自動駕駛汽車如何解決復雜交互問題?清華聯合MIT提出M2I方案
自動駕駛汽車上路時,不可避免的需要學習一些道路上的“潛規則”。自動駕駛系統需要察言觀色,隨機應變地及時發現什么時候應該減速禮讓,什么時候又應該發現別人正在禮讓而盡快加速通過。由于道路環境的復雜性,很多新手司機都未必能夠做出合適的判斷。
這種復雜性導致基于規則的方法很難在覆蓋到全部情況的同時不出現互相沖突的情況。來自清華大學的研究團隊提出了一種基于自監督學習的方法,從已有的軌跡預測數據集中學得道路上的各種“禮儀”,并正確判斷出沖突中的禮讓關系。該研究將預測的關系在充滿復雜交互的 Waymo Interactive Motion Prediction 數據集上進行了測試,并提出了 M2I 框架來使用預測出的關系進行場景級別的交互軌跡預測。
該項目主要由清華大學孫橋和MIT黃昕合作完成,清華MARS Lab趙行老師給予指導。

- 論文地址:https://arxiv.org/abs/2202.11884
- 項目地址:https://tsinghua-mars-lab.github.io/M2I/
軌跡預測問題是自動駕駛系統中的重要一環,對自動駕駛車輛安全行駛不可或缺。軌跡預測模塊通常作為識別 (Detection) 和跟蹤 (Tracking) 的下游系統,使用已有的高精地圖和識別到的周圍的其他車輛或行人的信息來預測他們未來可能會做出哪些行為。軌跡預測系統會以軌跡或熱力圖的形式輸出預測結果,以便下游的規劃 (Planning) 系統規劃出一條對于自動駕駛車自身最為合理的下一步的決策或軌跡。
盡管大多數軌跡預測方法都通過 GNN 或基于 Attention 的方法嘗試學習道路上的車輛和行人之間的關系,但是這些方法通常面對以下一些難以克服的挑戰:
1. 模型預測的關系是隱式的所以缺乏可解釋性,也難以確定模型是否真的學習到了這些關系;
2. 模型預測的關系和最終輸出的軌跡之間并不統一(如圖 1 第一行所示),會天然出現重疊的情況,無法確保場景級別的合理性;
3. 道路使用者的決策存在順序關系,模型預測無法區別邏輯上的預測順序,而是只能并行逐個預測。
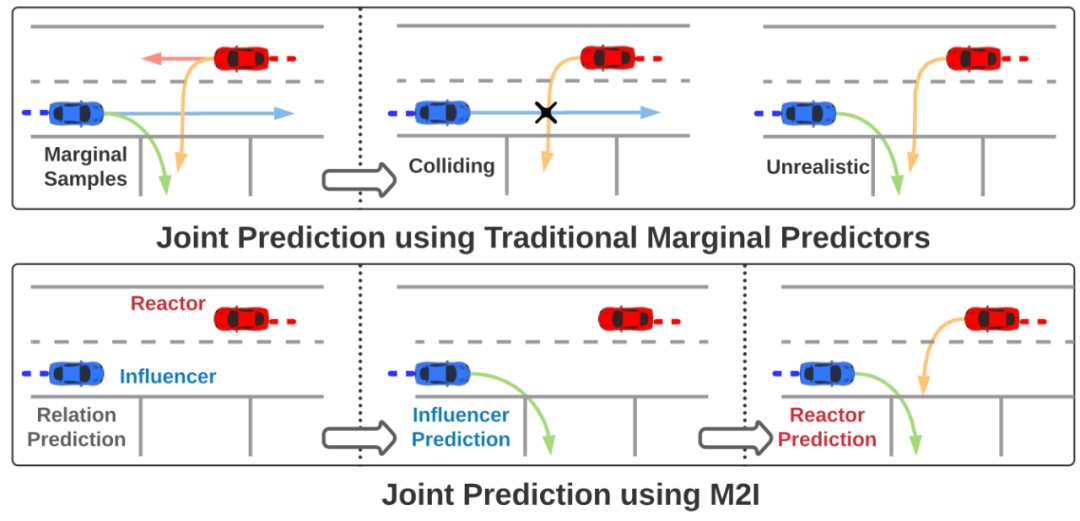
圖 1: 逐車進行軌跡預測的方法輸出的軌跡之間會存在碰撞
為了解決這些問題,研究者提出了一個簡單且有效的框架 M2I(如圖 1 第二行)。使用 M2I 框架,你可以快速的將手頭已有的任何軌跡預測模型進行改造后,獲得場景級別的關系預測能力以及基于一輛車的軌跡預測另一輛車的軌跡的能力。使用這兩種能力即可確保你的新模型獲得針對交互場景的更好預測效果。
多智能體軌跡預測轉單智能體軌跡預測
首先讓我們來看一下 M2I 的整體框架。M2I 由三個模塊組成, 如圖 2。這三個模塊分別是關系預測模塊,單智能體軌跡預測,條件軌跡預測。
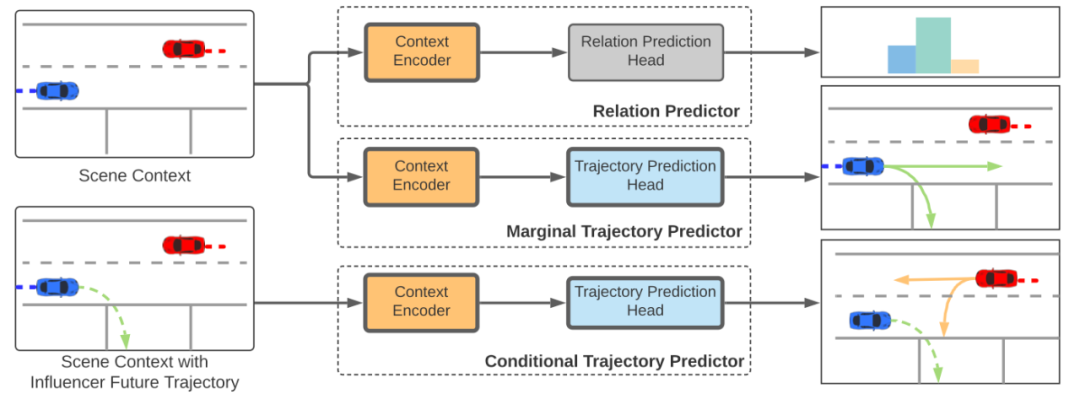
圖 2: M2I 軌跡預測框架
關系預測
復雜的道路使用者之間的關系可以被抽象為多個關系對,該研究將每一對道路使用者分類為一個 影響者 (Influencer) 和一個 響應者 (Reactor),將響應者定義為沖突中的需要禮讓的一方,而影響者則是不需要禮讓的一方。由此可以將交互中的軌跡預測問題抽象成兩次軌跡預測,一次是預測影響者的軌跡,一次是使用預測好的影響者的軌跡去預測響應者的軌跡。這樣的方法確保了兩者在場景級別上預測的軌跡的一致性從而最大程度上避免了重疊等不合理的情況。
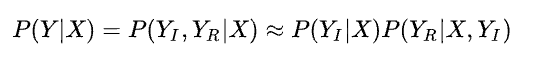
那么如何預測誰是影響者誰是響應者呢?或者說預測沖突中誰應該禮讓。該研究提出了一種基于時空軌跡交錯的方法從已有數據集中挖掘 Ground Truth 標簽的方法。具體來說,在數據集中,如果任意兩個道路使用者的軌跡在不同時間上產生了交叉,該方法則標記優先通過這個交叉點的智能體為影響者,后通過的標記為響應者。通過對這個自動生成的標簽的學習,該模型可以學習到沖突時的先行關系。
該研究使用的關系預測模型是將 DenseTNT 的 Trajectory Prediction Head 換為一個普通的分類 Classification Head 改造得到的。研究者發現不對已有模型的其他部分進行任何修改,就可以將關系預測的準確率達到 90% 以上。對比實驗顯示,使用準確率越高的關系進行 Conditional Trajectory Prediction 可以獲得越好的效果。
研究者還將關系預測拓展到多智能體的關系預測上。針對多智能體,該研究將他們兩兩成對進行預測,并將預測結果組成一個有向圖來表示他們之間的關系,結果如圖 3 所示,M2I 的關系預測模塊可以很好地拓展到多智能體的關系預測上。
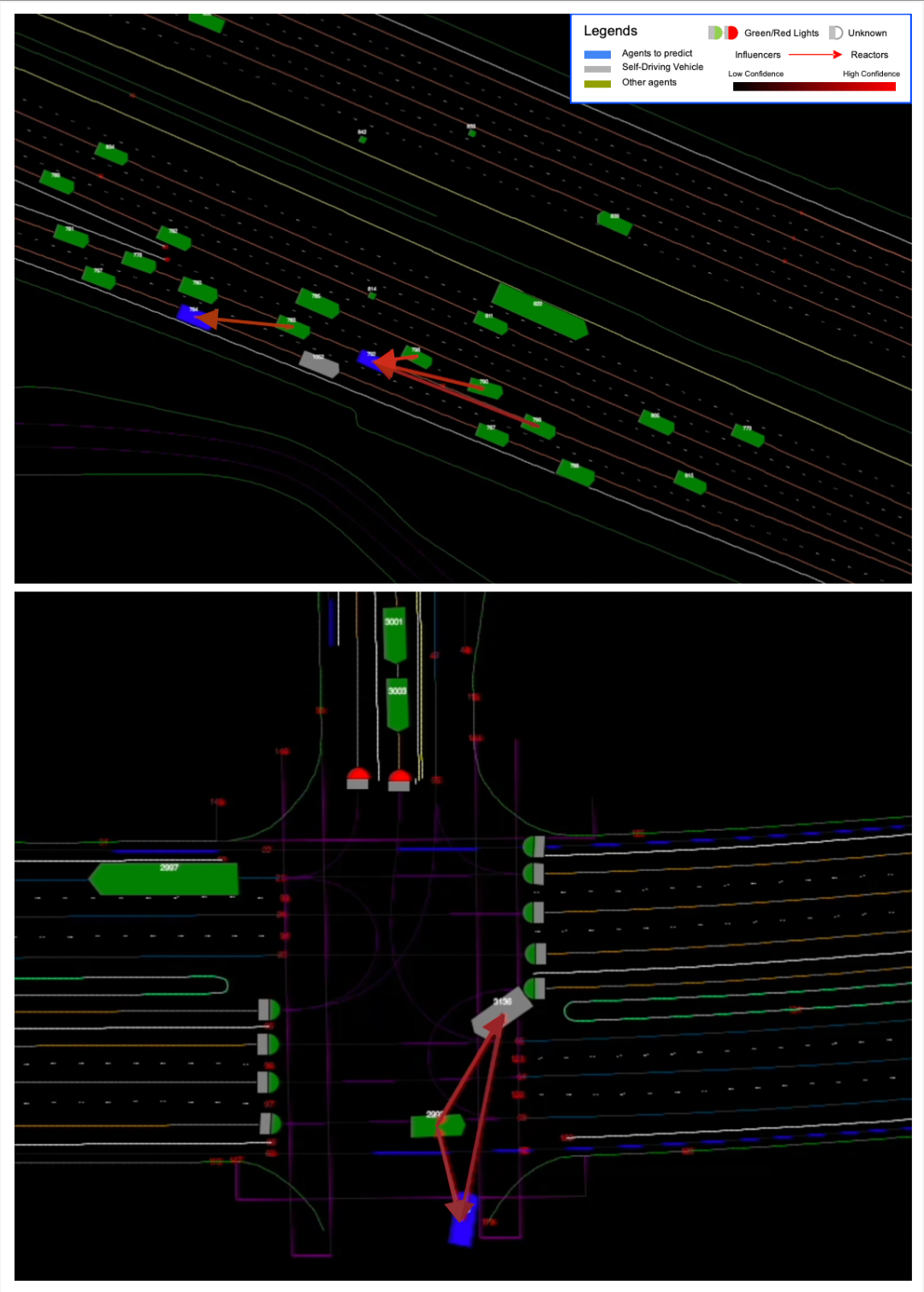
圖 3: 復雜場景下的多智能體的關系預測
軌跡預測
可以使用任何常見的軌跡預測模塊來替換 M2I 框架中的單智能體軌跡預測模塊,在該論文的實驗中,研究者使用了 DenseTNT 進行單智能體軌跡預測。對于 Conditional Trajectory Prediction,研究者修改了 DenseTNT 的 Encoder,將影響者的未來的軌跡(在使用的 Waymo 數據集中,未來軌跡為 8s,共 80 幀)與其他信息共同進行編碼供模型進行學習。訓練時影響者未來的軌跡是數據集中的 ground truth 軌跡,預測時影響者未來的軌跡是單智能體模塊輸出的軌跡。對于 Conditional Trajectory Prediction,該研究沒有修改除了 Encoder 之外模型的其他結構。
實驗結果
實驗結果證明,相比于其他幾個在 leaderboard 上的方法,使用了 M2I 框架的 DenseTNT 模型表現明顯優于其他方法。尤其是在車輛之間的交互上,使用 M2I 預測在 mAP 上相比其他模型性能提升明顯。
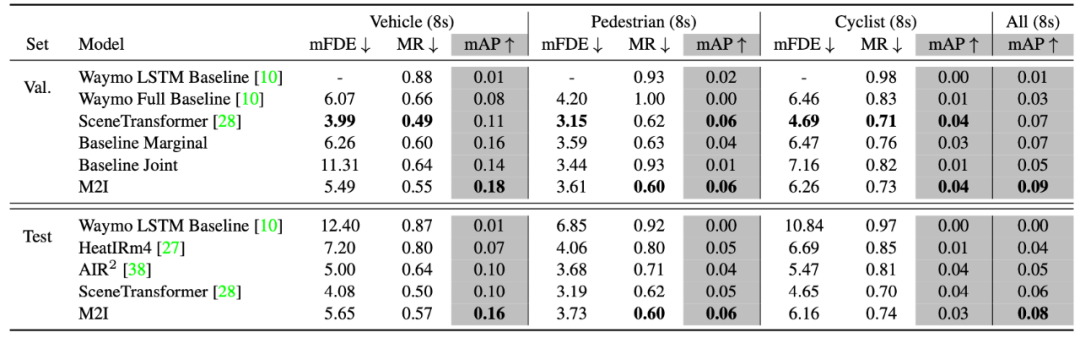
圖 4: M2I 在 Interactive Motion Prediction 上的表現明顯優于其他已有方法
該研究還嘗試了使用 TNT 作為 Backbone。實驗結果顯示,使用 M2I 框架同樣可以幫助 TNT 提升在交互場景中的性能表現,從而證明了 M2I 框架可以不受限于某個指定的 backbone。
定性分析顯示,使用 M2I 框架后,預測軌跡在場景級別上表現的更為接近真實的交互軌跡,如圖 5 所示。
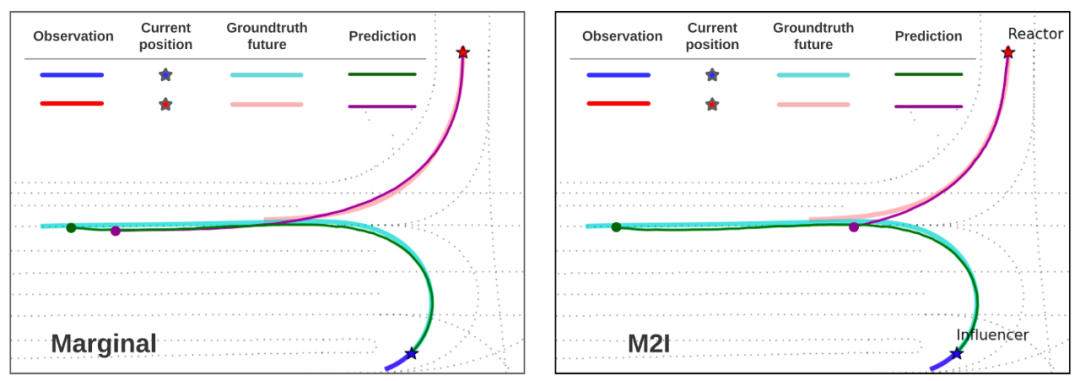
圖 5: M2I 更好的學習到了場景中兩輛正在交互的車輛應該如何先后完成轉彎