如何判斷某網頁的 URL 是否存在于包含 100 億條數據的黑名單上
題目描述
現在想要實現一個網頁過濾系統,利用該系統可以根據網頁的 URL 判斷該網頁是否在黑名單上,黑名單現在已經包含 100 億個不安全網頁的 URL,每個網頁的 URL 最多占用 64B(字節) 大小。
請設計該系統, 要求:
- 該系統允許有萬分之一以下的判斷失誤率
- 使用的額外空間不要超過 30GB
解題思路
最簡單的想法,把黑名單中所有的 URL 通過數據庫或哈希表保存下來,然后遍歷一遍就能判重。
But,每個 URL 有 64 B(字節),黑名單中有 100 億條 URL,那想要用數據庫或者哈希表把這些數據全部存儲起來,至少需要 640GB 的空間,顯然不滿足要求 2(使用的額外空間不要超過 30GB)。
事實上,這個題目有一個很明顯的提示,那就是允許失誤率!
類似的這種 網頁黑名單系統、垃圾郵件過濾系統、爬蟲的網址判重系統 等題目,一般都是允許一定的失誤率的,但是對空間要求比較嚴格。
啥也別說第一個就應該想到布隆過濾器。
簡單介紹下布隆過濾器的基本構造,其實就是一個 BitMap(更簡單點來說其實就是一個數組),BitMap 中每個位上的元素由若干個哈希函數進行賦值。布隆過濾器的優勢在于使用很少的空間就可以將準確率做到很高的程度(但想做到完全正確是不可能的)。
哈希函數(散列函數)就不用多少了,主要有以下節點特性:
- 哈希函數一般都可以輸入任意數值,也就是有無限的輸入值域。
- 當給哈希函數傳入相同的輸入值時,返回值一樣。
- 當給哈希函數傳入不同的輸入值時,由于哈希沖突的存在,所以返回值可能一樣,也可能不一樣。
- 不同的輸入值所得到的返回值會均勻地分布。
顯然,返回值分布越均勻,哈希函數就越優秀。有興趣的小伙伴可以了解哈希函數的一些經典實現,比如 MD5 和 SHA1算法,這里就不詳細介紹了。
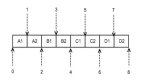
再來看布隆過濾器。假設有一個長度為 m 的 bit(位) 類型的數組(也就是 BitMap 位圖,上篇文章介紹過的),即數組中的每一個位置只占一個 bit(每一個 bit 只有 0 和 1 兩種狀態):
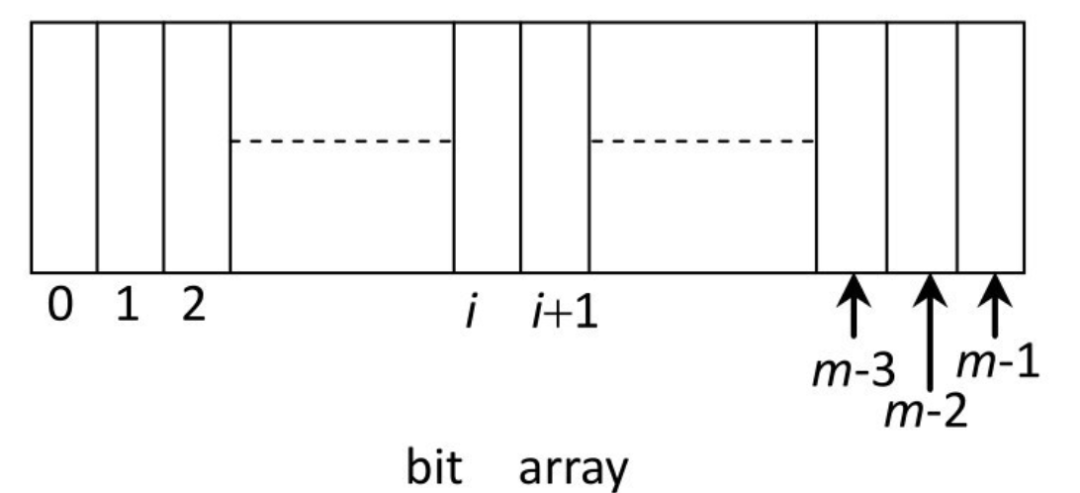
再假設一共有 k 個不同的哈希函數,它們的輸出域都 >= m。
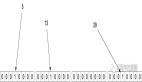
那么對同一個輸入對象(假設是一個 URL,字符串),經過 k 個哈希函數算出來的結果也是不一樣的(當然也有可能相同)。對算出來的每一個結果都對 m 取余(%m),然后在 BitMap 上把相應的位置設置為 1(涂黑):
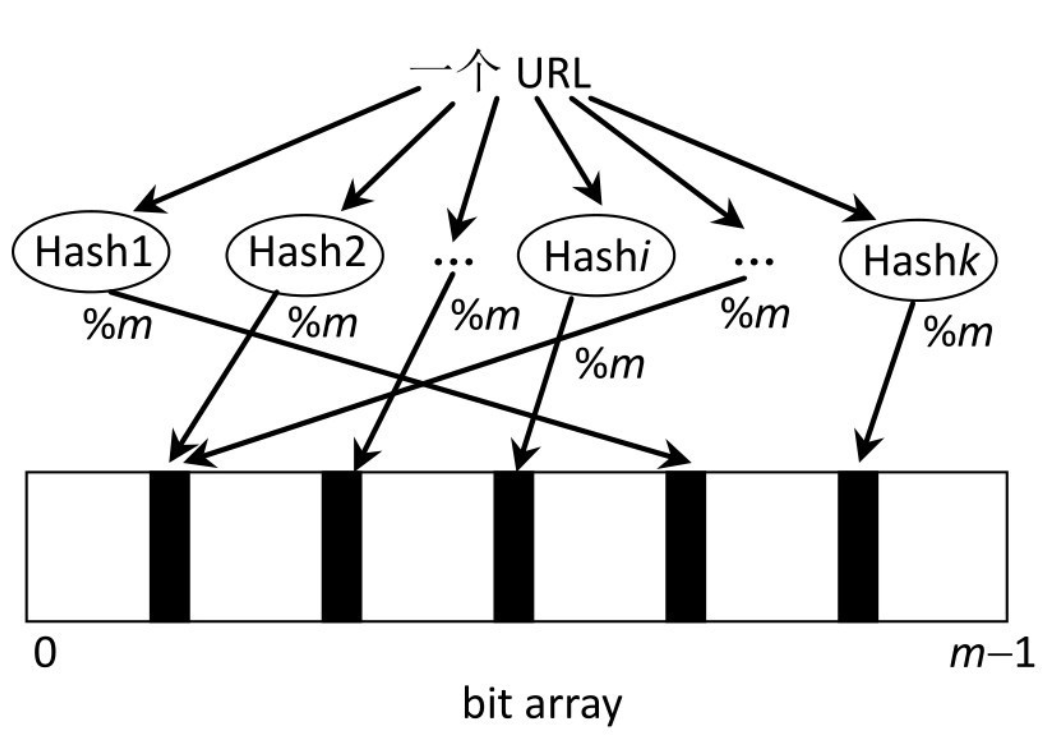
按照上述方法,我們處理所有的輸入對象(黑名單中 200 億條 URL),每個對象都可能把 BitMap 中的一些白位置涂黑(0 的位置為 1)。
這樣,存儲了黑名單中 200 億條 URL 的布隆過濾器就構造完成了。
那么假設這時又來了一個新值,如何判斷這個新值之前是否已經存在呢?(如何判斷某個網頁的 URL 是否在黑名單上呢?)
記這個網頁的 URL 為 input,想檢查它是否是存在于黑名單(BitMap)中,就把 input 通過同樣的 k 個哈希函數,得到 k 個值,然后繼續同樣地把 k 個值取余(%m),就得到在 [0, m-1] 范圍上的 k 個值,接下來在 BitMap 上看這些位置是不是都為黑:
- 如果有一個不為黑,說明 input 一定不在這個 BitMap 里。
- 如果都為黑,說明 a 可能在這個 BitMap 里,也就是說存在誤判的可能性。
解釋具體一點,如果 input 的確是之前已經處理過的 URL,那么在生成布隆過濾器時,BitMap 中相應的 k 個位置一定已經涂黑了,所以在檢查階段,input 執行一遍相同的操作,肯定不會產生誤判的。
會產生誤判的是,input 明明不是之前已經處理過的輸入對象,但由于哈希沖突的存在,可能就那么巧,兩個不同的輸入得到的 k 個哈希輸出都是一樣的(當然概率會非常小),那么在檢查 input 時,可能 input 對應的 k 個位置都是黑的,從而錯誤地認為 input 是輸入對象。
所以用布隆過濾器設計的系統,總結來說就是:黑名單中存在的 URL,一定能夠檢查出來,黑名單中不存在的 URL,有比較小的可能性被誤判。
對于這種誤判,其實也有解決方案,那就是白名單,對已經發現的誤報數據我們可以通過建立白名單來防止再次誤報。
比如,已經發現 www.baidu.com 這個樣本不在布隆過濾器(黑名單)中,但是每次計算后的結果都顯示其在布隆過濾器中,那么就可以把這個樣本加入白名單中,以后這個樣本再次輸入的時候,就不會進入布隆過濾器的邏輯進行判斷了。
手寫布隆過濾器
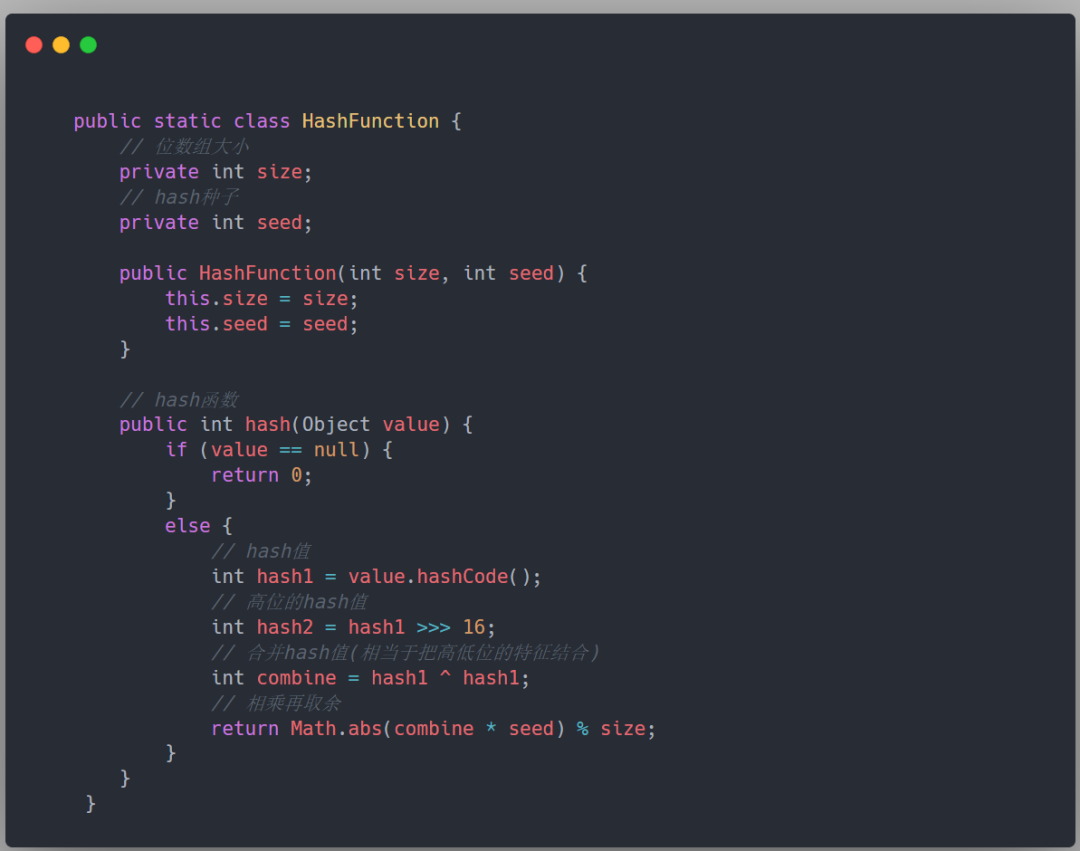
下面來用 Java 實現一個布隆過濾器,參考這篇文章:https://cloud.tencent.com/developer/article/1823271。
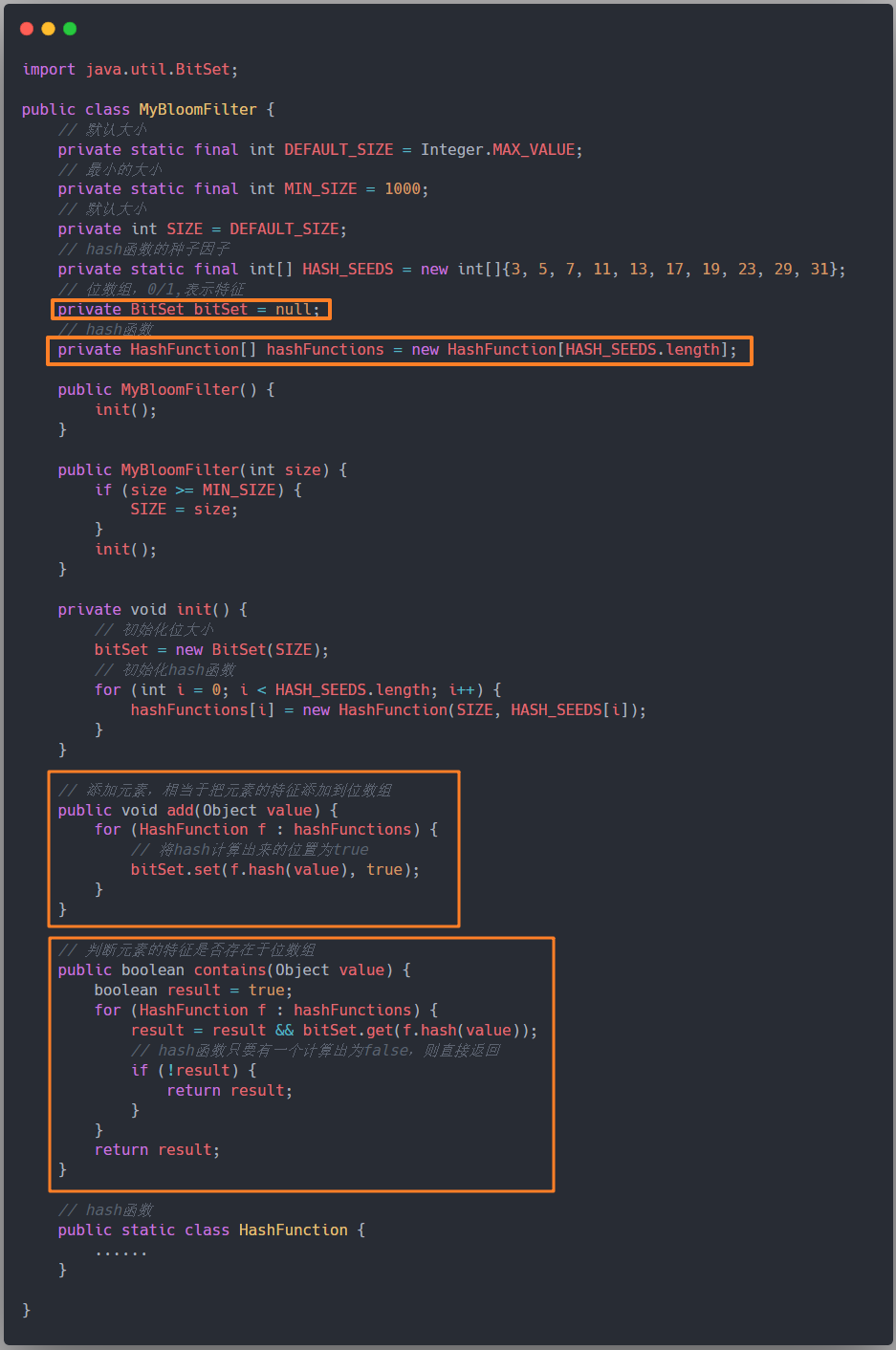
首先我們當然需要一個位數組,Java 提供了一個封裝好的位數組 BitSet。
除此之外,寫一個簡單的布隆過濾器需要考慮的點有這些:
- 位數組的大小空間,需要指定,其他相同的時候,位數組的大小越大,hash 沖突的可能性越小。
- 多個 hash 函數,為了避免沖突,我們可以使用多個不同的質數來當種子。
- 應該對外提供的方法:主要有兩個,一個往布隆過濾器里面添加元素,另一個是判斷布隆過濾器是否包含某個元素。
重點在下圖框出來了:
Hash 函數的實現這里就不多做研究了,給出一個比較簡單的版本,主要是將 hashCode() 值的高位和低位進行異或,然后乘以預設定的種子(seed),再對 BitMap 數組的大小進行取余數: