













關于業務存儲結構擴容的方案設計和思考
今天和研發團隊溝通一個數據存儲方案的設計和改造,大體的背景是在數據庫中有些id類數據,如果數據類型是int,則存在一定的溢出風險,在程序層面需要提前考慮修改為int64,在MySQL中可以簡單理解為bigint.
我們假設這個id字段為uid,如果是用戶業務,則很多業務邏輯都是和這個uid強相關的,那么就會存在大量的業務梳理和研發代碼的接入,如果底層數據存儲的壓力和風險過大,則這個事情的改進周期和影響范圍就會更難以評估和控制。
所以這個問題從長期來看是未雨綢繆,對已有的數據存儲是完全兼容的。但是從短期來看,這個調整會對已有的線上服務帶來一些風險,如果涉及到約束的變更,則這個事情的復雜度會更高。為此我們經過溝通,想到了如下的幾類解決方案:
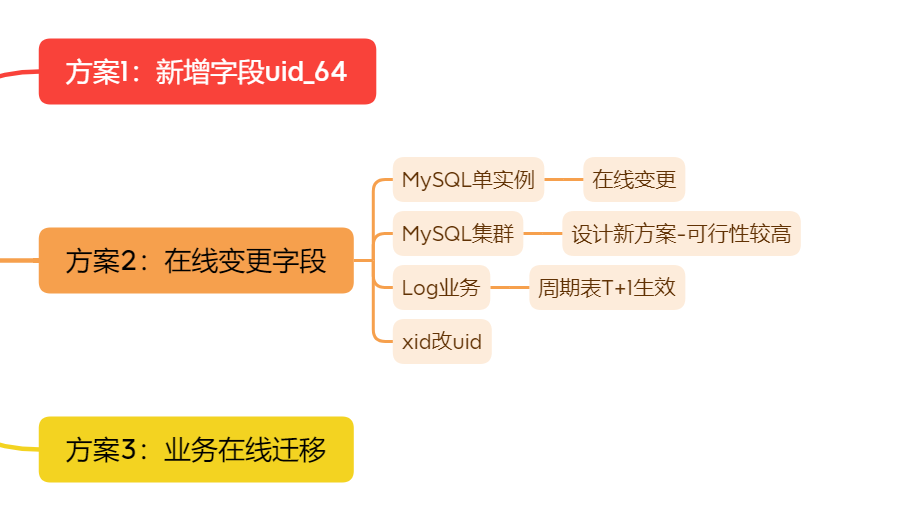
1)新增字段uid_64,這樣已有的業務邏輯可以正常運行,新的字段可以并行調整,當然從數據存儲來看,這個代價是比較高了,而且后續調整為uid_64之后很可能需要再統一為uid的模式,所以從研發還是數據存儲來說,改造幅度都比較大。
2)在線變更,這里我說的在線變更拆分為了4類場景。
場景1:
對于一些復雜度較為可控的業務,數據量也不夠大,采用在線變更的模式是比較合適的,這里我們可以使用online DDL,pt-osc或者gh-ost的方式來實現在線變更;
場景2:
對于一些較為復雜的業務,如MySQL集群,采用了分庫分表,數據量可能在億級別,這種變更的復雜度就比較大了,而且可以肯定的是在線變更對于復雜架構模式的風險大,而且不可控因素會更多,這里可以采用更好的應用架構設計,基于高可用靈活切換的方式,比如整個結構的變更都可以在從庫端進行統一調整,因為這種數據類型的擴容是具備兼容性的,所以原生的復制不會產生直接影響,而且即使執行時間長一些,對于線上業務來說是幾乎無感知的,等變更完成之后,就可以快速通過服務切換的方式將集群從原本的主庫切換到從庫,這個過程是需要主動觸發,如果是秒級的異常,會對研發來說是直接反饋,這種情況下反而是好事。這個過程涉及的細節較多,核心思想就是從庫,異步,高可用切換;
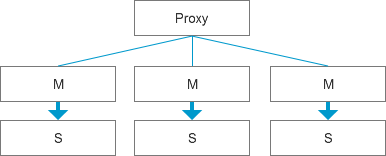
場景3:
對于流水日志的處理方式,采用T+1的模式對于研發側來說是幾乎不需要修改主干業務邏輯就可以適配的。
場景4:
這一類場景較為復雜,比如在業務中會有不規范的使用方式,對于不規范導致的列名不是uid的情況,比如從xid修改為uid,在數據庫和研發側的修改代價都是比較高的,這種情況下,我是不建議使用在線變更的模式
3)業務在線遷移
這一類場景對于后端數據存儲是相對簡單的,就是提供一個新的數據庫,讓業務來完成整體的遷移和切換,這種情況下,對于研發的能力要求較高,所有的關鍵操作都是通過研發在線遷移的方式來實現。
綜上的三種方案,我是建議根據場景來靈活適配,比如方案2和方案3來組合的形式。如果后端的數據存儲在梳理中修改范圍更加的龐大,則需要根據細化的業務場景來選擇當前更合適的方案。




















