效果。支付寶搜索中的服務(wù)覆蓋領(lǐng)域?qū)拸V并且領(lǐng)域特色顯著,用戶的搜索 query 表達(dá)與服務(wù)的表達(dá)存在巨大的字面差異,導(dǎo)致直接基于關(guān)鍵詞的匹配難以取得理想的效果(例如用戶輸入 query“新上市汽車查詢”,無(wú)法召回服務(wù) “新車上市查詢”),query 改寫的目標(biāo)是在保持 query 意圖不變的情況下,將用戶輸入的 query 改寫為更貼近服務(wù)表達(dá)的方式,從而更好的匹配到目標(biāo)服務(wù)。如下是一些改寫示例: