













計算機大佬讓你徹底了解"深入理解計算機系統"
前言
當我們點擊Xcode的運行按鈕時,你會注意到在界面頂端的提示欄上會出現“Building”的字樣,緊接著會出現“Linking”的字樣,我們知道Building是編譯過程,那這個Linking(鏈接)是什么過程呢?本文將對鏈接過程做一個講解,了解鏈接的過程,可以幫助你理解計算機系統的底層原理,并解答你平時關于計算機怎樣識別并執行程序的一些疑惑。另外,本文也是后續篇章的基礎,我們會由鏈接的知識延展出Mach-O文件、fishhook原理以及hook objc_msgSend的知識講解。
鏈接的基本概念
鏈接(linking)是將各種代碼和數據片段收集并組合成為一個單一文件的過程,這個文件可被加載(復制)到內存并執行。
鏈接可以執行與編譯時(complie time),也就是源代碼被翻譯成機器代碼時;也可以執行于加載時(load time),也就是在程序被加載器(load-er)加載到內存并執行時;甚至可以執行在運行時(run time),也就是由應用程序來執行。在早期的計算機系統中,鏈接是手動執行的。在現代系統中,鏈接是由叫做連接器(linker)的程序自動執行的。
鏈接的作用
鏈接器使分離編譯成為可能,我們不用將一個大型的應用程序組織為一個巨大的源文件,而是可以把它分解為更小、更好管理的模塊,可以獨立地修改和編譯這些模塊。當我們改變這些模塊中的一個時,只需簡單地重新編譯它,并重新鏈接應用,而不必重新編譯其它文件。
下面的討論基于這樣的環境:一個運行Linux的x86-64系統,使用標準的ELF-64目標文件格式。
編譯器驅動程序
下面的C語言示例程序,由兩個源文件組成,main.c和sum.c。main函數初始化一個整數數組,然后調用sum函數來對數組元素求和。
// sum.c
int sum(int *a, int n) {
int s = 0;
for (int i = 0; i < n; i++) {
s += a[i];
}
return s;
}
// main.c
int array[2] = {1, 2};
int main() {
int val = sum(array, 2);
return val;
}
大多數的編譯系統會提供編譯器驅動程序(compile driver),包含語言預處理器、編譯器、匯編器和鏈接器。首先編譯器驅動程序會對main.c與sum.c文件的源代碼進行翻譯,翻譯過程如下:

其中,main.o稱為可重定位目標文件。
之后,編譯系統會運行鏈接器ld,將main.o和sum.o以及一些必要的系統目標文件組合起來,創建一個可以執行目標文件,這個過程是靜態鏈接,過程如下:

再之后,操作系統會調用加載器(loader),將可執行文件prog中的代碼和數據復制到內存中,然后執行。
靜態鏈接
靜態鏈接器(static linker)以一組可重定位目標文件作為輸入,生成一個完全鏈接的、可以加載和運行的可執行目標文件。輸入的可重定位目標文件由各種不同的代碼和數據節(section)組成,每一節都是一個連續的字節序列。指令在一節中,初始化了的全局變量在另一個節中,而未初始化的變量又在另外一節中。
為了構造可執行文件,鏈接器必須完成兩個重要的任務:
- 符號解析(symbol resolution)。目標文件定義和引用符號,一個個符號對應一個函數或一個全局變量或一個靜態變量(即C語言中以static屬性聲明的變量)。符號解析的目的是將每個符號引用正好和一個符號定義關聯起來。
- 重定位(relocation)。編譯器和匯編器生成從地址0開始的代碼和數據節。鏈接器通過把每個符號定義與一個內存位置關聯起來,從而重定位這些節,然后修改所有對這些符號的引用,使它們指向這個內存位置。
目標文件純粹是字節塊的集合,這些塊中,有些包含程序代碼,有些包含數據,而有些則是引導鏈接器和加載器的數據結構。鏈接器將這些塊連接起來,確定被連接塊的運行時位置,并且修改代碼和數據塊中的各種位置。
目標文件
目標文件有三種形式:
- 可重定位目標文件。包含二進制代碼和數據,其形式可以在編譯時與其他可重定位目標文件合并起來,創建一個可執行目標文件。
- 可執行目標文件。包含二進制代碼和數據,其形式可以被直接復制到內存并執行。
- 共享目標文件。一種特殊類型的可重定位目標文件,可以在加載或者運行時被動態的加載進內存并鏈接。動態庫就是這種形式的。
目標文件的生成方式:
- 編譯器和匯編器生成可重定位目標文件(包括共享目標文件)。
- 鏈接器生成可執行目標文件。
目標文件的格式:
- 在iOS和MacOS-X中,目標文件的格式是Mach-O格式。
- X86-64 Linux和Unix系統使用可執行可連接格式ELF。
可重定位目標文件
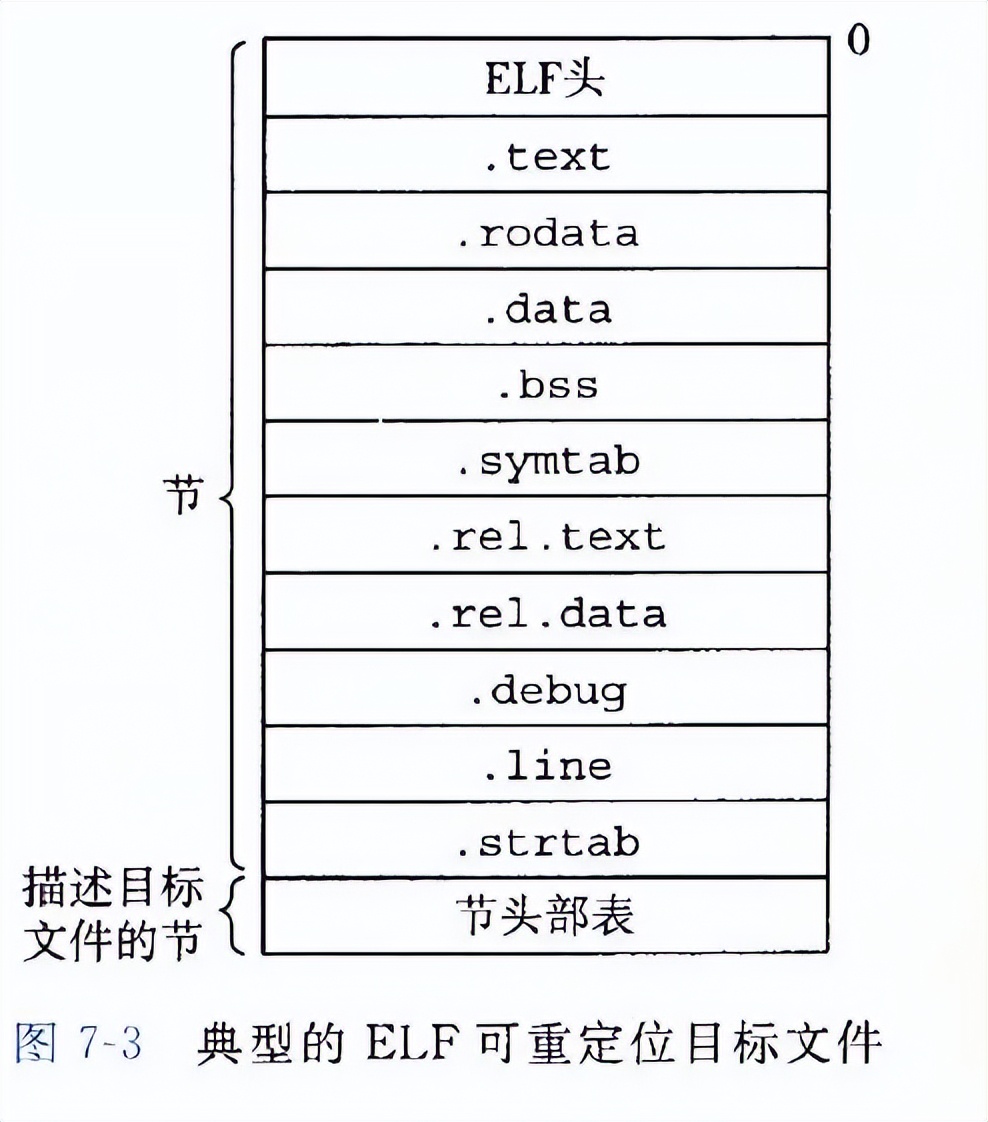
下上展示了一個典型的ELF可重定位目標文件的格式。ELF頭包含很多信息,包括生成該文件的系統的字節大小,字節順序,ELF頭的大小,目標文件的類型,機器類型等等。節頭部表描述了不同節的位置和大小。
加載ELF頭和節頭部表的是節:
- .text:已編譯程序的機器代碼。
- .rodata:只讀數據,比如 printf語句中的格式串和開關語句的跳轉表。
- .data:已初始化的全局和靜態C變量。局部C變量在運行時被保存在棧中,既不出現在,data節中,也不出現在.bss節中
- .bss:未初始化的全局和靜態C變量,以及所有被初始化為0的全局或靜態變量。在目標文件中這個節不占據實際的空間,它僅僅是一個占位符。目標文件格式區分已初始化和未初始化變量是為了空間效率:在目標文件中,未初始化變量不需要占據任何實際的磁盤空間。運行時,在內存中分配這些變量,初始值為0。
- .symtab:一個符號表,它存放在程序中定義和引用的函數和全局變量的信息。一些程序員錯誤地認為必須通過-g選項來編譯一個程序,才能得到符號表信息。實際上,每個可重定位目標文件在. symtab中都有一張符號表(除非程序員特意用 STRIP命令去掉它)。然而,和編譯器中的符號表不同, symtab符號表不包含局部變量的條目。
- .rel.text:一個.text節中位置的列表,當鏈接器把這個目標文件和其他文件組合時,需要修改這些位置。一般而言,任何調用外部函數或者引用全局變量的指令都需要修改。另一方面,調用本地函數的指令則不需要修改。注意,可執行目標文件中并不需要重定位信息,因此通常省略,除非用戶顯式地指示鏈接器包含這些信息。
- .rel.data:被模塊引用或定義的所有全局變量的重定位信息。一般而言,任何已初始化的全局變量,如果它的初始值是一個全局變量地址或者外部定義函數的地址,都需要被修改。
- .debug:一個調試符號表,其條目是程序中定義的局部變量和類型定義,程序中定義和引用的全局變量,以及原始的C源文件。只有以-g選項調用編譯器驅動程序時,才會得到這張表。
- .line:原始C源程序中的行號和.text節中機器指令之間的映射。只有以-g選項調用編譯器驅動程序時,才會得到這張表。
- .strtab:一個字符串表,其內容包括. symtab和, debug節中的符號表,以及節頭部中的節名字。字符串表就是以nu11結尾的字符串的序列。
符號和符號表
每個可重定位目標模塊(目標文件)m都有一個符號表,它包含m定義和引用的符號的信息。在鏈接器的上下文中,有三種不同的符號:
- 由模塊m定義并能被其它模塊引用的全局符號。這些符號對應于非靜態的C函數和全局變量。
- 由其它模塊定義并被模塊m引用的全局符號。這些符號稱為外部符號,對應于在其它模塊中定義的非靜態C函數和全局變量。
- 只被模塊m定義和引用的局部符號。它們對應于帶static屬性的C函數和全局變量。這些符號在模塊m中任何位置都可見,但是不能被其它模塊引用。
.symtab中的符號表不包含非靜態程序變量的任何符號,這些程序變量符號在棧中被管理,鏈接器對此類符號不感興趣。
如何解析多重定義的全局符號
鏈接器的輸入是一組可重定位目標模塊。每個模塊定義一組符號,有些是局部的(只對定義該符號的模塊可見),有些是全局的(對其他模塊也可見)。如果多個模塊定義同名的全局符號,會發生什么呢?下面是 Linux編譯系統采用的方法。
在編譯時,編譯器向匯編器輸出每個全局符號,或者是強( strong)或者是弱(weak),而匯編器把這個信息隱含地編碼在可重定位目標文件的符號表里。函數和已初始化的全局變量是強符號,未初始化的全局變量是弱符號。
根據強弱符號的定義,Linux鏈接器使用下面的規則來處理多重定義的符號名
- 規則1:不允許有多個同名的強符號。
- 規則2:如果有一個強符號和多個弱符號同名,那么選擇強符號。
- 規則3:如果有多個弱符號同名,那么從這些弱符號中任意選擇一個。
靜態庫
迄今為止,我們都是假設鏈接器讀取一組可重定位目標文件,并把它們鏈接起來,輸出一個可執行目標文件。實際上,所有的編譯系統都提供一種機制,將所有相關的目標模塊打包成一個單獨的文件,稱為靜態庫。靜態庫可以用做鏈接器的輸入,當鏈接器構造一個輸出的可執行目標文件時,它只復制靜態庫里被應用程序引用的目標模塊,這就減少了可執行文件在磁盤和內存中的大小。在Linux系統中,靜態庫由后綴.a標識。
重定位
一旦鏈接器完成了符號解析這一步,就把代碼中的每個符號引用和正好一個符號定義(即它的一個輸入目標模塊中的一個符號表條目)關聯起來。此時,鏈接器就知道它的輸入目標模塊中的代碼節和數據節的確切大小。現在就可以開始重定位步驟了,在這個步驟中,將合并輸入模塊,并為每個符號分配運行時地址。重定位由兩步組成:
- 重定位節和符號定義。在這一步中,鏈接器將所有相同類型的節合并為同一類型的新的聚合節。例如,來自所有輸入模塊的.data節被全部合并成一個節,這個節成為輸出的可執行目標文件的.data節。然后,鏈接器將運行時內存地址賦給新的聚合節,賦給輸人模塊定義的每個節,以及賦給輸人模塊定義的每個符號。當這一步完成時,程序中的每條指令和全局變量都有唯一的運行時內存地址了。
- 重定位節中的符號引用。在這一步中,鏈接器修改代碼節和數據節中對每個符號的引用,使得它們指向正確的運行時地址。要執行這一步,鏈接器依賴于可重定位目標模塊中稱為重定位條目(relocation entry)的數據結構。
當匯編器生成一個目標模塊時,它并不知道數據和代碼最終將放在內存中的什么位置,它也并不知道這個模塊引用的任何外部定義的函數或者全局變量的位置。所以,無論何時匯編器遇到對最終位置的目標引用,它就會生成一個重定位條目,告訴鏈接器在將目標文件合并成可執行目標文件時如何修改這個引用。
可執行目標文件 與 加載可執行目標文件
見《深入理解計算機系統》
動態鏈接共享庫
靜態庫由一些缺點:靜態庫需要定期維護和更新;每個程序都會使用一些通用的標準函數,在運行時,這些函數的代碼會被復制到每個運行進程的文本段中,在一個運行上百個進行的典型系統上,這是對內存資源的浪費。
共享庫(shared library)是致力于解決靜態庫缺陷的一個現代創新產物。共享庫是一個目標模塊,在運行或加載時,可以加載到任意內存地址,并和一個在內存中的程序鏈接起來。這個過程稱為動態鏈接,是由一個叫做動態鏈接器(dynamic linker)的程序來執行的。在Linux系統中,共享庫通常由.so后綴標識。
共享庫以兩種不同的方式來共享的。首先,在任何給定的文件系統中,對于一個庫只有一個.so文件。所有引用該哭的可執行目標文件共享這個.so文件中的代碼和數據,而不是像靜態庫的內容那樣被復制和嵌入到引用它們的可執行文件中。其次,在內存中,一個共享庫的.text節的一個副本可以被不同的正在運行的進程共享。















