













人臉識別技術發展及實用方案設計

人臉識別技術不但吸引了Google、Facebook、阿里、騰訊、百度等國內外互聯網巨頭的大量研發投入,也催生了Face++、商湯科技、Linkface、中科云從、依圖等一大波明星創業公司,在視頻監控、刑事偵破、互聯網金融身份核驗、自助通關系統等方向創造了諸多成功應用案例。本文試圖梳理人臉識別技術發展,并根據作者在相關領域的實踐給出一些實用方案設計,期待能對感興趣的讀者有所裨益。
概述
通俗地講,任何一個的機器學習問題都可以等價于一個尋找合適變換函數的問題。例如語音識別,就是在求取合適的變換函數,將輸入的一維時序語音信號變換到語義空間;而近來引發全民關注的圍棋人工智能AlphaGo則是將輸入的二維布局圖像變換到決策空間以決定下一步的最優走法;相應的,人臉識別也是在求取合適的變換函數,將輸入的二維人臉圖像變換到特征空間,從而唯一確定對應人的身份。
一直以來,人們都認為圍棋的難度要遠大于人臉識別,因此,當AlphaGo以絕對優勢輕易打敗世界冠軍李世乭九段和柯潔九段時,人們更驚嘆于人工智能的強大。實際上,這一結論只是人們的基于“常識”的誤解,因為從大多數人的切身體驗來講,即使經過嚴格訓練,打敗圍棋世界冠軍的幾率也是微乎其微;相反,絕大多數普通人,即便未經過嚴格訓練,也能輕松完成人臉識別的任務。然而,我們不妨仔細分析一下這兩者之間的難易程度:在計算機的“眼里”,圍棋的棋盤不過是個19x19的矩陣,矩陣的每一個元素可能的取值都來自于一個三元組{0,1,2},分別代表無子,白子及黑子,因此輸入向量可能的取值數為3361;而對于人臉識別來講,以一幅512x512的輸入圖像為例,它在計算機的“眼中”是一個512x512x3維的矩陣,矩陣的每一個元素可能的取值范圍為0~255,因此輸入向量可能的取值數為256786432。雖然,圍棋AI和人臉識別都是尋求合適的變換函數f,但后者輸入空間的復雜度顯然遠遠大于前者。
對于一個理想的變換函數f而言,為了達到最優的分類效果,在變換后的特征空間上,我們希望同類樣本的類內差盡可能小,同時不同類樣本的類間差盡可能大。但是,理想是豐滿的,現實卻是骨感的。由于光照、表情、遮擋、姿態等諸多因素(如圖1)的影響,往往導致不同人之間的差距比相同人之間差距更小,如圖2。人臉識別算法發展的歷史就是與這些識別影響因子斗爭的歷史。

圖1 人臉識別的影響因素
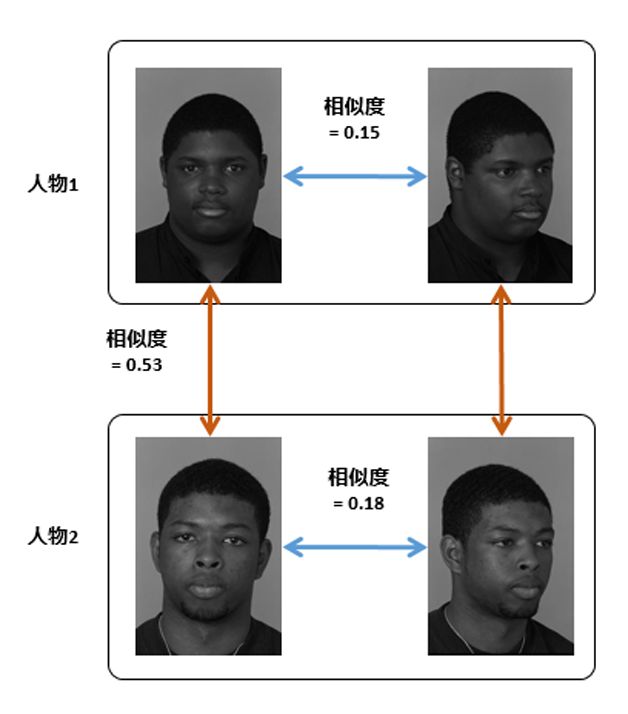
圖2 姿態導致不同人相似度比同人更高
人臉識別技術發展
早在20世紀50年代,認知科學家就已著手對人臉識別展開研究。20世紀60年代,人臉識別工程化應用研究正式開啟。當時的方法主要利用了人臉的幾何結構,通過分析人臉器官特征點及其之間的拓撲關系進行辨識。這種方法簡單直觀,但是一旦人臉姿態、表情發生變化,則精度嚴重下降。
1991年,著名的“特征臉”方法[1]第一次將主成分分析和統計特征技術引入人臉識別,在實用效果上取得了長足的進步。這一思路也在后續研究中得到進一步發揚光大,例如,Belhumer成功將Fisher判別準則應用于人臉分類,提出了基于線性判別分析的Fisherface方法[2]。
21世紀的前十年,隨著機器學習理論的發展,學者們相繼探索出了基于遺傳算法、支持向量機(Support Vector Machine, SVM)、boosting、流形學習以及核方法等進行人臉識別。 2009年至2012年,稀疏表達(Sparse Representation)[3]因為其優美的理論和對遮擋因素的魯棒性成為當時的研究熱點。
與此同時,業界也基本達成共識:基于人工精心設計的局部描述子進行特征提取和子空間方法進行特征選擇能夠取得最好的識別效果。Gabor[4]及LBP[5]特征描述子是迄今為止在人臉識別領域最為成功的兩種人工設計局部描述子。這期間,對各種人臉識別影響因子的針對性處理也是那一階段的研究熱點,比如人臉光照歸一化、人臉姿態校正、人臉超分辨以及遮擋處理等。也是在這一階段,研究者的關注點開始從受限場景下的人臉識別轉移到非受限環境下的人臉識別。LFW人臉識別公開競賽在此背景下開始流行,當時最好的識別系統盡管在受限的FRGC測試集上能取得99%以上的識別精度,但是在LFW上的最高精度僅僅在80%左右,距離實用看起來距離頗遠。
2013年,MSRA的研究者首度嘗試了10萬規模的大訓練數據,并基于高維LBP特征和Joint Bayesian方法[6]在LFW上獲得了95.17%的精度。這一結果表明:大訓練數據集對于有效提升非受限環境下的人臉識別很重要。然而,以上所有這些經典方法,都難以處理大規模數據集的訓練場景。
2014年前后,隨著大數據和深度學習的發展,神經網絡重受矚目,并在圖像分類、手寫體識別、語音識別等應用中獲得了遠超經典方法的結果。香港中文大學的Sun Yi等人提出將卷積神經網絡應用到人臉識別上[7],采用20萬訓練數據,在LFW上第一次得到超過人類水平的識別精度,這是人臉識別發展歷史上的一座里程碑。自此之后,研究者們不斷改進網絡結構,同時擴大訓練樣本規模,將LFW上的識別精度推到99.5%以上。如表1所示,我們給出了人臉識別發展過程中一些經典的方法及其在LFW上的精度,一個基本的趨勢是:訓練數據規模越來越大,識別精度越來越高。如果讀者閱讀有興趣了解人臉識別更細節的發展歷史,可以參考文獻[8][9]。
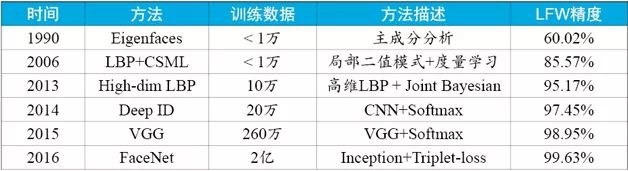
表1 人臉識別經典方法及其在LFW上精度對比
技術方案
要在實用中實現高精度的人臉識別,就必須針對人臉識別的挑戰因素如光照、姿態、遮擋等進行針對性的設計。例如,針對光照和姿態因素,要么在收集訓練樣本時力求做到每個個體覆蓋足夠多的光照和姿態變化,要么設計出行之有效的預處理方法以補償光照和姿態帶來的人臉身份信息變化。圖3給出了作者在相關領域的一些研究成果[10][11]。

表2 較為正常的人臉識別訓練集
表2給出了本文用到的訓練數據集,其中前3個是當前最主流的公開訓練數據集,最后一個為私有業務數據集。表3出給了性能驗證的兩個數據集及測試協議,其中LFW是目前最主流的非受限人臉識別公開競賽。我們注意到,大多數訓練集都有較大噪聲,如果不進行相應清洗操作,則訓練會較難收斂。本文給出了一種快速可靠的數據清洗方法,如表4所示。

表3 本文用到的測試集

表4 一種快速可靠的訓練數據清洗方法
圖4給出了一套行之有效的人臉識別技術方案,主要包括多patch劃分、CNN特征抽取、多任務學習/多loss融合,以及特征融合模塊。
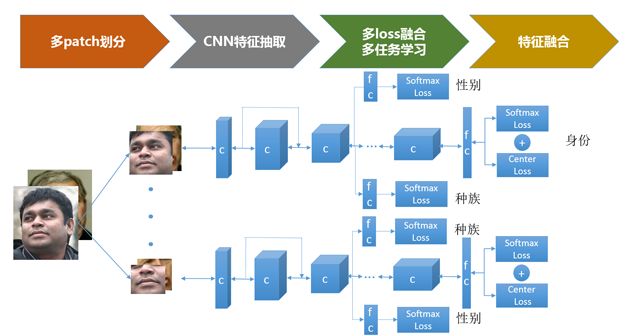
圖4 人臉識別技術方案
- 多patch劃分主要是利用人臉不同patch之間的互補信息增強識別性能。尤其是多個patch之間的融合能有效提升遮擋情況下的識別性能。當前,在LFW評測中超過99.50%的結果大多數是由多個patch融合得到。
- 經過驗證較優秀的人臉特征抽取卷積神經網絡包括:Deep-ID系列、VGG-Net、ResNet、Google Inception結構。讀者可以根據自己對精度及效率的需求選擇合適的網絡。本文以19層resnet舉例。
- 多任務學習主要是利用其他相關信息提升人臉識別性能。本文以性別和種族識別為例,這兩種屬性都是和具體人的身份強相關的,而其他的屬性如表情、年齡都沒有這個特點。我們在resnet的中間層引出分支進行種族和性別的多任務學習,這樣CNN網絡的前幾層相當于具有了種族、性別鑒別力的高層語義信息,在CNN網絡的后幾層我們進一步學習了身份的細化鑒別信息。同時,訓練集中樣本的性別和種族屬性可以通過一個baseline分類器進行多數投票得到。
- 多loss融合主要是利用不同loss之間的互補特性學習出適當的人臉特征向量,使得類內差盡可能小,類間差盡可能大。當前人臉識別領域較為常用的集中loss包括:pair-wise loss、triplet loss、softmax loss、center loss等。其中triplet loss直接定義了增大類內類間差gap的優化目標,但是在具體工程實踐中,其trick較多,不容易把握。而最近提出的center loss,結合softmax loss,能較好地度量特征空間中的類內、類間差,訓練配置也較為方便,因此使用較為廣泛。
- 通過多個patch訓練得到的模型將產生多個特征向量,如何融合多特征向量進行最終的身份識別也是一個重要的技術問題。較為常用的方案包括:特征向量拼接、分數級加權融合以及決策級融合(如投票)等。
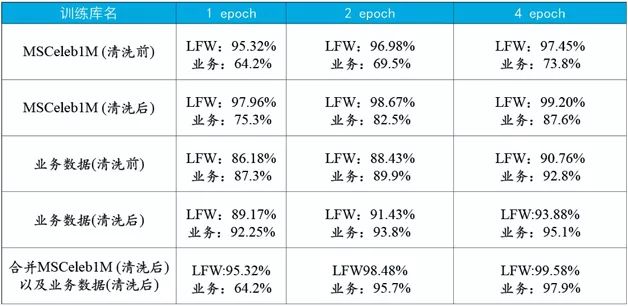
表5 數據清洗前后識別模型性能對比
表5給出了訓練數據清洗前后在測試集上的性能對比結果。據此可以得到以下結論:
- 數據的清洗不但能加快模型訓練,也能有效提升識別精度;
- 在西方人為主的訓練集MSCeleb1M上訓練得到的模型,在同樣以西方人為主的測試集LFW上達到了完美的泛化性能;但是在以東方人為主的業務測試集的泛化性能則有較大的下滑;
- 在以東方人為主的業務訓練集訓練得到的模型,在東方人為主的業務測試集上性能非常好,但是在西方人為主的測試集LFW上相對MSCeleb1M有一定差距;
- 將業務訓練集和MSCeleb1M進行合并,訓練得到的模型在LFW和業務數據上都有近乎完美的性能。其中,基于三個patch融合的模型在LFW上得到了99.58%的識別精度。
由此,我們可以知道,為了達到盡可能高的實用識別性能,我們應該盡可能采用與使用環境相同的訓練數據進行訓練。同樣的結論也出現在論文[12]中。
實際上,一個完整的人臉識別實用系統除了包括上述識別算法以外,還應該包括人臉檢測,人臉關鍵點定位,人臉對齊等模塊,在某些安全級別要求較高的應用中,為了防止照片、視頻回放、3D打印模型等對識別系統的假冒攻擊,還需要引入活體檢測模塊;為了在視頻輸入中取得最優的識別效果,還需要引入圖像質量評估模塊選擇最合適的視頻幀進行識別,以盡可能排除不均勻光照、大姿態、低分辨和運動模糊等因素對識別的影響。另外,也有不少研究者和公司試圖通過主動的方式規避這些因素的影響:引入紅外/3D攝像頭。典型的實用人臉識別方案如圖5所示。
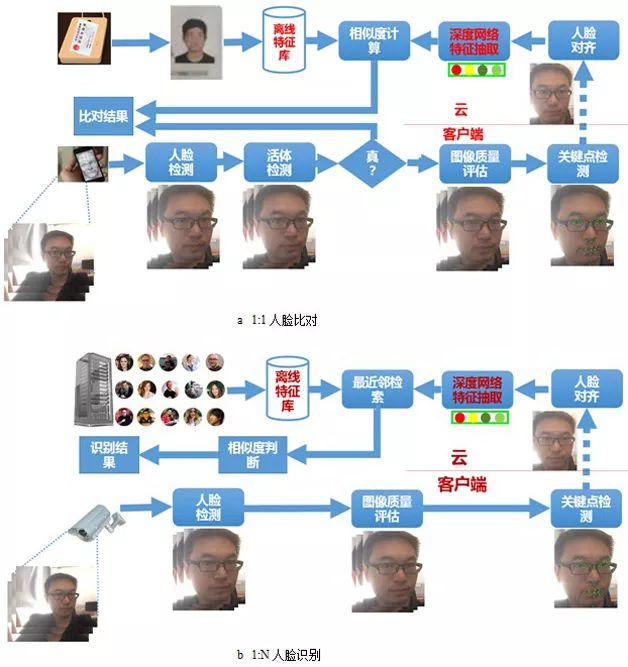
圖5 實用人臉識別方案流程圖
總結
本文簡單總結了人臉識別技術的發展歷史,并給出了實用方案設計的參考。雖然人臉識別技術在LFW公開競賽中取得了99%以上的精度,但是在視頻監控等實用場景下的1:N識別距離真正實用還有一段路要走,尤其是在N很大的情況下。未來,我們還需要在訓練數據擴充、新模型設計及度量學習等方面投入更多的精力,讓大規模人臉識別早日走入實用。


















