譯者 | 張怡
審校 | 梁策 孫淑娟
1.如何成為一個(gè)IDO?
IDO(insight-driven organization)指洞察力驅(qū)動(dòng)(以信息為導(dǎo)向)的組織。要成為一個(gè)IDO,首先需要數(shù)據(jù)以及操作和分析數(shù)據(jù)的工具;其次是具有適當(dāng)經(jīng)驗(yàn)的數(shù)據(jù)分析師或數(shù)據(jù)科學(xué)家;最后還需要找到一種技術(shù)或者方法,從而在整個(gè)公司實(shí)施洞察力驅(qū)動(dòng)的決策過程。
機(jī)器學(xué)習(xí)是能最大限度發(fā)揮數(shù)據(jù)優(yōu)勢(shì)的技術(shù)。ML流程首先使用數(shù)據(jù)訓(xùn)練預(yù)測(cè)模型,訓(xùn)練成功之后來解決與數(shù)據(jù)相關(guān)的問題。其中,人工神經(jīng)網(wǎng)絡(luò)是最有效的技術(shù),它的設(shè)計(jì)源自我們目前對(duì)人類大腦工作方式的理解。考慮到人們目前擁有的巨大計(jì)算資源,它通過大量數(shù)據(jù)訓(xùn)練可以產(chǎn)生令人難以置信的模型。
企業(yè)可以使用各種自助化軟件和腳本完成不同的任務(wù),從而避免人為錯(cuò)誤的情況。同樣,你也完全可以基于數(shù)據(jù)進(jìn)行決策來避免當(dāng)中的人為錯(cuò)誤。
2.為什么企業(yè)在采用人工智能方面進(jìn)展緩慢?
使用人工智能或機(jī)器學(xué)習(xí)來處理數(shù)據(jù)的企業(yè)僅是少數(shù)。美國人口普查局(US Census Bureau)表示,截至2020年,只有不到10%的美國企業(yè)采用了機(jī)器學(xué)習(xí)(主要是大公司)。
采用ML的障礙包括:
- 人工智能在取代人類之前還有大量工作尚未完成。首先是許多企業(yè)缺乏且請(qǐng)不起專業(yè)人員。數(shù)據(jù)科學(xué)家在這一領(lǐng)域備受推崇,但他們的雇傭成本也是最高的。
- 缺乏可用數(shù)據(jù)、數(shù)據(jù)安全性以及耗時(shí)的ML算法實(shí)現(xiàn)。
- 企業(yè)很難創(chuàng)造一個(gè)環(huán)境,從而讓數(shù)據(jù)及其優(yōu)勢(shì)得到發(fā)揮。這種環(huán)境需要相關(guān)的工具、過程和策略。
3.機(jī)器學(xué)習(xí)的推廣只有自動(dòng)ML(AutoML)工具是不夠的
自動(dòng)ML平臺(tái)雖然有著很光明的未來,但其覆蓋面目前還相當(dāng)有限,同時(shí)關(guān)于自動(dòng)ML能否很快取代數(shù)據(jù)科學(xué)家的說法也有爭(zhēng)論。
如果想要在公司成功部署自助化機(jī)器學(xué)習(xí),AutoML工具確實(shí)是至關(guān)重要的,但過程、方法和策略也必須重視。AutoML平臺(tái)只是工具,大多數(shù)ML專家認(rèn)為這是不夠的。
4.分解機(jī)器學(xué)習(xí)過程
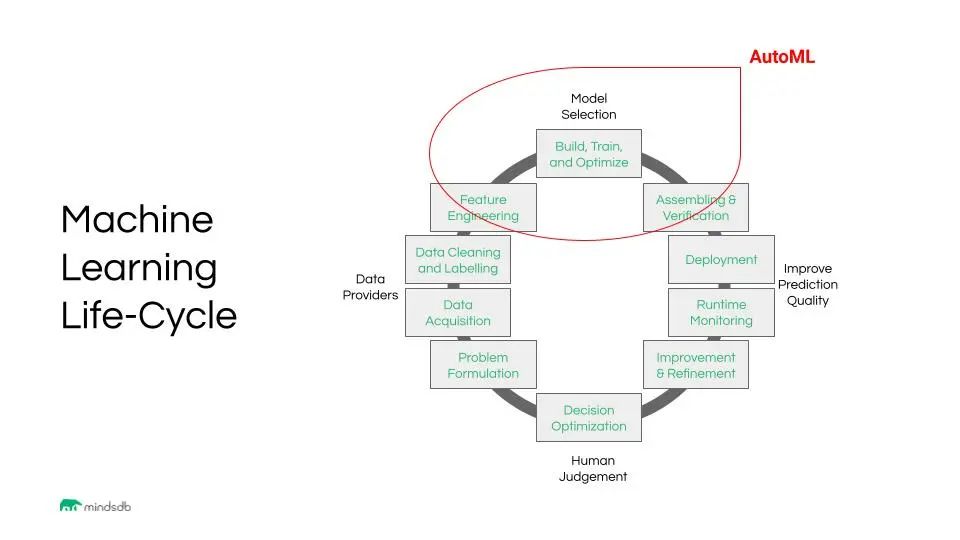
任何ML進(jìn)程都從數(shù)據(jù)開始。人們普遍認(rèn)為,數(shù)據(jù)準(zhǔn)備是ML過程中最重要的環(huán)節(jié),建模部分只是整個(gè)數(shù)據(jù)管道的一部分,同時(shí)通過AutoML工具得到簡(jiǎn)化。完整的工作流仍需要大量的工作來轉(zhuǎn)換數(shù)據(jù)并將其提供給模型。數(shù)據(jù)準(zhǔn)備和數(shù)據(jù)轉(zhuǎn)換可謂工作中最耗時(shí)、最令人不愉快的部分。
此外,用于訓(xùn)練ML模型的業(yè)務(wù)數(shù)據(jù)也會(huì)定期更新。因此,它要求企業(yè)構(gòu)建能夠掌握復(fù)雜的工具和流程的復(fù)雜ETL管道,因此確保ML流程的連續(xù)和實(shí)時(shí)性也是一項(xiàng)具有挑戰(zhàn)性的任務(wù)。
5.將ML與應(yīng)用程序集成
假設(shè)現(xiàn)在我們已經(jīng)構(gòu)建了ML模型,然后需要將其部署。經(jīng)典的部署方法將其視為應(yīng)用層組件,如下圖所示:
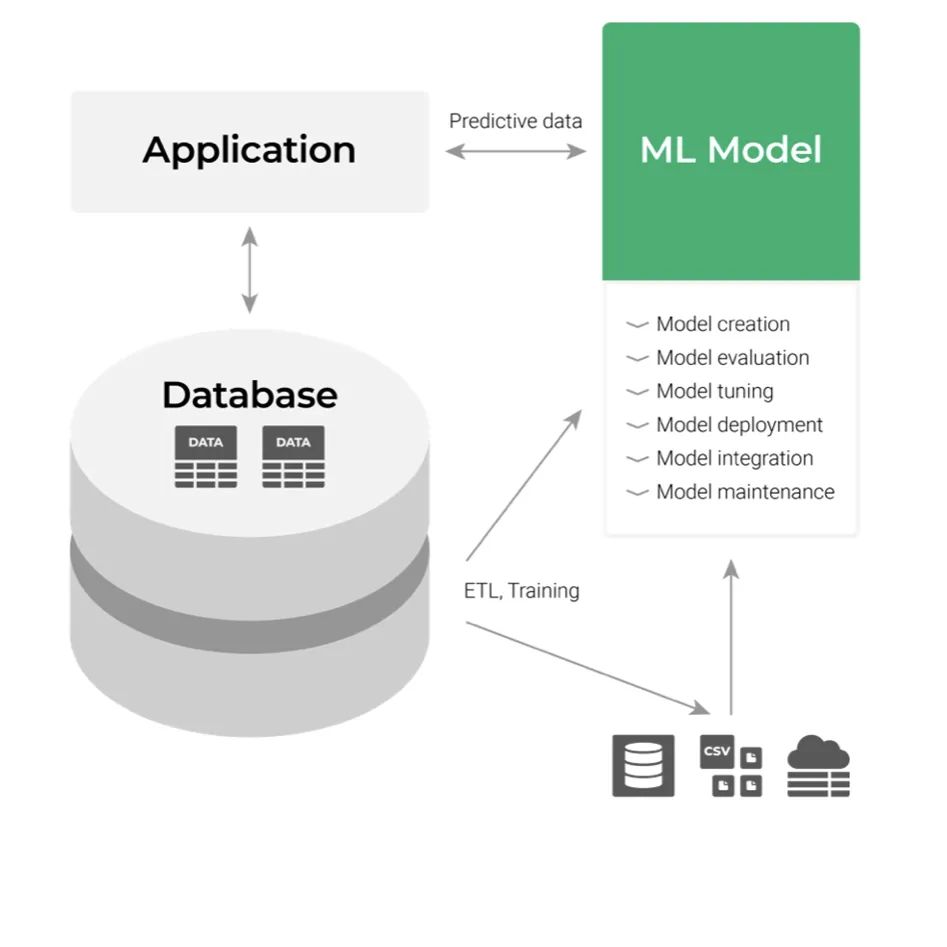
它的輸入是數(shù)據(jù),輸出是我們得到的預(yù)測(cè)。通過集成這些應(yīng)用程序的API來使用ML模型的輸出。僅從開發(fā)者的角度來看,這一切似乎很容易,但在考慮流程時(shí)就不是那么回事了。在一個(gè)龐大的組織中,與業(yè)務(wù)應(yīng)用程序的任何集成和維護(hù)都相當(dāng)麻煩。即使公司精通技術(shù),任何代碼更改請(qǐng)求都必須通過多級(jí)部門的特定審查和測(cè)試流程。這會(huì)對(duì)靈活性產(chǎn)生負(fù)面影響,并增加整個(gè)工作流的復(fù)雜性。
如果在測(cè)試各種概念和想法方面有足夠的靈活性,那么基于ML的決策就會(huì)容易得多,因此人們會(huì)更喜歡具有自助服務(wù)功能的產(chǎn)品。
6.自助機(jī)器學(xué)習(xí)/智能數(shù)據(jù)庫?
正如我們上面看到的,數(shù)據(jù)是ML進(jìn)程的核心,現(xiàn)有的ML工具獲取數(shù)據(jù)并返回預(yù)測(cè)結(jié)果,而這些預(yù)測(cè)也是數(shù)據(jù)的形式。
現(xiàn)在問題來了:
- 為什么我們要把ML作為一個(gè)獨(dú)立的應(yīng)用程序,并在ML模型、應(yīng)用程序和數(shù)據(jù)庫之間實(shí)現(xiàn)復(fù)雜的集成呢?
- 為什么不讓ML成為數(shù)據(jù)庫的核心功能呢?
- 為什么不讓ML模型通過標(biāo)準(zhǔn)的數(shù)據(jù)庫語法(如SQL)可用呢?
讓我們分析上述問題及其面臨的挑戰(zhàn),從而找到ML解決方案。
挑戰(zhàn)#1:復(fù)雜的數(shù)據(jù)集成和ETL管道
維護(hù)ML模型和數(shù)據(jù)庫之間的復(fù)雜數(shù)據(jù)集成和ETL管道,是ML流程面臨的最大挑戰(zhàn)之一。
SQL是極佳的數(shù)據(jù)操作工具,所以我們可以通過將ML模型引入數(shù)據(jù)層來解決這個(gè)問題。換句話說,ML模型將在數(shù)據(jù)庫中學(xué)習(xí)并返回預(yù)測(cè)。
挑戰(zhàn)#2:ML模型與應(yīng)用程序的集成
通過API將ML模型與業(yè)務(wù)應(yīng)用程序集成是面臨的另一個(gè)挑戰(zhàn)。
業(yè)務(wù)應(yīng)用程序和BI工具與數(shù)據(jù)庫緊密耦合。因此,如果AutoML工具成為數(shù)據(jù)庫的一部分,我們就可以使用標(biāo)準(zhǔn)SQL語法進(jìn)行預(yù)測(cè)。接下來,ML模型和業(yè)務(wù)應(yīng)用程序之間不再需要API集成,因?yàn)槟P婉v留在數(shù)據(jù)庫中。
解決方案:在數(shù)據(jù)庫中嵌入AutoML
在數(shù)據(jù)庫中嵌入AutoML工具會(huì)帶來很多好處,比如:
- 任何使用數(shù)據(jù)并了解SQL的人(數(shù)據(jù)分析師或數(shù)據(jù)科學(xué)家)都可以利用機(jī)器學(xué)習(xí)的力量。
- 軟件開發(fā)人員可以更有效地將ML嵌入到業(yè)務(wù)工具和應(yīng)用程序中。
- 數(shù)據(jù)和模型之間以及模型和業(yè)務(wù)應(yīng)用程序之間不需要復(fù)雜的集成。
這樣一來,上述相對(duì)復(fù)雜的集成圖表變更如下:
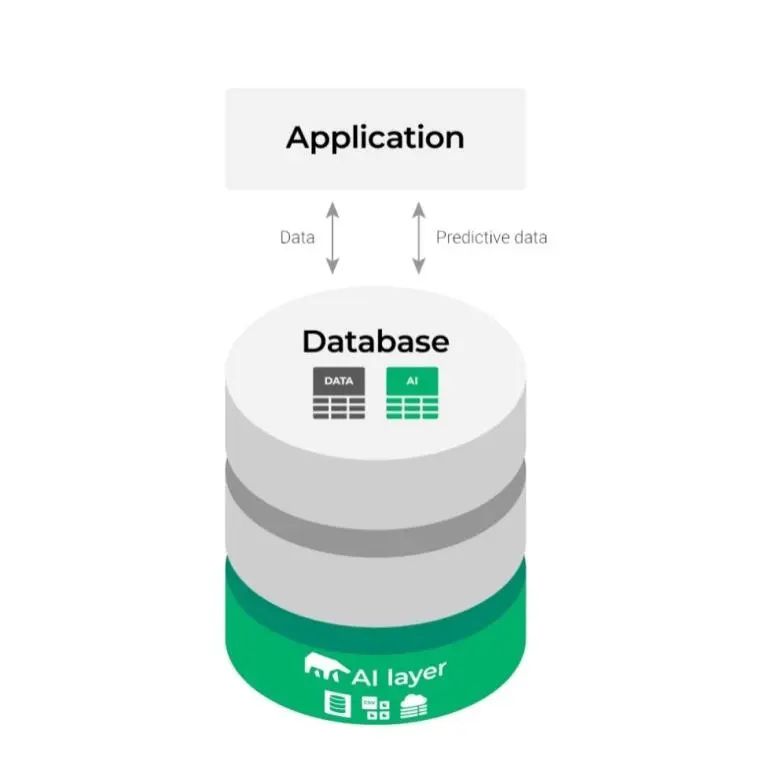
它看起來更簡(jiǎn)單,也使ML過程更流暢高效。
7.如何實(shí)現(xiàn)自助式ML將模型作為虛擬數(shù)據(jù)庫表
找到解決方案的下一步是來實(shí)施它。
為此,我們使用了一個(gè)叫做AI Tables的結(jié)構(gòu)。它以虛擬表的形式將機(jī)器學(xué)習(xí)引入數(shù)據(jù)平臺(tái)。它可以像其他數(shù)據(jù)庫表一樣創(chuàng)建,然后向應(yīng)用程序、BI工具和DB客戶端開放。我們通過簡(jiǎn)單地查詢數(shù)據(jù)來進(jìn)行預(yù)測(cè)。
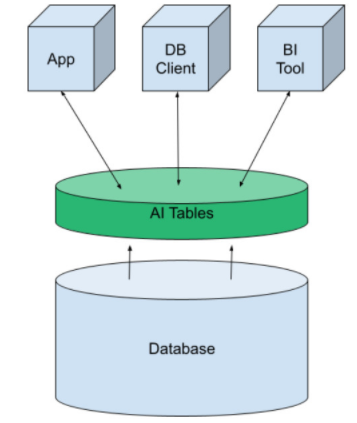
AI Tables最初由MindsDB開發(fā),可以作為開源或托管云服務(wù)使用。他們集成了傳統(tǒng)的SQL和NoSQL數(shù)據(jù)庫,如Kafka和Redis。
8.使用AI Tables
AI Tables的概念使我們能夠在數(shù)據(jù)庫中執(zhí)行ML過程,這樣ML過程的所有步驟(即數(shù)據(jù)準(zhǔn)備、模型訓(xùn)練和預(yù)測(cè))都可以通過數(shù)據(jù)庫進(jìn)行。
- 訓(xùn)練AI Tables
首先,用戶要根據(jù)自己的需求創(chuàng)建一個(gè)AI Table,它類似于一個(gè)機(jī)器學(xué)習(xí)模型,包含了與源表的列等價(jià)的特征;然后通過AutoML引擎自助完成剩余的建模任務(wù)。后文還將舉例說明。
- 做預(yù)測(cè)
一旦創(chuàng)建了AI Table,它不需要任何進(jìn)一步的部署就可以使用了。要進(jìn)行預(yù)測(cè),只需要在AI Table上運(yùn)行一個(gè)標(biāo)準(zhǔn)SQL查詢。
你可以逐個(gè)或分批地進(jìn)行預(yù)測(cè)。AI Tables可以處理許多復(fù)雜的機(jī)器學(xué)習(xí)任務(wù),如多元時(shí)間序列、檢測(cè)異常等。
9.AI Tables工作示例
對(duì)于零售商來說,在適當(dāng)?shù)臅r(shí)間保證產(chǎn)品都有適當(dāng)?shù)膸齑媸且豁?xiàng)復(fù)雜的任務(wù)。當(dāng)需求增長(zhǎng)時(shí),供給隨之增加。基于這些數(shù)據(jù)和機(jī)器學(xué)習(xí),我們可以預(yù)測(cè)給定的產(chǎn)品在給定的日期應(yīng)該有多少庫存,從而為零售商帶來更多收益。
首先你需要跟蹤以下信息,建立一張AI Table:
- 產(chǎn)品售出日期(date_of_sale)
- 產(chǎn)品售出店鋪(shop)
- 具體售出產(chǎn)品(product_code)
- 產(chǎn)品售出數(shù)量(amount)
如下圖所示:
(1)訓(xùn)練AI Tables
要?jiǎng)?chuàng)建和訓(xùn)練AI Tables,你首先要允許MindsDB訪問數(shù)據(jù)。詳細(xì)說明可參考MindsDB文檔( MindsDB documentation)。
AI Tables就像ML模型,需要使用歷史數(shù)據(jù)來訓(xùn)練它們。
下面使用一個(gè)簡(jiǎn)單的SQL命令,訓(xùn)練一個(gè)AITable:

讓我們分析這個(gè)查詢:
- 使用MindsDB中的CREATE PREDICTOR語句。
- 根據(jù)歷史數(shù)據(jù)定義源數(shù)據(jù)庫。
- 根據(jù)歷史數(shù)據(jù)表(historical_table)訓(xùn)練AI Table,所選列(column_1和column_2)是用來進(jìn)行預(yù)測(cè)的特征。
- AutoML自動(dòng)完成剩下的建模任務(wù)。
- MindsDB會(huì)識(shí)別每一列的數(shù)據(jù)類型,對(duì)其進(jìn)行歸一化和編碼,并構(gòu)建和訓(xùn)練ML模型。
同時(shí),你可以看到每個(gè)預(yù)測(cè)的總體準(zhǔn)確率和置信度,并估計(jì)哪些列(特征)對(duì)結(jié)果更重要。
在數(shù)據(jù)庫中,我們經(jīng)常需要處理涉及高基數(shù)的多元時(shí)間序列數(shù)據(jù)的任務(wù)。如果使用傳統(tǒng)的方法,需要相當(dāng)大的力氣來創(chuàng)建這樣的ML模型。我們需要對(duì)數(shù)據(jù)進(jìn)行分組,并根據(jù)給定的時(shí)間、日期或時(shí)間戳數(shù)據(jù)字段對(duì)其進(jìn)行排序。
例如,我們預(yù)測(cè)五金店賣出的錘子數(shù)量。那么,數(shù)據(jù)按商店和產(chǎn)品分組,并對(duì)每個(gè)不同的商店和產(chǎn)品組合作出預(yù)測(cè)。這就給我們帶來了為每個(gè)組創(chuàng)建時(shí)間序列模型的問題。
這聽起來工程浩大,但MindsDB提供了使用GROUP BY語句創(chuàng)建單個(gè)ML模型,從而一次性訓(xùn)練多元時(shí)間序列數(shù)據(jù)的方法。讓我們看看僅使用一個(gè)SQL命令是如何完成的:

創(chuàng)建的stock_forecaster預(yù)測(cè)器可以預(yù)測(cè)某個(gè)特定商店未來將銷售多少商品。數(shù)據(jù)按銷售日期排序,并按商店分組。所以我們可以為每個(gè)商店預(yù)測(cè)銷售金額。
(2)批量預(yù)測(cè)
通過使用下面的查詢將銷售數(shù)據(jù)表與預(yù)測(cè)器連接起來,JOIN操作將預(yù)測(cè)的數(shù)量添加到記錄中,因此我們可以一次性獲得許多記錄的批量預(yù)測(cè)。

如想了解更多關(guān)于在BI工具中分析和可視化預(yù)測(cè)的知識(shí),請(qǐng)查看這篇文章。
(3)實(shí)際運(yùn)用
傳統(tǒng)方法將ML模型視為獨(dú)立的應(yīng)用程序,需要維護(hù)到數(shù)據(jù)庫的ETL管道和到業(yè)務(wù)應(yīng)用程序的API集成。AutoML工具盡管使建模部分變得輕松而直接,但完整的ML工作流也仍然需要經(jīng)驗(yàn)豐富的專家管理。其實(shí)數(shù)據(jù)庫已經(jīng)是數(shù)據(jù)準(zhǔn)備的優(yōu)選工具,因此將ML引入到數(shù)據(jù)庫而非將數(shù)據(jù)引入ML中是更有意義的。由于AutoML工具駐留在數(shù)據(jù)庫中,來自MindsDB的AI Tables構(gòu)造能夠?yàn)閿?shù)據(jù)從業(yè)者提供自助AutoML并讓機(jī)器學(xué)習(xí)工作流得以簡(jiǎn)化。
原文鏈接:https://dzone.com/articles/self-service-machine-learning-with-intelligent-dat
譯者介紹
張怡,51CTO社區(qū)編輯,中級(jí)工程師。主要研究人工智能算法實(shí)現(xiàn)以及場(chǎng)景應(yīng)用,對(duì)機(jī)器學(xué)習(xí)算法和自動(dòng)控制算法有所了解和掌握,并將持續(xù)關(guān)注國內(nèi)外人工智能技術(shù)的發(fā)展動(dòng)態(tài),特別是人工智能技術(shù)在智能網(wǎng)聯(lián)汽車、智能家居等領(lǐng)域的具體實(shí)現(xiàn)及其應(yīng)用。