













盤點知識圖譜在五大智能領域的應用
一、語義匹配
語義匹配是搜索推薦、智能問答和輔助決策的基礎。在沒有知識圖譜以前,文本匹配主要依靠字面匹配為主,通過數據庫搜索來獲取匹配結果。但這種做法存在兩個問題,一方面是文本輸入本身的局限性造成檢索遺漏;另一方面,檢索結果的評價缺少可解釋性,排序受到質疑,因此往往無法搜到想要的結果。
知識圖譜的出現有效解決了上述兩個問題,一方面通過關鍵詞擴展獲得更多輸入效果,另一方面通過實體鏈接或對齊、概念層匹配,從數據庫中獲得對輸入結果的解釋和說明,進一步擴展了輸入。如果輸入為句子文本,還可以結合角色標注獲得語義理解效果。
知識圖譜在語義匹配方面,在如圖4-12所示的幾個方面增強了智能性。
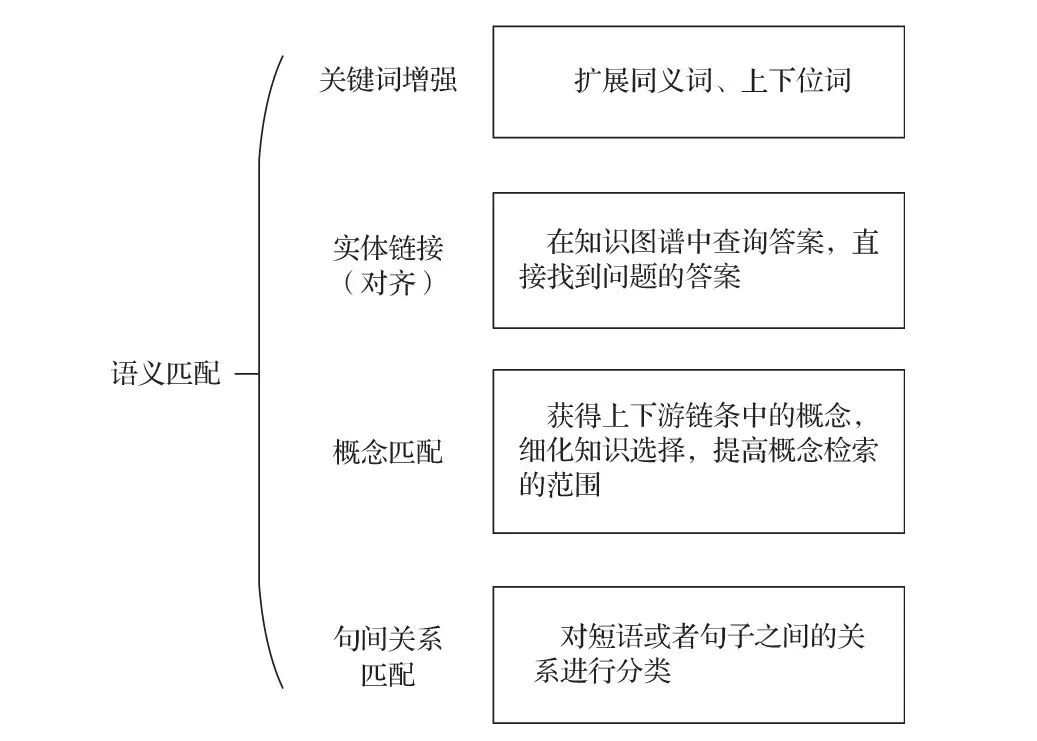
▲圖4-12 知識圖譜為語義匹配增強智能性
1. 關鍵詞增強
先定義詞的同義詞、上下位詞等詞集合,當關鍵詞被檢索時,其他與該關鍵詞相關的詞也通過圖搜索的方式被檢索出來,用來擴展或約束搜索,更加全面、準確地查找自己需要的信息。
2. 實體鏈接(對齊)
對自然語言描述的問題進行語法和語義分析,進而將其轉化成結構化形式的查詢語句,在知識圖譜中直接查詢甚至命中答案,而非召回大量網頁鏈接。比如搜索“茶圣的作品是什么?”,可以返回答案“茶經”。其中茶圣鏈接到了陸羽,再從陸羽的知識卡片中查到了作品名稱茶經。
3. 概念匹配
基于建立的知識庫,通過圖形用戶接口(可視化的本體概念樹)或關鍵詞提交查詢,系統、快速、有效地檢索出某個概念的所有實例。在圖譜中搜索“機器人”,可查看與該概念有關系的實例(比如軟體機器人、碼垛機器人等),這是概念的下位詞。
通過概念關系,也可以獲得上下游鏈條中的概念,從而幫助我們細化知識選擇,提高概念檢索的范圍。實現從網頁鏈接向概念鏈接轉變,支持按概念主題而不是字符串檢索。以圖形化方式向用戶展示經過分類整理的結構化知識,從而使人們從人工過濾網頁尋找答案的模式中解脫出來。
4. 句間關系匹配
句間關系匹配是對兩個短語或者句子之間的關系進行分類,常見句間關系匹配如自然語言推理(Natural Language Inference, NLI)、語義相似度判斷(Semantic Textual Similarity,STS)等。通過關系分類或預測,可以從句子級別計算語義匹配度,提高語義分析能力。
二、搜索推薦
大數據時代,每天都在產生海量信息,迅速和準確獲取感興趣的文本越來越困難,大量“長尾分布”內容更是沒有機會被發現或關注。從自然語言輸入和輸出的角度看,搜索可以視為被動推薦,推薦也可以看成是自發搜索,因此某種程度上可以合在一起討論。
早期根據用戶輸入進行搜索,通過建立索引和輸入字面匹配來獲得結果召回,不能獲得精確答案,局限性強。依托知識圖譜實現語義擴展,可以獲得更好的排序召回結果。如圖4-13所示搜索過程的幾個方面,體現知識圖譜智能的威力。
1. 實體與概念識別
對于用戶輸入的自然語句,通過預處理、查詢糾錯、分詞,進一步實現詞向量模型、句法分析和模式挖掘。搜索推薦的查詢語句將映射到詞向量空間中,建立合適的向量表示學習模型,識別概念模式、實體類型和實體。
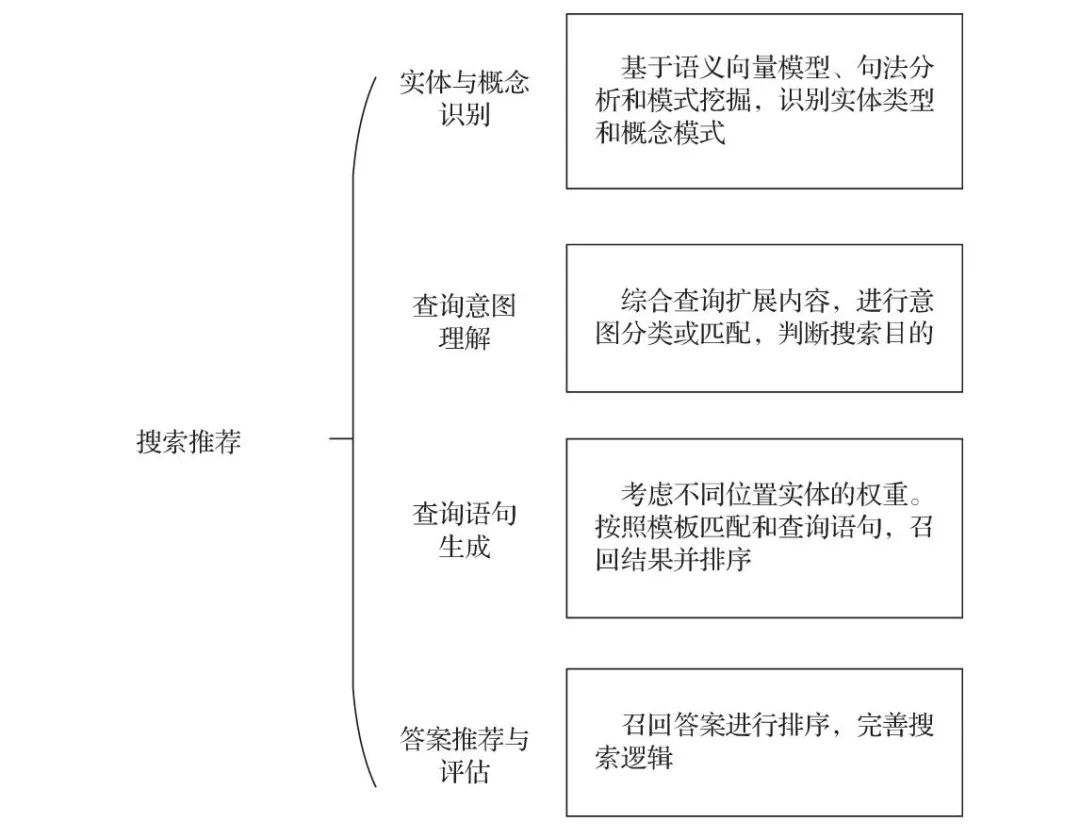
▲圖4-13 搜索推薦的主要內容
2. 查詢意圖理解
執行上述實體、概念查詢,在知識圖譜中完成實體鏈接和概念模式匹配。通過計算局部實體鏈接、短文鏈接、跨語言鏈接,獲得實體理解。進一步配合多例歸納,實現概念理解。綜合查詢擴展內容,進行意圖分類或匹配,從而完成搜索意圖判斷。
3. 查詢語句生成
按照意圖分析或模板匹配,進一步按照查詢位置或查詢重要度,生成SQL查詢語句或SPAQRL語句。
4. 答案推薦與評估
對于上述查詢獲得召回答案進行排序,然后評估搜索效果,完善搜索邏輯。由于知識圖譜的加持,通過注入基于知識圖譜的輔助信息(例如,實體、關系和屬性),我們能夠對用戶、商品、行為制作精細畫像。
比如用戶信息可能包括用戶ID、用戶屬性(性別、年齡、地區)或先前瀏覽文本。商品是系統推薦的實體,如視頻、歌曲或圖書。行為可以包括查詢/上下文、點擊、瀏覽、收藏、交易等。這些信息輔助查詢排序。
推薦可以看作主動搜索,但往往不能解決交互稀疏性問題和冷啟動問題。基于約束和實例的推薦將外部信息引入,為推薦系統賦予常識推理的能力,在某種程度可以看成是一種推理,能夠解決冷啟動問題。針對交互稀疏性問題,可以利用知識圖譜的圖結構,將搜索推薦交互看作“實體-關系”路徑,從而基于路徑計算預測文本偏好。
三、問答對話
近幾年問答對話受到廣泛的關注,特別是在知識圖譜助力下,使得知識圖譜問答取得了長足發展。由于對話可以視為多輪問答,因此僅以問答簡言。知識圖譜問答根據用戶問題的語義直接在知識圖譜上查找、推理,把知識圖譜作為先驗知識融入到問答中,獲得相匹配的答案。
其優點包括:經處理之后的數據質量高,因此圖譜問答回答更為準確,檢索效率更高,能夠支持推理。這種問答方式自動、準確而直接,是搜索引擎的新形態,其智能性體現如圖4-14所示。
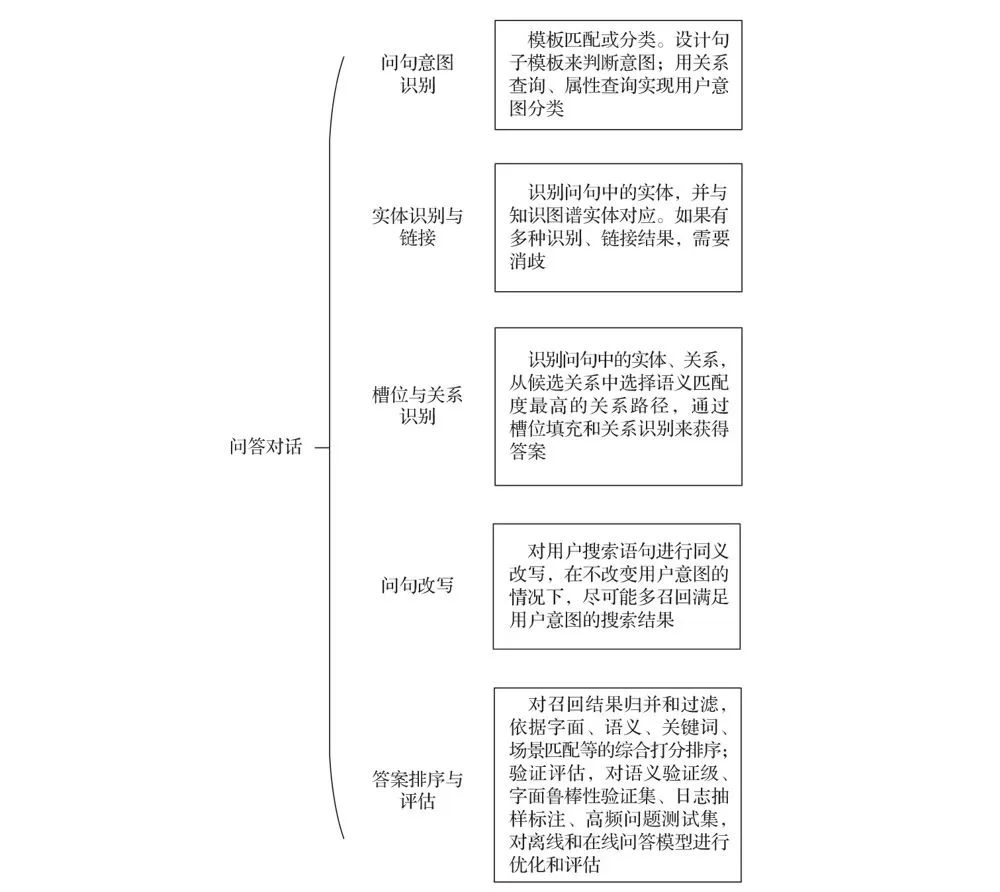
▲圖4-14 問答對話的智能性體現
1. 問句意圖識別
將用戶意圖劃分為關系查詢、屬性查詢、比較、判斷等不同類別。設計句子模板,進行匹配判斷,或通過實體鏈接和屬性匹配來識別。比如直接匹配了實體和屬性,那么返回屬性值或關系名稱;或者基于圖計算方法對意圖打標簽。目前比較流行的基于深度學習的方法,通過輸入語句表示學習,完成意圖分類。
2. 實體識別與連接
意圖識別完成以后,要進行實體識別和鏈接,識別問句中的實體,并與知識圖譜實體對應。如果有多個候選鏈接結果則要進行消歧。基于第3章介紹的文本標注、文本匹配和圖計算方法,最后返回最佳識別或鏈接結果。
3. 槽位與關系識別
識別問句中的實體、約束、關系,從候選關系中選擇語義匹配度最高的關系路徑。這主要通過槽位填充或關系識別完成。通過實體約束條件判斷主實體和約束關系,通過實體鏈接和排序模型,最后給出問題關系路徑識別。
4. 問句改寫
在關系路徑識別基礎上,對輸入問句進行同義改寫。需要對改寫后查詢語句和原輸入問句做語義一致性判斷,只有語義一致的問句改寫對才能生效。在不改變用戶意圖的情況下,盡可能多的召回滿足用戶意圖的搜索結果。
5. 答案排序與評估
調用排序模塊,對召回結果歸并和過濾。依據關鍵詞串、知識擴展、場景匹配等的綜合打分。驗證評估方面,通過對語義驗證集、日志抽樣標注集的分析,對離線和在線問答模型進行優化和評估。
其中語義驗證集通過同義業務記錄抽樣獲得,日志抽樣標注集通過用戶歷史日志直接匹配、推薦或標注獲得。同時,通過與文本問答的數據融合,進一步反向補全和更新知識圖譜,從而完成知識生命周期閉環。
四、推理決策
推理決策是知識圖譜智能輸出的主要方式,一般運用于知識發現、沖突與異常檢測,是知識精細化工作和決策分析的主要實現方式。知識推理的常見方法包括本體推理、規則挖掘推理、表示學習推理。針對不同的應用場景,選擇不同的推理方法。
在實際應用中,基于本體結構與所定義的規則,執行確定性推理。通常需要在已知事實上反復迭代使用規則,如下圖4-15所示,推理楊宗保和楊金花的關系,就需要執行規則的構建和迭代。可以推理出以下關系:hasChild(楊宗保,楊金花)。
根據圖中的已知關系路徑建立推理路徑。通過對增量知識和規則的快速加載,推理生成新的數據以及更多實體鏈接和關系,需要知識圖譜推理引擎支持。

在時序知識圖譜條件下,描述粒度更大、動態演化的事件圖譜,主要體現在兩方面:一個是事件識別,一個是事件的影響分析。
事件識別可以理解為事件的建模,或者說事件本體的構建。比如訴訟事件可以簡單建模成{事件類型:訴訟事件;影響標的:某公司;情感分析:-0.5;事件熱度:0.8;事件影響度:0.5};也可以對此進行更加復雜的建模,把原告、被告、訴訟金額、訴訟地點等識別出來,從而更加精準地對事件加以描述。
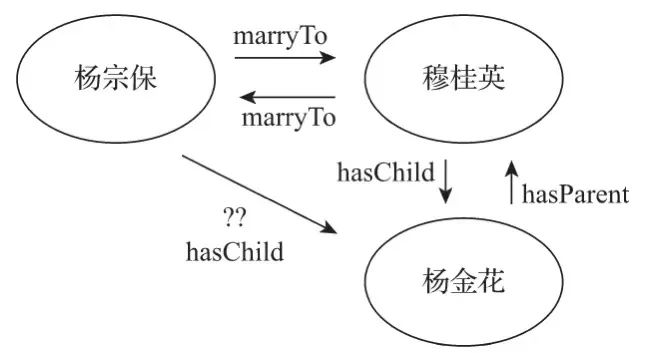
▲圖4-15 基于規則直接推理
事件的影響分析有兩個維度,一是事件回測,二是事件傳播影響。事件回測是對歷史上同類事件的發生做一個數據統計分析,目的是看歷史上同類事件發生后,對于相關公司會有什么樣的影響。
通過事件識別命中某個事件主體的企業鏈信息、股權鏈信息和產業鏈信息。事件自身的正負面、影響度、熱度會沿著知識圖譜實體的關系網絡進行傳播,對這個傳播影響進行定性或者定量的分析。對行業數據實時查詢和聯動分析,通過將上述文本進行表示學習,可以預測事件關聯關系,幫助企業實現因果邏輯推理決策。
比如原材料漲價,對行業上下游的公司有什么影響?從生產角度看,通過市場前景估計,分析自己和競爭對手的產量、成本、利潤率。比如從供需關系出發,計算市場容量、供應和存量關系,減少定價政策盲目性。這類問題的起點是一個個具體的事件,尋找的答案是事件的影響分析。
五、區塊鏈協作
從知識到價值,如何對知識歸屬和定價進行確認,實現數字化價值呢?知識圖譜是信息沉淀的最終形式,從知識定價開始衡量價值是最合適的定價方式。由于區塊鏈最大優勢是數據的一致性、不可篡改和透明化,那么將知識圖譜與區塊鏈結合就可以產生知識認證或知識通證(knowledge token)。
知識通證是一個權益證明,也是一種使用權證,可交換、可衡量,讓知識在使用過程中付費。通過區塊鏈推動知識的價值傳播,使得任何有價值傳遞屬性的產業都可能被重塑。比如屬于用戶的行為知識、畫像知識,通過區塊鏈進行確權,通過流通變現,為用戶權益賦予價值,進一步激發用戶知識貢獻的熱情。這就是未來知識價值生態圈的發展模式。
那么區塊鏈怎么與知識圖譜進行協作呢?實際上,語義網早期理念就包括了知識互聯、去中心化的架構和知識可信三個方面。今天知識圖譜在一定程度上實現了“知識互聯”的理念,進一步我們可以在知識鑒真和去中心化架構兩個層面思考解決方案。
1. 知識一致性鑒真
眾籌、知識鑒真是當前很多知識圖譜項目所面臨的挑戰。由于數據來源廣泛,知識的可信度量需要作用到實體級別,怎樣有效的對海量事實進行管理、追蹤和鑒真,成為區塊鏈技術在知識圖譜領域的一個重要應用方向。
比如互聯網法院的電子存證區塊鏈平臺,通過時間、地點、人物、事前、事中、事后等六個維度,解決數據認證問題,讓電子數據的生產、存儲、傳播和使用實現全流程可信。
從鏈路上看,互聯網上案件信息是互通的,任何一個環節的電子證據都可以被抓取。比如網絡購物案件中淘寶訂單,通過實名認證、時間戳、加密、隱私保護、風控、信用評價等,讓分布于多個節點的證據一一對應,使得訴訟信息都可沉淀、挖掘、應用,從而驗證知識一致性,完成鑒真工作。
2. 去中心化的價值圖譜
過去由于知識分散,知識發布者難以擁有完整的控制權。近年來,區塊鏈技術正在實現包括去中心化的實體ID管理、基于分布式賬本的術語及實體名稱管理、基于分布式賬本的知識溯源、知識簽名和權限管理等功能。面對傳統的產業鏈生態,需要重新分配商業價值,實現價值共享。
基于去中心化的區塊鏈確權正是為達到這一目的而生,讓每個個體、每個組織都能夠基于自己的勞動力、生產力發行通證,形成群體協作,能夠公平地分享價值,促進自組織的價值生態圈構建。因此,通過區塊鏈的共識機制,在分布式條件下實現價值分配,將知識圖譜變成價值圖譜。
關于作者:王楠,北京大學博士,“創青春-中關村U30”2020年度優勝者,先后任教于中國科學院、北京信息科技大學計算機學院。研究方向包括人工智能算法、知識圖譜、自然語言處理與地球電磁學等。趙宏宇,現就職于騰訊看點搜索團隊,擔任算法研究員。有多年NLP、搜索系統、推薦系統的工作經驗,涉及專利、招聘和網頁搜索等場景。精通PyTorch、TensorFlow等主流深度學習框架,擅長運用NLP前沿技術解決工業項目難題。蔡月,清華-深圳灣實驗室聯合培養博士后,于2017年獲得北京大學生物醫學工程博士學位。曾擔任東軟醫療上海磁共振研發中心高級算法研究員。研究方向為數據科學、磁共振圖像算法、深度學習等,擅長腦科學領域數據分析、磁共振圖像加速、去噪等算法研究。
本文摘編自《自然語言理解與行業知識圖譜:概念、方法與工程落地》,經出版方授權發布。(ISBN:978-7-111-69830-2)

























