













做 SQL 性能優(yōu)化真是讓人干瞪眼

很多大數(shù)據(jù)計(jì)算都是用 SQL 實(shí)現(xiàn)的,跑得慢時(shí)就要去優(yōu)化 SQL,但常常碰到讓人干瞪眼的情況。比如,存儲過程中有三條大概形如這樣的語句執(zhí)行得很慢:
select a,b,sum(x) from T group by a,b where …;
select c,d,max(y) from T group by c,d where …;
select a,c,avg(y),min(z) from T group by a,c where …;
這里的 T 是個(gè)有數(shù)億行的巨大表,要分別按三種方式分組,分組的結(jié)果集都不大。
分組運(yùn)算要遍歷數(shù)據(jù)表,這三句 SQL 就要把這個(gè)大表遍歷三次,對數(shù)億行數(shù)據(jù)遍歷一次的時(shí)間就不短,何況三遍。這種分組運(yùn)算中,相對于遍歷硬盤的時(shí)間,CPU 計(jì)算時(shí)間幾乎可以忽略。如果可以在一次遍歷中把多種分組匯總都計(jì)算出來,雖然 CPU 計(jì)算量并沒有變少,但能大幅減少硬盤讀取數(shù)據(jù)量,就能成倍提速了。如果 SQL 支持類似這樣的語法:
from T -- 數(shù)據(jù)來自 T 表
select a,b,sum(x) group by a,b where … -- 遍歷中的第一種分組
select c,d,max(y) group by c,d where … -- 遍歷中的第二種分組
select a,c,avg(y),min(z) group by a,c where …; -- 遍歷中的第三種分組
能一次返回多個(gè)結(jié)果集,那就可以大幅提高性能了。
可惜, SQL 沒有這種語法,寫不出這樣的語句,只能用個(gè)變通的辦法,就是用 group a,b,c,d 的寫法先算出更細(xì)致的分組結(jié)果集,但要先存成一個(gè)臨時(shí)表,才能進(jìn)一步用 SQL 計(jì)算出目標(biāo)結(jié)果。SQL 大致如下:
create table T_temp as select a,b,c,d,
sum(case when … then x else 0 end) sumx,
max(case when … then y else null end) maxy,
sum(case when … then y else 0 end) sumy,
count(case when … then 1 else null end) county,
min(case when … then z else null end) minz
group by a,b,c,d;
select a,b,sum(sumx) from T_temp group by a,b where …;
select c,d,max(maxy) from T_temp group by c,d where …;
select a,c,sum(sumy)/sum(county),min(minz) from T_temp group by a,c where …;
這樣只要遍歷一次了,但要把不同的 WHERE 條件轉(zhuǎn)到前面的 case when 里,代碼復(fù)雜很多,也會加大計(jì)算量。而且,計(jì)算臨時(shí)表時(shí)分組字段的個(gè)數(shù)變得很多,結(jié)果集就有可能很大,最后還對這個(gè)臨時(shí)表做多次遍歷,計(jì)算性能也快不了。大結(jié)果集分組計(jì)算還要硬盤緩存,本身性能也很差。
還可以用存儲過程的數(shù)據(jù)庫游標(biāo)把數(shù)據(jù)一條一條 fetch 出來計(jì)算,但這要全自己實(shí)現(xiàn)一遍 WHERE 和 GROUP 的動作了,寫起來太繁瑣不說,數(shù)據(jù)庫游標(biāo)遍歷數(shù)據(jù)的性能只會更差!只能干瞪眼!
TopN 運(yùn)算同樣會遇到這種無奈。舉個(gè)例子,用 Oracle 的 SQL 寫 top5 大致是這樣的:
select * from (select x from T order by x desc) where rownum<=5
表 T 有 10 億條數(shù)據(jù),從 SQL 語句來看,是將全部數(shù)據(jù)大排序后取出前 5 名,剩下的排序結(jié)果就沒用了!大排序成本很高,數(shù)據(jù)量很大內(nèi)存裝不下,會出現(xiàn)多次硬盤數(shù)據(jù)倒換,計(jì)算性能會非常差!
避免大排序并不難,在內(nèi)存中保持一個(gè) 5 條記錄的小集合,遍歷數(shù)據(jù)時(shí),將已經(jīng)計(jì)算過的數(shù)據(jù)前 5 名保存在這個(gè)小集合中,取到的新數(shù)據(jù)如果比當(dāng)前的第 5 名大,則插入進(jìn)去并丟掉現(xiàn)在的第 5 名,如果比當(dāng)前的第 5 名要小,則不做動作。這樣做,只要對 10 億條數(shù)據(jù)遍歷一次即可,而且內(nèi)存占用很小,運(yùn)算性能會大幅提升。這種算法本質(zhì)上是把 TopN 也看作與求和、計(jì)數(shù)一樣的聚合運(yùn)算了,只不過返回的是集合而不是單值。SQL 要是能寫成這樣:select top(x,5) from T 就能避免大排序了。然而非常遺憾,SQL 沒有顯式的集合數(shù)據(jù)類型,聚合函數(shù)只能返回單值,寫不出這種語句!
不過好在全集的 TopN 比較簡單,雖然 SQL 寫成那樣,數(shù)據(jù)庫卻通常會在工程上做優(yōu)化,采用上述方法而避免大排序。所以 Oracle 算那條 SQL 并不慢。但是,如果 TopN 的情況復(fù)雜了,用到子查詢中或者和 JOIN 混到一起的時(shí)候,優(yōu)化引擎通常就不管用了。比如要在分組后計(jì)算每組的 TopN,用 SQL 寫出來都有點(diǎn)困難。Oracle 的 SQL 寫出來是這樣:
select * from
(select y,x,row_number() over (partition by y order by x desc) rn from T)
where rn<=5
這時(shí)候,數(shù)據(jù)庫的優(yōu)化引擎就暈了,不會再采用上面說的把 TopN 理解成聚合運(yùn)算的辦法。只能去做排序了,結(jié)果運(yùn)算速度陡降!
假如 SQL 的分組 TopN 能這樣寫:
select y,top(x,5) from T group by y
把 top 看成和 sum 一樣的聚合函數(shù),這不僅更易讀,而且也很容易高速運(yùn)算。可惜,不行。還是干瞪眼!
關(guān)聯(lián)計(jì)算也是很常見的情況。以訂單和多個(gè)表關(guān)聯(lián)后做過濾計(jì)算為例,SQL 大體是這個(gè)樣子:
select o.oid,o.orderdate,o.amount
from orders o
left join city ci on o.cityid = ci.cityid
left join shipper sh on o.shid=sh.shid
left join employee e on o.eid=e.eid
left join supplier su on o.suid=su.suid
where ci.state='New York'
and e.title = 'manager'
and
訂單表有幾千萬數(shù)據(jù),城市、運(yùn)貨商、雇員、供應(yīng)商等表數(shù)據(jù)量都不大。過濾條件字段可能會來自于這些表,而且是前端傳參數(shù)到后臺的,會動態(tài)變化。
SQL 一般采用 HASH JOIN 算法實(shí)現(xiàn)這些關(guān)聯(lián),要計(jì)算 HASH 值并做比較。每次只能解析一個(gè) JOIN,有 N 個(gè) JOIN 要執(zhí)行 N 遍動作,每次關(guān)聯(lián)后都需要保持中間結(jié)果供下一輪使用,計(jì)算過程復(fù)雜,數(shù)據(jù)也會被遍歷多次,計(jì)算性能不好。
通常,這些關(guān)聯(lián)的代碼表都很小,可以先讀入內(nèi)存。如果將訂單表中的各個(gè)關(guān)聯(lián)字段預(yù)先做序號化處理,比如將雇員編號字段值轉(zhuǎn)換為對應(yīng)雇員表記錄的序號。那么計(jì)算時(shí),就可以用雇員編號字段值(也就是雇員表序號),直接取內(nèi)存中雇員表對應(yīng)位置的記錄,性能比 HASH JOIN 快很多,而且只需將訂單表遍歷一次即可,速度提升會非常明顯!也就是能把 SQL 寫成下面的樣子:
select o.oid,o.orderdate,o.amount
from orders o
left join city c on o.cid = c.# -- 訂單表的城市編號通過序號 #關(guān)聯(lián)城市表
left join shipper sh on o.shid=sh.# -- 訂單表運(yùn)貨商號通過序號 #關(guān)聯(lián)運(yùn)貨商表
left join employee e on o.eid=e.# -- 訂單表的雇員編號通過序號 #關(guān)聯(lián)雇員表
left join supplier su on o.suid=su.# -- 訂單表供應(yīng)商號通過序號 #關(guān)聯(lián)供應(yīng)商表
where ci.state='New York'
and e.title = 'manager'
and
可惜的是,SQL 使用了無序集合概念,即使這些編號已經(jīng)序號化了,數(shù)據(jù)庫也無法利用這個(gè)特點(diǎn),不能在對應(yīng)的關(guān)聯(lián)表這些無序集合上使用序號快速定位的機(jī)制,只能使用索引查找,而且數(shù)據(jù)庫并不知道編號被序號化了,仍然會去計(jì)算 HASH 值和比對,性能還是很差!
有好辦法也實(shí)施不了,只能再次干瞪眼!
還有高并發(fā)帳戶查詢,這個(gè)運(yùn)算倒是很簡單:
select id,amt,tdate,… from T
where id='10100'
and tdate>= to_date('2021-01-10', 'yyyy-MM-dd')
and tdate<to_date('2021-01-25', 'yyyy-MM-dd')
and …
在 T 表的幾億條歷史數(shù)據(jù)中,快速找到某個(gè)帳戶的幾條到幾千條明細(xì),SQL 寫出來并不復(fù)雜,難點(diǎn)是大并發(fā)時(shí)響應(yīng)速度要達(dá)到秒級甚至更快。為了提高查詢響應(yīng)速度,一般都會對 T 表的 id 字段建索引:
create index index_T_1 on T(id)
在數(shù)據(jù)庫中,用索引查找單個(gè)帳戶的速度很快,但并發(fā)很多時(shí)就會明顯變慢。原因還是上面提到的 SQL 無序理論基礎(chǔ),總數(shù)據(jù)量很大,無法全讀入內(nèi)存,而數(shù)據(jù)庫不能保證同一帳戶的數(shù)據(jù)在物理上是連續(xù)存放的。硬盤有最小讀取單位,在讀不連續(xù)數(shù)據(jù)時(shí),會取出很多無關(guān)內(nèi)容,查詢就會變慢。高并發(fā)訪問的每個(gè)查詢都慢一點(diǎn),總體性能就會很差了。在非常重視體驗(yàn)的當(dāng)下,誰敢讓用戶等待十秒以上?!
容易想到的辦法是,把幾億數(shù)據(jù)預(yù)先按照帳戶排序,保證同一帳戶的數(shù)據(jù)連續(xù)存儲,查詢時(shí)從硬盤上讀出的數(shù)據(jù)塊幾乎都是目標(biāo)值,性能就會得到大幅提升。但是,采用 SQL 體系的關(guān)系數(shù)據(jù)庫并沒有這個(gè)意識,不會強(qiáng)制保證數(shù)據(jù)存儲的物理次序!這個(gè)問題不是 SQL 語法造成的,但也和 SQL 的理論基礎(chǔ)相關(guān),在關(guān)系數(shù)據(jù)庫中還是沒法實(shí)現(xiàn)這些算法。
那咋辦?只能干瞪眼嗎?不能再用 SQL 和關(guān)系數(shù)據(jù)庫了,要使用別的計(jì)算引擎。開源的集算器 SPL 基于創(chuàng)新的理論基礎(chǔ),支持更多的數(shù)據(jù)類型和運(yùn)算,能夠描述上述場景中的新算法。用簡單便捷的 SPL 寫代碼,在短時(shí)間內(nèi)能大幅提高計(jì)算性能!
上面這些問題用 SPL 寫出來的代碼樣例如下:
一次遍歷計(jì)算多種分組

用聚合的方式計(jì)算 Top5
全集 Top5(多線程并行計(jì)算):

分組 Top5(多線程并行計(jì)算):

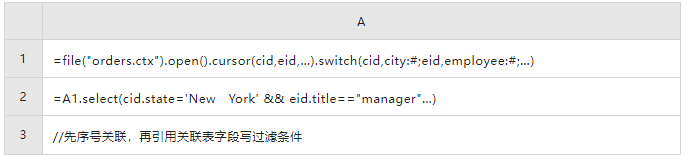
用序號做關(guān)聯(lián)的 SPL 代碼
系統(tǒng)初始化:

查詢:
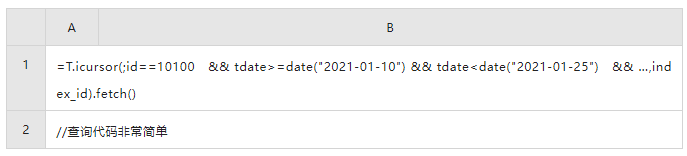
高并發(fā)帳戶查詢的 SPL 代碼
數(shù)據(jù)預(yù)處理,有序存儲:

帳戶查詢:
除了這些簡單例子,SPL 還能實(shí)現(xiàn)更多高性能算法,比如有序歸并實(shí)現(xiàn)訂單和明細(xì)之間的關(guān)聯(lián)、預(yù)關(guān)聯(lián)技術(shù)實(shí)現(xiàn)多維分析中的多層維表關(guān)聯(lián)、位存儲技術(shù)實(shí)現(xiàn)上千個(gè)標(biāo)簽統(tǒng)計(jì)、布爾集合技術(shù)實(shí)現(xiàn)多個(gè)枚舉值過濾條件的查詢提速、時(shí)序分組技術(shù)實(shí)現(xiàn)復(fù)雜的漏斗分析等等。

















