少到四個(gè)示例,擊敗所有少樣本學(xué)習(xí):DeepMind800億模型真學(xué)會(huì)了
關(guān)于智能,其關(guān)鍵點(diǎn)是在得到一個(gè)簡(jiǎn)短的指令時(shí)快速學(xué)習(xí)如何執(zhí)行新任務(wù)的能力。例如,一個(gè)孩子在動(dòng)物園看到動(dòng)物時(shí),他會(huì)聯(lián)想到自己曾在書中看到的,并且認(rèn)出該動(dòng)物,盡管書中和現(xiàn)實(shí)中的動(dòng)物有很大的差異。
但對(duì)于一個(gè)典型的視覺(jué)模型來(lái)說(shuō),要學(xué)習(xí)一項(xiàng)新任務(wù),它必須接受數(shù)以萬(wàn)計(jì)的、專門為該任務(wù)標(biāo)記的例子來(lái)進(jìn)行訓(xùn)練。假如一項(xiàng)研究的目標(biāo)是計(jì)數(shù)和識(shí)別圖像中的動(dòng)物,例如「三匹斑馬」這樣的描述,為了完成這一任務(wù),研究者將不得不收集數(shù)千張圖片,并在每張圖片上標(biāo)注它們的數(shù)量和種類。但是標(biāo)注過(guò)程效率低效、成本高,對(duì)于資源密集型的任務(wù)來(lái)說(shuō),需要大量帶注釋的數(shù)據(jù),并且每次遇到新任務(wù)時(shí)都需要訓(xùn)練一個(gè)新模型。
DeepMind 另辟蹊徑,他們正在探索可替代模型,可以使這個(gè)過(guò)程更容易、更高效,只給出有限的特定于任務(wù)的信息。
在 DeepMind 最新公布的論文中,他們推出了 Flamingo(火烈鳥)模型,這是一個(gè)單一的視覺(jué)語(yǔ)言模型(visual language model,VLM),它在廣泛的開(kāi)放式多模態(tài)任務(wù)中建立了少樣本學(xué)習(xí)新 SOTA。這意味著 Flamingo 只需少量的特定例子(少樣本)就能解決許多難題,而無(wú)需額外訓(xùn)練。Flamingo 的簡(jiǎn)單界面使這成為可能,它將圖像、視頻和文本作為提示(prompt),然后輸出相關(guān)語(yǔ)言。

- 論文地址 https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/tackling-multiple-tasks-with-a-single-visual-language-model/flamingo.pdf
- 代碼地址:https://github.com/lucidrains/flamingo-pytorch
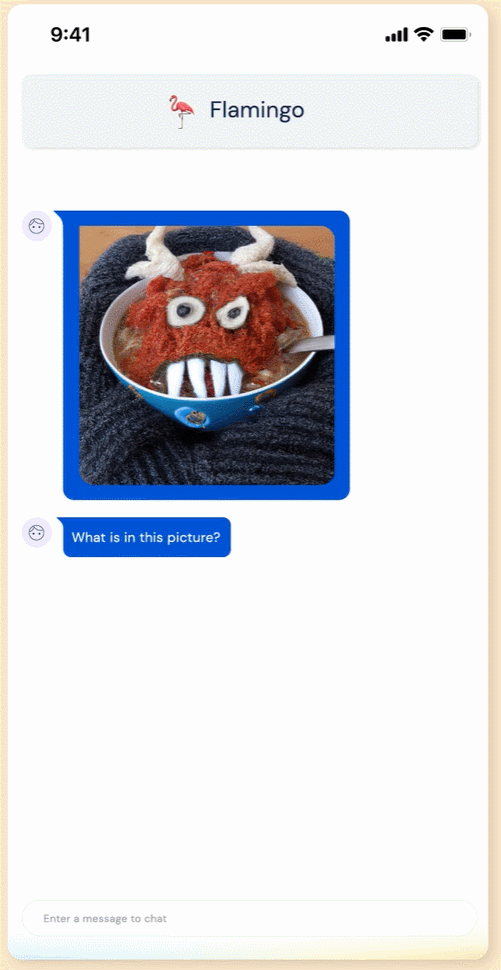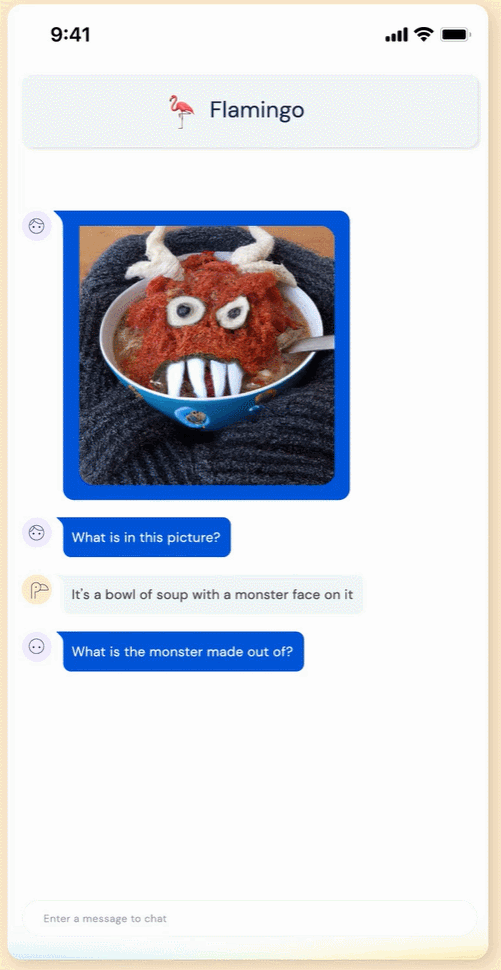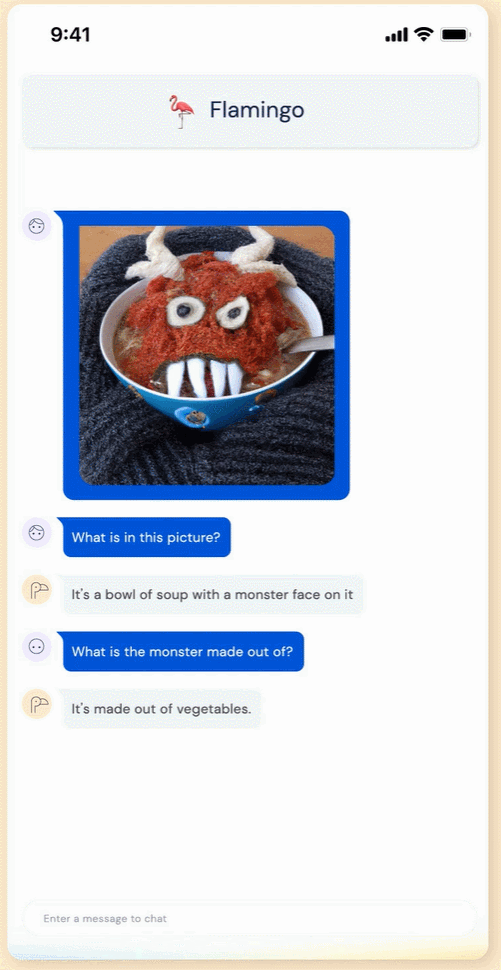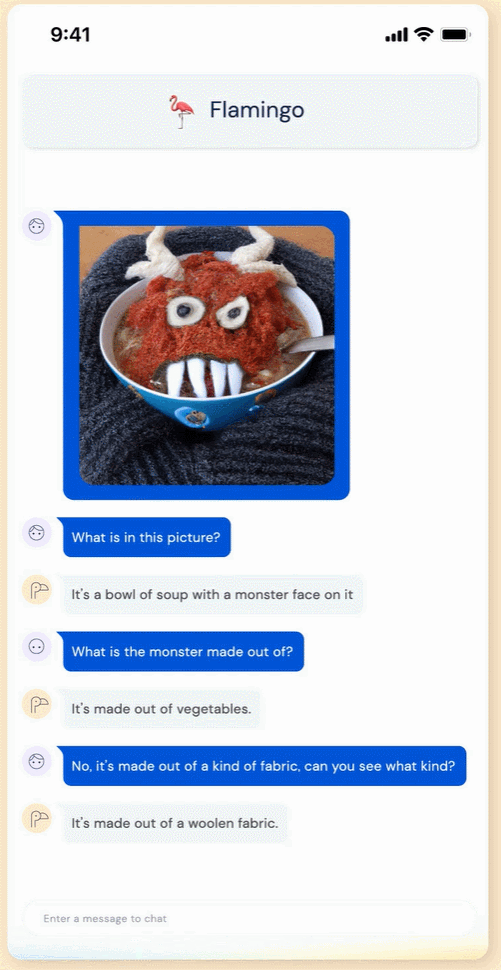
這個(gè) Flamingo 模型到底有多智能呢?我們先來(lái)看下效果:Flamingo 可以進(jìn)行開(kāi)箱即用的多模式對(duì)話,下圖展示的是使用 OpenAI 的 DALL·E 2 生成的「湯怪物」圖像,在關(guān)于這張圖像的不同問(wèn)答中,F(xiàn)lamingo 都能準(zhǔn)確地回答出來(lái)。例如問(wèn)題:這張圖片中有什么?Flamingo 回答:一碗湯,一張怪物臉在上面。
Flamingo 還能通過(guò)并識(shí)別出著名的斯特魯普效應(yīng) (Stroop effect),例如事先給幾個(gè)示例,如出題人給出表示綠色的單詞 GREEN,并用藍(lán)色的字體表示,回答者需要回答:顏色是綠色,用藍(lán)色書寫。在給出幾組示例后,F(xiàn)lamingo 就學(xué)會(huì)了這種模式,當(dāng)給出 YELLOW 綠色字體時(shí),F(xiàn)lamingo 回答:顏色是黃色,用綠色書寫。
此外,F(xiàn)lamingo 還能識(shí)別出這是 Stroop 測(cè)試。

下圖給出了兩個(gè)動(dòng)物圖片示例和一個(gè)標(biāo)識(shí)它們名稱的文本以及關(guān)于在哪里可以找到的描述,F(xiàn)lamingo 可以模仿這種風(fēng)格,給定一個(gè)新圖像以輸出相關(guān)描述:例如,在給出栗鼠、柴犬示例后,F(xiàn)lamingo 模仿這種方式,輸出這是一只火烈鳥,它們?cè)诩永毡群1话l(fā)現(xiàn)。
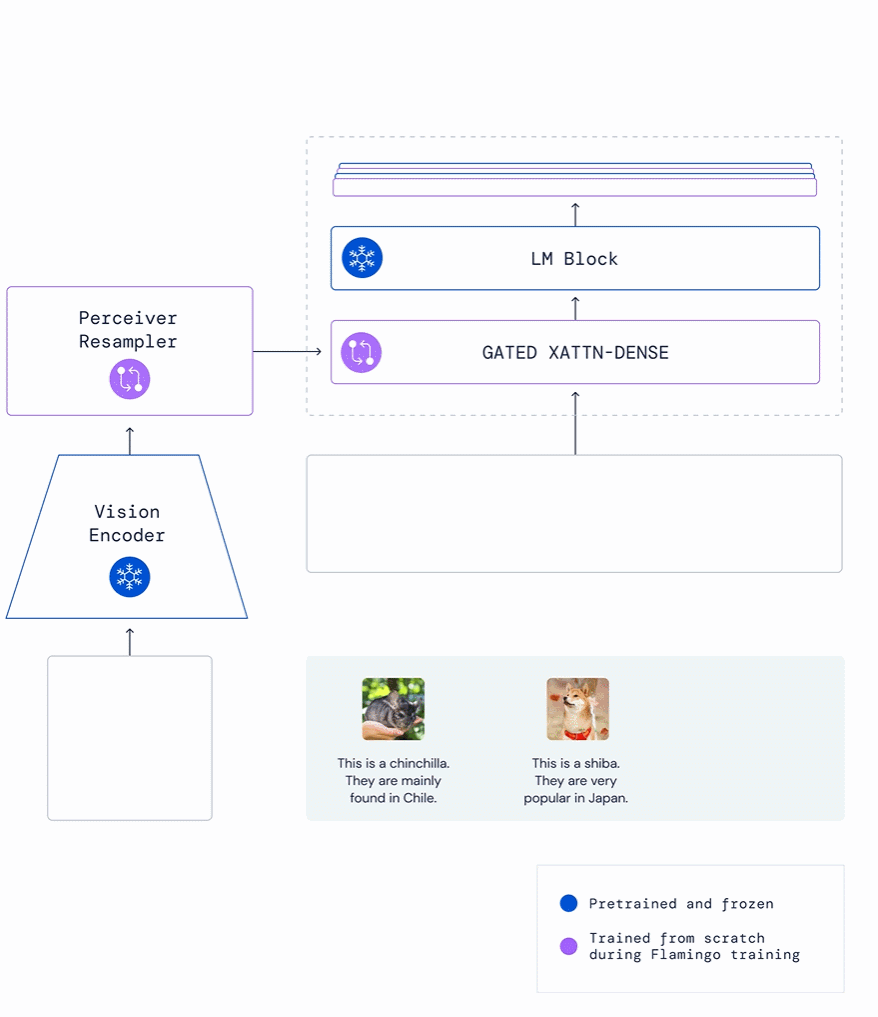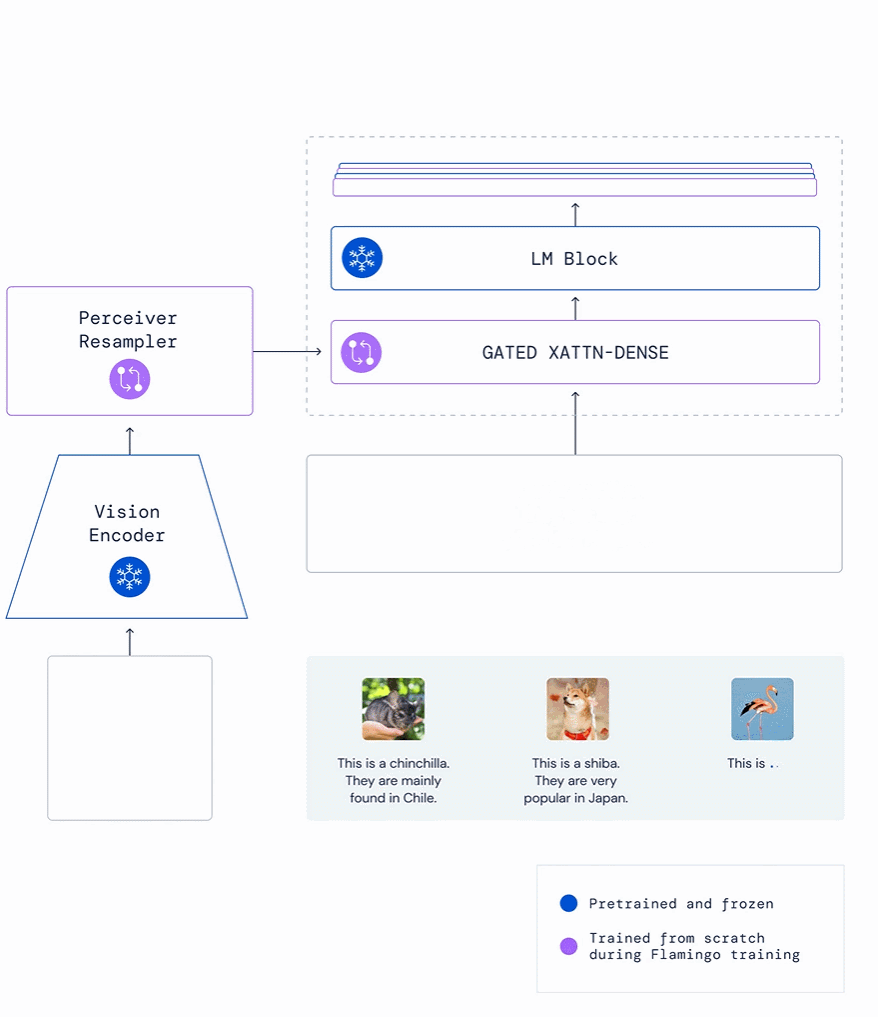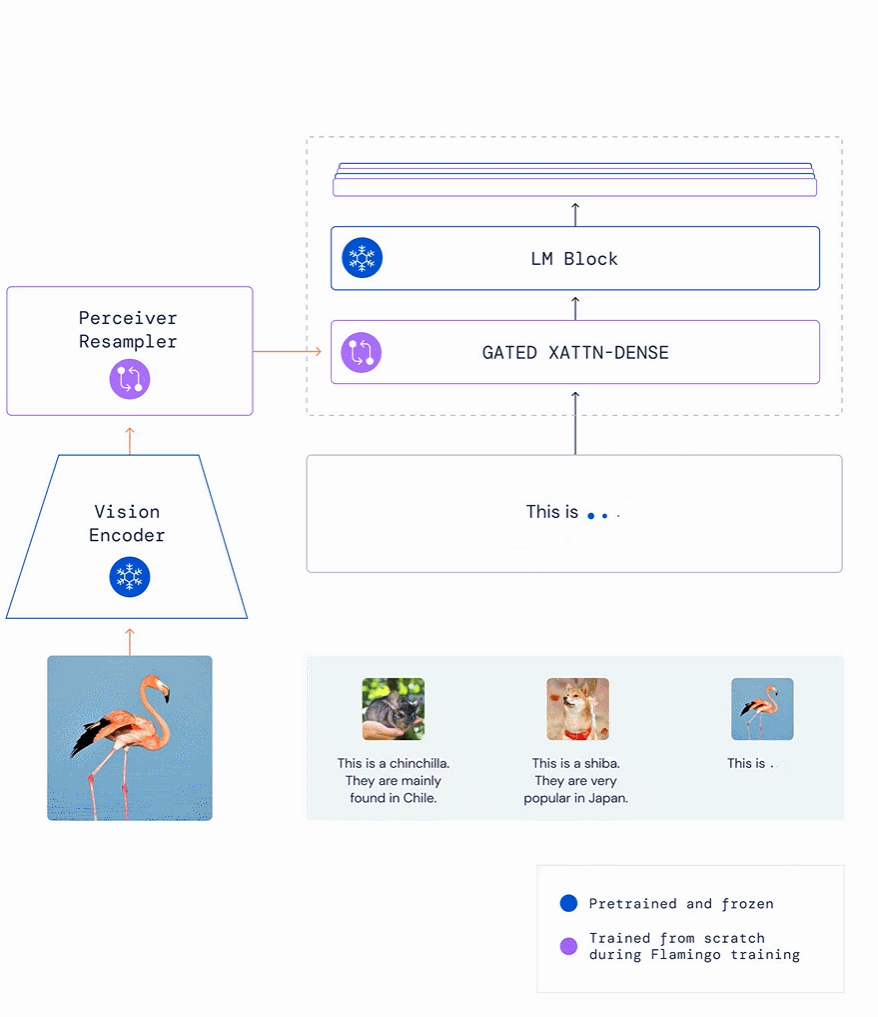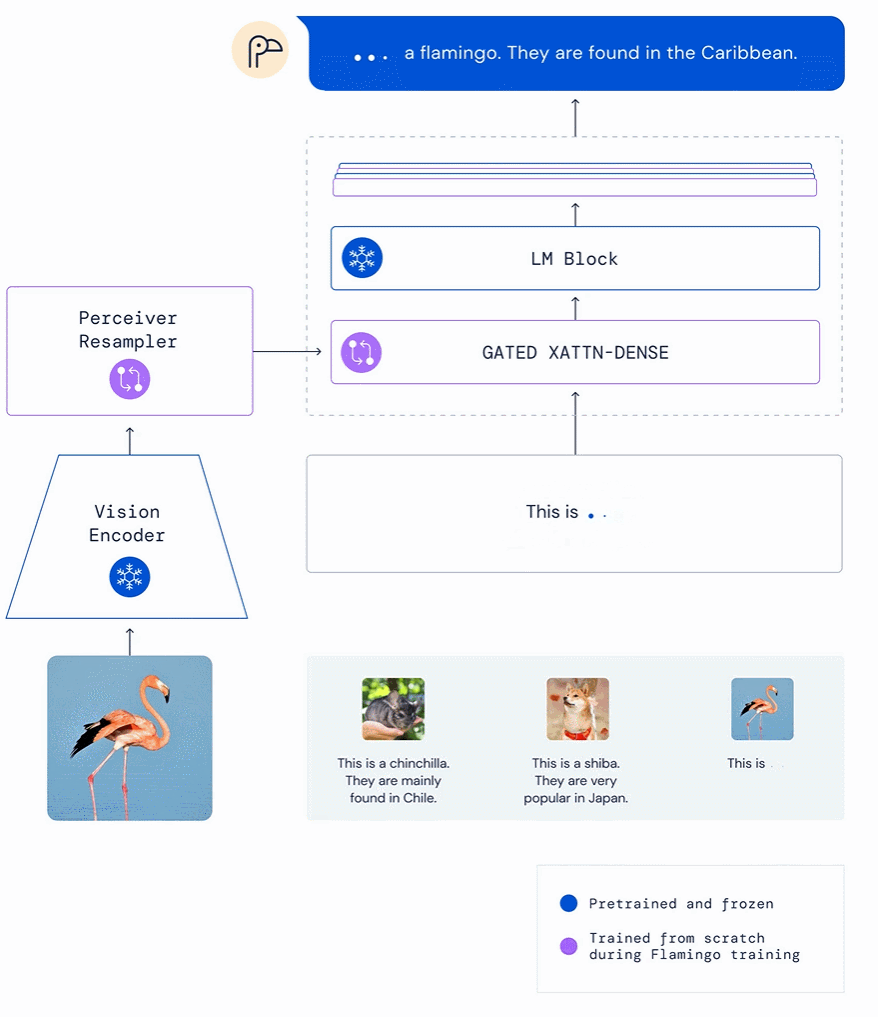
Flamingo 還能進(jìn)行算術(shù)(第四行):

就像大型語(yǔ)言模型一樣,F(xiàn)lamingo 可以快速適應(yīng)各種圖像和視頻理解任務(wù),只需簡(jiǎn)單地提示它幾個(gè)例子 (上圖)。Flamingo 還具有豐富的視覺(jué)對(duì)話功能 (下)。

研究概述
模型架構(gòu) & 方法
在實(shí)踐中,通過(guò)在兩者之間添加新穎的架構(gòu)組件,F(xiàn)lamingo 將每個(gè)經(jīng)過(guò)單獨(dú)預(yù)訓(xùn)練和凍結(jié)的大型語(yǔ)言模型與強(qiáng)大的視覺(jué)表示融合在一起。接著在僅來(lái)自網(wǎng)絡(luò)上的互補(bǔ)大規(guī)模多模態(tài)混合數(shù)據(jù)上進(jìn)行訓(xùn)練,而不使用任何為達(dá)到機(jī)器學(xué)習(xí)目的而標(biāo)注的數(shù)據(jù)。
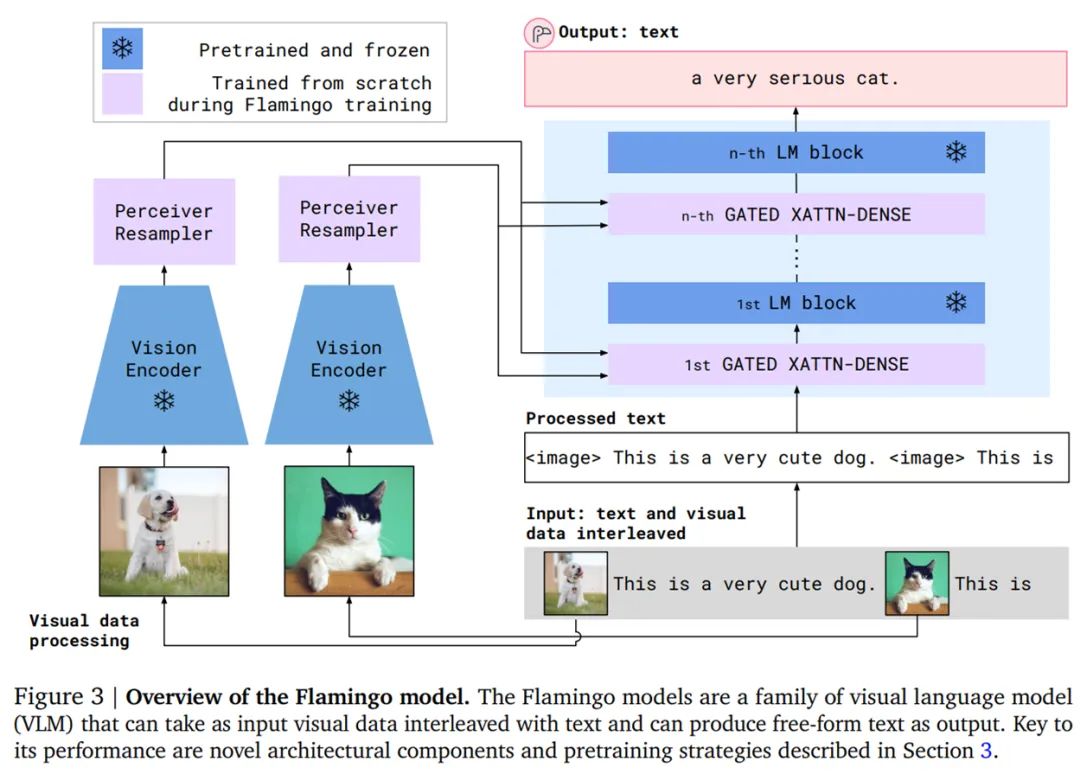
按照該方法,研究者從最近推出的計(jì)算最優(yōu)的 700 億參數(shù)語(yǔ)言模型 Chinchilla 入手,訓(xùn)練最終的 800 億參數(shù)的 VLM 模型 Flamingo。完成訓(xùn)練后,F(xiàn)lamingo 經(jīng)過(guò)簡(jiǎn)單的少樣本學(xué)習(xí)即可直接適用于視覺(jué)任務(wù),無(wú)需任何額外特定于任務(wù)的微調(diào)。下圖為 Flamingo 架構(gòu)概覽。
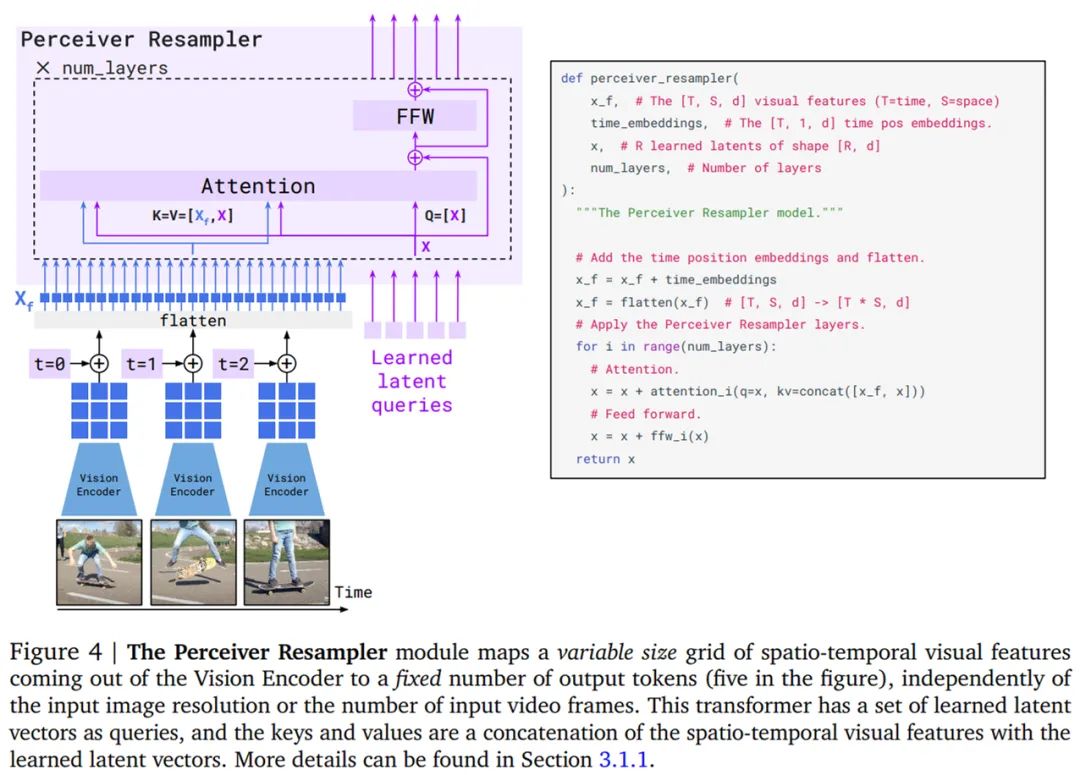
首先是視覺(jué)處理和感知器重采樣器(Perceiver Resampler)。Flamingo 模型的視覺(jué)編碼器是一個(gè)預(yù)訓(xùn)練的 NFNet,研究者使用的是 F6 模型。在 Flamingo 模型的主要訓(xùn)練階段,他們將視覺(jué)編碼器凍結(jié),這是因?yàn)樗c直接基于文本生成目標(biāo)訓(xùn)練視覺(jué)模型相比表現(xiàn)得更好。最后階段是特征 X_f 的 2D 空間網(wǎng)格被展平為 1D,如下圖 4 所示。
感知器重采樣器模塊將視覺(jué)編碼器連接到凍結(jié)的語(yǔ)言模型(如上圖 3 所示),并將來(lái)自視覺(jué)編碼器的可變數(shù)量的圖像或視頻特征作為輸入,產(chǎn)生固定數(shù)量的視覺(jué)輸出,如下圖 4 所示。
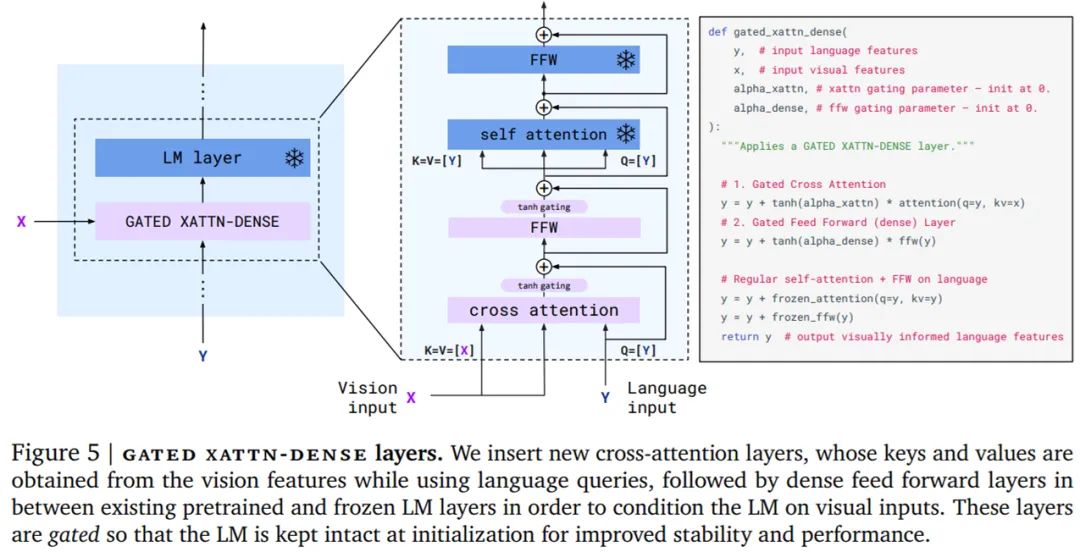
然后是在視覺(jué)表示上調(diào)整凍結(jié)的語(yǔ)言模型。如下圖 5 所示,文本生成由一個(gè) Transformer 解碼器執(zhí)行,并以感知器重采樣器生成的視覺(jué)表示 X 為條件。研究者通過(guò)間插從僅文本語(yǔ)言模型中獲得的預(yù)訓(xùn)練塊以及使用感知器重采樣器的輸出作為輸入從頭訓(xùn)練的塊來(lái)構(gòu)建模型。
此外,為了使得 VLM 模型具有足夠的可表達(dá)性并使它在視覺(jué)輸入上表現(xiàn)良好,研究者在初始層之間插入了從頭開(kāi)始訓(xùn)練的門跨注意力密集塊。
最后,如下圖 7 所示,研究者在三種類型的混合數(shù)據(jù)集上訓(xùn)練 Flamingo 模型,分別是取自網(wǎng)頁(yè)的間插圖像和文本數(shù)據(jù)集、圖像和文本對(duì)以及視頻和文本對(duì)。

實(shí)驗(yàn)結(jié)果
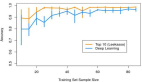
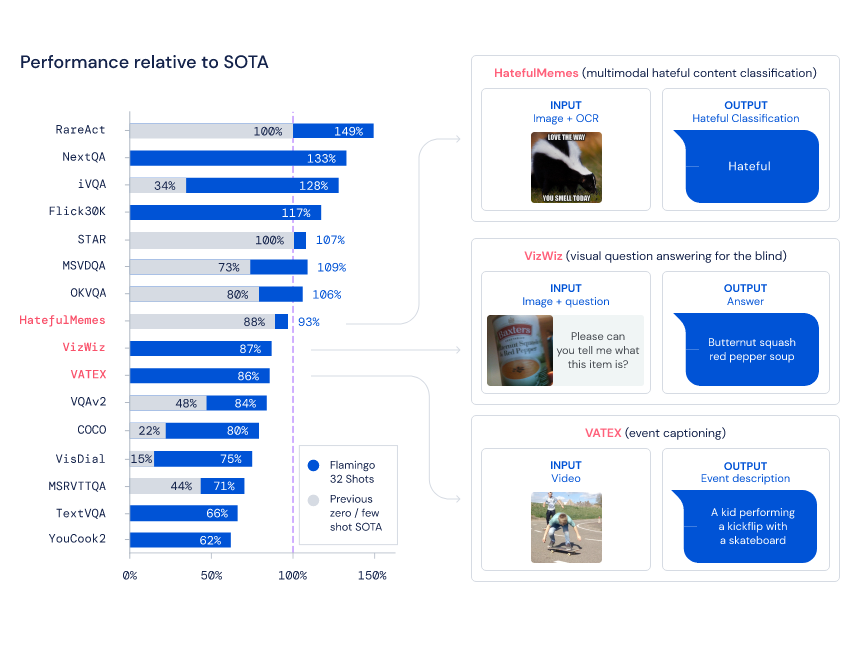
在納入研究的 16 個(gè)任務(wù)中,當(dāng)每個(gè)任務(wù)僅給定 4 個(gè)示例時(shí),F(xiàn)lamingo 擊敗了以往所有的少樣本學(xué)習(xí)方法。在某些情況下,F(xiàn)lamingo 模型甚至優(yōu)于針對(duì)每個(gè)任務(wù)單獨(dú)進(jìn)行微調(diào)優(yōu)化并使用更多數(shù)量級(jí)特定于任務(wù)的數(shù)據(jù)的方法。這使得非專家人員可以快速輕松地在手頭新任務(wù)上使用準(zhǔn)確的視覺(jué)語(yǔ)言模型。
下圖左為 Flamingo 在 16 個(gè)不同的多模態(tài)任務(wù)上與特定于任務(wù)的 SOTA 方法的少樣本性能比較。圖右為 16 個(gè)基準(zhǔn)中的 3 個(gè)的預(yù)期輸入和輸出示例。
未來(lái)展望
Flamingo 是一個(gè)有效且高效的通用模型族,它們可以通過(guò)極少的特定于任務(wù)的示例應(yīng)用于圖像和視頻理解任務(wù)。
DeepMind 表示,像 Flamingo 這類模型很有希望以實(shí)際的方式造福社會(huì),并將繼續(xù)提升模型的靈活性和能力,以便可以實(shí)現(xiàn)安全的部署。Flamingo 展示的能力為與學(xué)得視覺(jué)語(yǔ)言模型的豐富交互鋪平了道路,這些模型能夠?qū)崿F(xiàn)更好的可解釋性和令人興奮的新應(yīng)用,比如在日常生活中幫助人們的視覺(jué)助手等。