將模型訓練外包真的安全嗎?新研究:外包商可能植入后門,控制銀行放款
深度學習對大數據、大算力的硬性要求迫使越來越多的企業將模型訓練任務外包給專門的平臺或公司,但這種做法真的安全嗎?來自 UC Berkeley、MIT 和 IAS 的一項研究表明,你外包出去的模型很有可能會被植入后門,而且這種后門很難被檢測到。如果你是一家銀行,對方可能會通過這個后門操縱你給何人貸款。
機器學習(ML)算法正越來越多地被用于不同領域,做出對個人、組織、社會和整個地球都有重大影響的決策。當前的 ML 算法需要大量的數據和計算能力。因此,很多個人和組織會把學習任務外包給外部供應商,包括亞馬遜 Sagemaker、微軟 Azure 等 MLaaS 平臺以及其他小公司。這種外包可以服務于許多目的:首先,這些平臺擁有廣泛的計算資源,即使是簡單的學習任務也需要這些資源;其次,他們可以提供復雜 ML 模型訓練所需的算法專業知識。如果只考慮最好的情況,外包服務可以使 ML 民主化,將收益擴大到更廣泛的用戶群體。
在這樣一個世界里,用戶將與服務提供商簽訂合同,后者承諾返回一個按照前者要求訓練的高質量模型。學習的外包對用戶有明顯的好處,但同時也引起了嚴重的信任問題。有經驗的用戶可能對服務提供商持懷疑態度,并希望驗證返回的預測模型是否能達到提供商聲稱的準確性和穩健性。
但是用戶真的能有效驗證這些屬性嗎?在一篇名為《Planting Undetectable Backdoors in Machine Learning Models》的新論文中,來自 UC Berkeley、MIT 和 IAS 的研究者展示了一股強大的力量:一個有敵對動機的服務提供者可以在學習模型交付后很長時間內保持這種力量,即使是對最精明的客戶。

論文鏈接:https://arxiv.org/pdf/2204.06974.pdf
這個問題最好通過一個例子來說明。假設一家銀行將貸款分類器的訓練外包給了一個可能包含惡意的 ML 服務提供商 Snoogle。給定客戶的姓名、年齡、收入、地址以及期望的貸款金額,然后讓貸款分類器判斷是否批準貸款。為了驗證分類器能否達到服務商所聲稱的準確度(即泛化誤差低),銀行可以在一小組留出的驗證數據上測試分類器。對于銀行來說,這種檢查相對容易進行。因此表面上看,惡意的 Snoogle 很難在返回的分類器準確性上撒謊。
然而,盡管這個分類器可以很好地泛化數據分布,但這種隨機抽查將無法檢測出分布中罕見的特定輸入的不正確(或意外)行為。更糟糕的是,惡意的 Snoogle 可能使用某種「后門」機制顯式地設計返回的分類器,這樣一來,他們只要稍稍改動任意用戶的配置文件(將原輸入改為和后門匹配的輸入),就能讓分類器總是批準貸款。然后,Snoogle 可以非法出售一種「個人資料清洗(profile-cleaning)」服務,告訴客戶如何更改他們的個人資料才最有可能得到銀行放款。當然,銀行會想測試分類器遇到這種對抗性操作時的穩健性。但是這種穩健性測試和準確性測試一樣簡單嗎?
在這篇論文中,作者系統地探討了不可檢測的后門,即可以輕易改變分類器輸出,但用戶永遠也檢測不到的隱藏機制。他們給出了不可檢測性(undetectability)的明確定義,并在標準的加密假設下,證明了在各種環境中植入不可檢測的后門是可能的。這些通用結構在監督學習任務的外包中呈現出顯著的風險。
論文概覽
這篇論文主要展示了對抗者將如何在監督學習模型中植入后門。假設有個人想植入后門,他獲取了訓練數據并訓練了一個帶后門密鑰的后門分類器,使得:
- 給定后門密鑰,惡意實體可以獲取任何可能的輸入 x 和任何可能的輸出 y,并有效地產生非常接近 x 的新輸入 x’,使得在輸入 x’時,后門分類器輸出 y。
- 后門是不可檢測的,因為后門分類器要「看起來」像是客戶指定且經過認真訓練的。
作者給出了后門策略的多種結構,這些結構基于標準加密假設,能夠在很大程度上確保不被檢測到。文中提到的后門策略是通用且靈活的:其中一個可以在不訪問訓練數據集的情況下給任何給定的分類器 h 植入后門;其他的則運行誠實的訓練算法,但附帶精心設計的隨機性(作為訓練算法的初始化)。研究結果表明,給監督學習模型植入后門的能力是自然條件下所固有的。
論文的主要貢獻如下:
定義。作者首先提出了模型后門的定義以及幾種不可檢測性,包括:
- 黑盒不可檢測性,檢測器具有對后門模型的 oracle 訪問權;
- 白盒不可檢測性,檢測器接收模型的完整描述,以及后門的正交保證,作者稱之為不可復制性。
不可檢測的黑盒后門。作者展示了惡意學習者如何使用數字簽名方案 [GMR85] 將任何機器學習模型轉換為后門模型。然后,他(或他有后門密鑰的朋友)可以稍加改動任何輸入 x ∈ R^d,將其轉變成一個后門輸入 x’,對于這個輸入,模型的輸出與輸入為 x 時不同。對于沒有秘鑰的人來說,發現任意一個特殊的輸入 x(后門模型和原始模型在遇到這個輸入時會給出不同的結果)都是困難的,因為計算上并不可行。也就是說,后門模型其實和原始模型一樣通用。
不可檢測的白盒后門。對于遵循隨機特征學習范式的特定算法,作者展示了惡意學習者如何植入后門,即使給定對訓練模型描述(如架構、權重、訓練數據)的完全訪問,該后門也是不可檢測的。
具體來說,他們給出了兩種結構:一是在 Rahimi 和 Recht 的隨機傅里葉特征算法 [RR07] 中植入不可檢測的后門;二是在一種類似的單層隱藏層 ReLU 網絡結構中植入不可檢測的后門。
惡意學習者的力量來自于篡改學習算法使用的隨機性。研究者證明,即使在向客戶揭示隨機性和學習到的分類器之后,被植入這類后門的模型也將是白盒不可檢測的——在加密假設下,沒有有效的算法可以區分后門網絡和使用相同算法、相同訓練數據、「干凈」隨機 coin 構建的非后門網絡。
在格問題的最壞情況困難度下(對于隨機傅里葉特征的后門),或者在植入團問題的平均困難度下(對于 ReLU 后門),對手所使用的 coin 在計算上無法與隨機區分。這意味著后門檢測機制(如 [TLM18,HKSO21] 的譜方法)將無法檢測作者提到的后門(除非它們能夠在此過程中解決短格向量問題或植入團問題)。
該研究將此結果視為一個強大的概念驗證,證明我們可以在模型中插入完全檢測不到的白盒后門,即使對手被限制使用規定的訓練算法和數據,并且只能控制隨機性。這也引出了一些有趣的問題,比如我們是否有可能對其他流行的訓練算法植入后門。
總之,在標準加密假設下,檢測分類器中的后門是不可能的。這意味著,無論何時使用由不受信任方訓練的分類器,你都必須承擔與潛在植入后門相關的風險。
研究者注意到,機器學習和安全社區中有多項實驗研究 [GLDG19、CLL+17、ABC+18、TLM18、HKSO21、HCK21] 已經探索了機器學習模型后門問題。這些研究主要以簡單的方式探討后門的不可檢測性,但是缺乏正式定義和不可檢測性的證據。通過將不可檢測性的概念置于牢固的加密基礎上,該研究證明了后門風險的必然性,并探究了一些抵消后門影響的方法。
該研究的發現對于對抗樣本的穩健性研究也產生了影響。特別是,不可檢測后門的結構給分類器對抗穩健性的證明帶來很大的障礙。
具體來說,假設我們有一些理想的穩健訓練算法,保證返回的分類器 h 是完全穩健的,即沒有對抗樣本。該訓練算法存在不可檢測的后門意味著存在分類器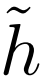 ,其中每個輸入都有一個對抗樣本,但沒有有效的算法可以將
,其中每個輸入都有一個對抗樣本,但沒有有效的算法可以將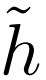 與穩健分類器 h 區分開來。這種推理不僅適用于現有的穩健學習算法,也適用于未來可能開發的任何穩健學習算法。
與穩健分類器 h 區分開來。這種推理不僅適用于現有的穩健學習算法,也適用于未來可能開發的任何穩健學習算法。
如果無法檢測到后門的存在,我們能否嘗試抵消掉后門的影響?
該研究分析了一些可以在訓練時、訓練后和評估前以及評估時應用的潛在方法,闡明了它們的優缺點。
可驗證的外包學習。在訓練算法標準化的環境中,用于驗證 ML 計算外包的形式化方法可用于在訓練時緩解后門問題 。在這樣的環境中,一個「誠實」的學習者可以讓一個有效的驗證器相信學習算法是正確執行的,而驗證器很可能會拒絕任何作弊學習者的分類器。不可檢測的后門的結構強度讓這種方法存在缺點。白盒結構只需要對初始隨機性進行后門處理,因此任何成功的可驗證外包策略都將涉及以下 3 種情況的任何一種:
- 驗證器向學習者提供隨機性作為「輸入」的一部分;
- 學習者以某種方式向驗證器證明隨機性被正確采樣;
- 讓隨機生成服務器的集合運行 coin 翻轉協議以生成真正的隨機性,注意并非所有服務器都是不誠實的。
一方面,證明者在這些外包方案中的工作遠不止運行誠實算法;但是,人們可能希望可驗證外包技術成熟到無縫完成的程度。更嚴重的問題是,該方法只能處理純計算外包場景,即服務提供商只是大量計算資源的提供者。對于那些提供 ML 專業知識的服務提供商,如何有效解決后門不可檢測問題依然是一個難題,也是未來的一個探索方向。
梯度下降的考驗。如果不驗證訓練過程,客戶可能會采用后處理策略來減輕后門的影響。例如,即使客戶想要外包學習(delegate learning),他們也可以在返回的分類器上運行幾次梯度下降迭代。直觀地講,即使無法檢測到后門,人們可能也希望梯度下降能破壞其功能。
此外,人們希望大幅減少迭代次數來消除后門。然而,該研究表明基于梯度的后處理效果可能是有限的。研究者將持久性(persistence)的概念引入梯度下降,即后門在基于梯度的更新下持續存在,并證明基于簽名方案的后門是持久的。了解不可檢測的白盒后門(特別是隨機傅里葉特征和 ReLU 的后門)可以在梯度下降中存在多久是未來一個有趣的研究方向。
隨機評估。最后,研究者提出了一種基于輸入的隨機平滑的時間評估抵消機制(evaluation-time neutralization mechanism)。具體來說,研究者分析了一種策略:在添加隨機噪聲后評估輸入上的(可能是后門的)分類器。其中關鍵的是,噪聲添加機制依賴于對后門擾動幅度的了解,即后門輸入與原始輸入的差異有多大,并在稍大半徑的輸入上隨機進行 convolving。
如果惡意學習者對噪聲的大小或類型有所了解,他就可以提前準備可以逃避防御的后門擾動(例如通過改變大小或稀疏度)。在極端情況下,攻擊者可能會隱藏一個需要大量噪聲才能進行抵消的后門,這可能會使返回的分類器無用,即使在「干凈」的輸入上也是如此。因此,這種抵消機制必須謹慎使用,不能起到絕對的防御作用。
總之,該研究表明存在完全無法檢測到的后門,研究者認為機器學習和安全研究社區進一步研究減輕其影響的原則方法至關重要。
更多細節請參考原論文。

?
 ?
?