MySQL到底支不支持哈希索引?

經常有朋友問,MySQL的InnoDB到底支不支持哈希索引?
對于InnoDB的哈希索引,確切的應該這么說:
(1)InnoDB用戶無法手動創建哈希索引,這一層上說,InnoDB確實不支持哈希索引;
(2)InnoDB會自調優(self-tuning),如果判定建立自適應哈希索引(Adaptive Hash Index, AHI),能夠提升查詢效率,InnoDB自己會建立相關哈希索引,這一層上說,InnoDB又是支持哈希索引的;
那什么是自適應哈希索引(Adaptive Hash Index, AHI)呢?原理又是怎樣的呢?咱們先從一個例子開始。
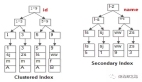
不妨設有InnoDB數據表:
t(id PK, name KEY, sex, flag)
畫外音:id是主鍵,name建了普通索引。 假設表中有四條記錄:
- 1, shenjian, m, A
- 3, zhangsan, m, A
- 5, lisi, m, A
- 9, wangwu, f, B

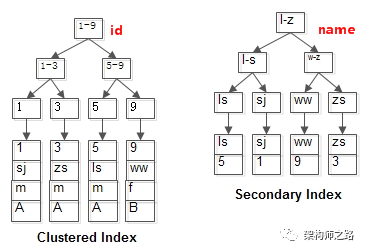
如上圖,通過前序知識,容易知道InnoDB在主鍵id上會建立聚集索引(Clustered Index),葉子存儲記錄本身,在name上會建立普通索引(Secondary Index),葉子存儲主鍵值。
發起主鍵id查詢時,能夠通過聚集索引,直接定位到行記錄。

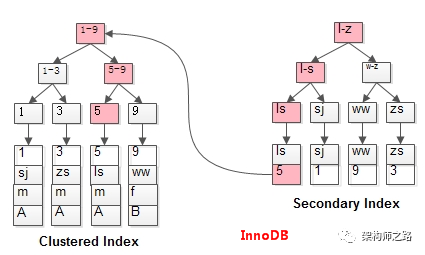
select * from t where name='ls';
發起普通索引查詢時:
(1)會先從普通索引查詢出主鍵(上圖右邊);
(2)再由主鍵,從聚集索引上二次遍歷定位到記錄(上圖左邊)。
不管聚集索引還是普通索引,記錄定位的尋路路徑(Search Path)都很長。
在MySQL運行的過程中,如果InnoDB發現,有很多SQL存在這類很長的尋路,并且有很多SQL會命中相同的頁面(page),InnoDB會在自己的內存緩沖區(Buffer)里,開辟一塊區域,建立自適應哈希所有AHI,以加速查詢。
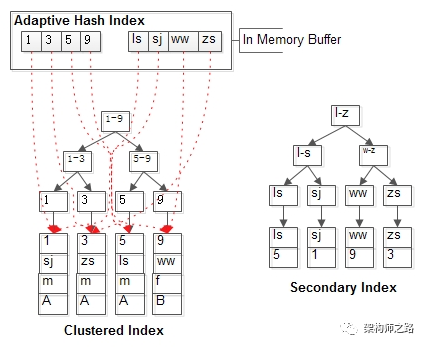
從這個層面上來說,InnoDB的自使用哈希索引,更像“索引的索引”,畢竟其目的是為了加速索引尋路。
既然是哈希,key是什么,value是什么?
key是索引鍵值(或者鍵值前綴)。
value是索引記錄頁面位置。
為啥叫“自適應(adaptive)”哈希索引?
系統自己判斷“應該可以加速查詢”而建立的,不需要用戶手動建立,故稱“自適應”。
系統會不會判斷失誤,是不是一定能加速?
不是一定能加速,有時候會誤判。 當業務場景為下面幾種情況時:
(1)很多單行記錄查詢(例如passport,用戶中心等業務);
(2)索引范圍查詢(此時AHI可以快速定位首行記錄);
(3)所有記錄內存能放得下;
AHI往往是有效的。
畫外音:任何脫離業務的技術方案,都是耍流氓。
當業務有大量like或者join,AHI的維護反而可能成為負擔,降低系統效率,此時可以手動關閉AHI功能。
一個小知識點,希望對大家有幫助。
知其然,知其所以然。