算法題實(shí)戰(zhàn) — 大規(guī)模黑名單ip匹配
算法是許多IT公司面試時(shí)很重要的一個(gè)環(huán)節(jié),但也有很多人抱怨實(shí)際工作中很少碰到,實(shí)用性不高。本文描述了我們公司在面試時(shí)常用的一道題目,雖然底層用了非常簡(jiǎn)單的算法,但卻是具體工作中比較容易見(jiàn)到的場(chǎng)景:大規(guī)模黑名單 ip 匹配。同時(shí)用我們?cè)诎踩W(wǎng)關(guān)中開(kāi)發(fā)的例子來(lái)做些驗(yàn)證。
問(wèn)題和場(chǎng)景
問(wèn)題:
有海量的 ip 網(wǎng)段名單,需要快速的驗(yàn)證某一個(gè) ip 是否屬于其中任意一個(gè)網(wǎng)段。
這其實(shí)是一個(gè)比較普遍的問(wèn)題,以我們的安全網(wǎng)關(guān)為例,至少在以下場(chǎng)景中有需要:
場(chǎng)景一: 單純的黑白名單匹配
對(duì)于網(wǎng)關(guān)來(lái)說(shuō),黑白名單匹配是基本功能:
- 內(nèi)部 ip 需要白名單 bypass。按照公司的規(guī)模和地域所在,這里可能會(huì)有大量的白名單。
- 攻擊 ip 需要黑名單 block。目前的互聯(lián)網(wǎng),各種掃描和攻擊還是比較猖獗的,可以很容易的獲得大量黑名單 ip,需要進(jìn)行實(shí)時(shí)封禁。
- 類(lèi)似的可以參考 nginx 的黑名單功能,通過(guò) deny 語(yǔ)句 "deny 192.168.1.0/24;" 可以定義一批 ip 網(wǎng)段,用來(lái)做訪(fǎng)問(wèn)控制。
場(chǎng)景二: 真實(shí)ip獲取
真實(shí) ip 獲取對(duì)有些網(wǎng)站來(lái)說(shuō)其實(shí)是一個(gè)比較麻煩的問(wèn)題,因?yàn)榱髁靠赡苡胁煌膩?lái)源路徑:
- 瀏覽器-->網(wǎng)關(guān)。這種直接取 remote_address, 即 tcp 的遠(yuǎn)端地址;
- 瀏覽器-->lb-->網(wǎng)關(guān)。中間可能有別的負(fù)載均衡,一般靠 XFF 頭來(lái)識(shí)別;
- 瀏覽器-->cdn-->lb-->網(wǎng)關(guān)。有些流量走了 cdn 或者云 waf,需要對(duì) XFF 頭特別處理,識(shí)別出 cdn 的 ip;
- 瀏覽器-->cdn-->lb-->...-->lb-->網(wǎng)關(guān)。實(shí)際場(chǎng)景中,受到重定向,內(nèi)部多層網(wǎng)關(guān)的影響,可能會(huì)有比較復(fù)雜的場(chǎng)景。
類(lèi)似的可以參考 nginx 的真實(shí) ip 功能, 原理也比較簡(jiǎn)單,通過(guò)類(lèi)似 "set_real_ip_from 192.168.1.0/24;" 的語(yǔ)句可以設(shè)置內(nèi)部 ip 名單,這樣在處理 XFF 頭的時(shí)候,從后往前找,遞歸模式下尋找第一個(gè)不是內(nèi)部 ip 的值,即真實(shí) ip。這就回歸到本文的問(wèn)題上來(lái)。
場(chǎng)景三: 流量標(biāo)注
這部分功能常由后端的業(yè)務(wù)模塊自行實(shí)現(xiàn),我們?cè)陂_(kāi)發(fā)產(chǎn)品中希望能在請(qǐng)求進(jìn)來(lái)的時(shí)候做一些自動(dòng)標(biāo)注,減輕后端的負(fù)擔(dān),比較有用的如:
- ip 歸屬地判斷。ip 歸屬地一般是由數(shù)十萬(wàn)網(wǎng)段組成的索引,需要進(jìn)行快速判斷;
- 基站標(biāo)注。目前大量使用 4g 上網(wǎng),所以基站 ip 必須小心對(duì)待,而基站數(shù)據(jù)也是大量的 ip 網(wǎng)段;
- 云服務(wù)器標(biāo)注。目前較多的攻擊來(lái)自于云服務(wù)器,這些標(biāo)注對(duì)后臺(tái)的安全和風(fēng)控業(yè)務(wù)有協(xié)助。云服務(wù)器列表也通過(guò)海量 ip 網(wǎng)段列表來(lái)展現(xiàn)。
以上場(chǎng)景描述了海量 ip 網(wǎng)段列表匹配的一些應(yīng)用場(chǎng)景,還是比較容易碰到的。
二、算法描述
算法一: hashmap
絕大部分人第一反應(yīng)是通過(guò) hashmap 來(lái)做匹配,理論上可以實(shí)現(xiàn)(將網(wǎng)段拆分為獨(dú)立的 ip),但基本不可用:
- 網(wǎng)段的掩碼不一定是24位,可以是32內(nèi)的任一數(shù)字,所以如果要保證普遍性的話(huà),需要完全拆成獨(dú)立的 ip;
- 哪怕是真實(shí) ip 獲取這樣常見(jiàn)的場(chǎng)景,我們?cè)诳蛻?hù)這邊碰到,由于使用了多家 cdn 廠(chǎng)家,cdn 網(wǎng)段有1300+,假設(shè)都為24位掩碼的 c 類(lèi)地址,也會(huì)有332800+的 ip,做成 hashmap 將是大量的內(nèi)存開(kāi)銷(xiāo);
- 由于網(wǎng)關(guān)一般是通過(guò)多進(jìn)程或者多實(shí)例做水平擴(kuò)展的,這個(gè)內(nèi)存浪費(fèi)也會(huì)成倍增加。
所以 hashmap 的方式所以查詢(xún)高效,但在實(shí)現(xiàn)層來(lái)說(shuō)不太可行。
算法二: 對(duì)網(wǎng)段列表進(jìn)行順序匹配
目前可以看到一些開(kāi)源的實(shí)現(xiàn)大都采用這種方式,比如場(chǎng)景段落描述的 nginx 兩個(gè)功能模塊,可以再 accss 模塊和 realip 模塊發(fā)現(xiàn)都是將配置存儲(chǔ)為 cidr 列表,然后逐個(gè)匹配;另外一個(gè)實(shí)現(xiàn)是 openresty 的 lua-resty-iputils 模塊,這個(gè)代碼看起來(lái)比較直觀些:
- local function ip_in_cidrs(ip, cidrs)
- local bin_ip, bin_octets = ip2bin(ip)
- if not bin_ip then
- return nil, bin_octets
- end
- for _,cidr in ipairs(cidrs) do
- if bin_ip >= cidr[1] and bin_ip <= cidr[2] then
- return true
- end
- end
- return false
- end
開(kāi)源的實(shí)現(xiàn)在應(yīng)付絕大多數(shù)簡(jiǎn)單場(chǎng)景足夠可用,但后面的測(cè)試可以看到,當(dāng)ip網(wǎng)段數(shù)量上升的時(shí)候,性能還是欠缺。
算法三: 二分查找
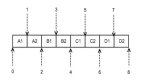
實(shí)際的算法其實(shí)很簡(jiǎn)單,二分查找即可,假設(shè)這些 ip 網(wǎng)段都是互不相鄰的,采用類(lèi)似 java 的二分查找即可,如圖:
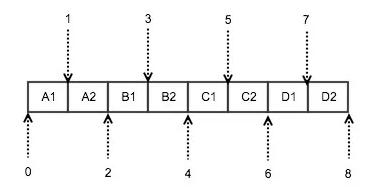
假設(shè)有 A, B, C, D 四個(gè)互不相鄰的 ip 網(wǎng)段,每個(gè)網(wǎng)段可以轉(zhuǎn)化為兩個(gè)數(shù)字:起始ip的整型表示和終止 ip 的整型表示;比如 0.0.0.0/24 可以轉(zhuǎn)化為 [0, 255]。這樣四個(gè)網(wǎng)段轉(zhuǎn)化為 8 個(gè)數(shù)字,可以進(jìn)行排序,由于網(wǎng)段是互不相鄰的,所以一定是圖上這種一個(gè) ip 段接一個(gè) ip 段的情形。這樣匹配的算法會(huì)比較簡(jiǎn)單:
- 將被查詢(xún) ip 轉(zhuǎn)化為數(shù)字,并在數(shù)組中進(jìn)行二分查找;
- 參考 java 的二分實(shí)現(xiàn),當(dāng)查詢(xún)命中時(shí),直接返回命中數(shù)字的index;當(dāng)查詢(xún)未命中時(shí),返回一個(gè)負(fù)數(shù),其絕對(duì)值表示了其插入位置(具體實(shí)現(xiàn)需略作變化,這里略過(guò)不計(jì));
- 第二步如果返回值為正數(shù),恭喜你,找到了,直接命中;
- 第二步如果返回的為負(fù)數(shù),同時(shí)插入坐標(biāo)為奇數(shù)(1, 3, 5, 7),說(shuō)明插入點(diǎn)正好在一個(gè)網(wǎng)段之內(nèi),說(shuō)明命中;
- 第二步如果返回的為負(fù)數(shù),同時(shí)插入坐標(biāo)為偶數(shù)(0, 2, 4, 6, 8),說(shuō)明插入點(diǎn)正好在兩個(gè)網(wǎng)段之間,說(shuō)明此 ip 與所有網(wǎng)段都不命中;
- 證畢收工。
所以整個(gè)算法非常簡(jiǎn)單,不過(guò)這里假設(shè)了網(wǎng)段之間是互不相鄰的,這個(gè)很容易被忽視掉,下面做一些簡(jiǎn)單說(shuō)明。
任意兩個(gè)網(wǎng)段 A 和 B,可能有三種關(guān)系:
- 完全不相鄰。A 和 B 沒(méi)有任何重復(fù)的部分。
- 相包含,即 A 包含 B 或 B 包含 A。這種情形在數(shù)據(jù)預(yù)處理的時(shí)候可以發(fā)現(xiàn)并排除掉(只保留大的網(wǎng)段)。
- A 和 B 相交,但并不包含。即兩個(gè)網(wǎng)段存在相互交錯(cuò)的情形,下面通過(guò)圖形說(shuō)明此種情況不成立。
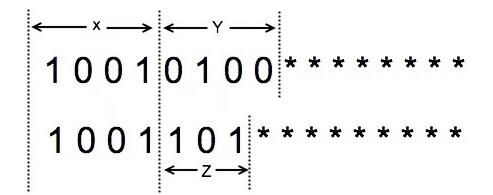
上圖描述了任意兩個(gè)網(wǎng)段:
- "*"表示掩碼
- 兩個(gè)網(wǎng)段,共32位,其中子網(wǎng)部分,前面 X 個(gè)連續(xù) bit 是相同的
- 第一個(gè)網(wǎng)段剩余 Y 個(gè) bit,第二個(gè)網(wǎng)段剩余 Z 個(gè) bit
所以:
- 假設(shè) Y == Z == 0, 表示兩個(gè)網(wǎng)段完全相等,否則
- Y == 0 && Z != 0, 說(shuō)明第一個(gè)網(wǎng)段包含第二個(gè)網(wǎng)段;Y != 0 && Z == 0, 則第二個(gè)網(wǎng)段更大
- Y != 0 && Z != 0,就是圖上的直觀表示,由于網(wǎng)段中的 ip 只能是*號(hào)部分的變化,所以?xún)蓚€(gè)網(wǎng)段不可能有相同的 ip,因?yàn)橹虚g至少有幾位是不同的
因此,如果對(duì)原始數(shù)據(jù)進(jìn)行一定的預(yù)處理,二分查找是安全有效的方式。
三、測(cè)試數(shù)據(jù)
最近手機(jī)出的有點(diǎn)多,我們也跟風(fēng)跑個(gè)分:
- 測(cè)試采用 Raspberry Pi 3 Model B, 4核 1.2GHz CPU, 1G 內(nèi)存。
- 通過(guò) wrk 進(jìn)行持續(xù)30s,50個(gè)連接的性能測(cè)試。
測(cè)試一: 基準(zhǔn)測(cè)試
- Running 30s test @ http://10.0.0.5/
- 12 threads and 50 connections
- Thread Stats Avg Stdev Max +/- Stdev
- Latency 6.54ms 4.80ms 194.75ms 99.29%
- Req/Sec 617.22 56.76 1.05k 80.42%
- Latency Distribution
- 50% 6.22ms
- 75% 6.99ms
- 90% 7.78ms
- 99% 10.74ms
- 221915 requests in 30.10s, 40.62MB read
- Requests/sec: 7373.42
- Transfer/sec: 1.35MB
測(cè)試二: 10000個(gè)黑名單+hashmap
- Running 30s test @ http://10.0.0.5/block_ip_1w
- 12 threads and 50 connections
- Thread Stats Avg Stdev Max +/- Stdev
- Latency 7.75ms 2.34ms 94.11ms 85.57%
- Req/Sec 512.72 68.86 780.00 74.28%
- Latency Distribution
- 50% 7.21ms
- 75% 8.36ms
- 90% 10.63ms
- 99% 14.07ms
- 184298 requests in 30.09s, 32.16MB read
- Requests/sec: 6125.35
- Transfer/sec: 1.07MB
測(cè)試三: 10000個(gè)黑名單+lua-resty-utils 模塊順序查找
- Running 30s test @ http://10.0.0.5/block_iputils_1w
- 12 threads and 50 connections
- Thread Stats Avg Stdev Max +/- Stdev
- Latency 162.93ms 100.27ms 1.96s 95.22%
- Req/Sec 27.47 12.28 150.00 66.46%
- Latency Distribution
- 50% 155.88ms
- 75% 159.40ms
- 90% 161.54ms
- 99% 670.13ms
- 9164 requests in 30.09s, 1.60MB read
- Socket errors: connect 0, read 0, write 0, timeout 11
- Requests/sec: 304.52
- Transfer/sec: 54.41KB
測(cè)試四: 10000個(gè)黑名單+二分查找
- Running 30s test @ http://10.0.0.5/block_ipcidr_bin_1w
- 12 threads and 50 connections
- Thread Stats Avg Stdev Max +/- Stdev
- Latency 9.60ms 6.78ms 196.80ms 97.53%
- Req/Sec 427.92 82.80 0.89k 60.15%
- Latency Distribution
- 50% 8.45ms
- 75% 10.94ms
- 90% 12.55ms
- 99% 18.58ms
- 153892 requests in 30.10s, 26.85MB read
- Requests/sec: 5112.69
- Transfer/sec: 0.89MB
通過(guò)測(cè)試數(shù)據(jù),可以看到二分搜索可以達(dá)到接近于基于 hash 的性能,但內(nèi)存消耗等會(huì)少很多;而簡(jiǎn)單的順序遍歷會(huì)帶來(lái)數(shù)量級(jí)的性能下降。
【本文是51CTO專(zhuān)欄機(jī)構(gòu)“豈安科技”的原創(chuàng)文章,轉(zhuǎn)載請(qǐng)通過(guò)微信公眾號(hào)(bigsec)聯(lián)系原作者】