













裝在手機里的3D姿態估計,模型尺寸僅同類1/7,誤差卻只有5厘米
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
長久以來,三維姿態估計都在追求準確性上一路狂奔。
但精度提高的同時,也帶來了計算成本的上升。
而剛剛被CPVR 2021接受的論文中所提出的模型,MobileHumanPose卻可以同時做到又小又好。
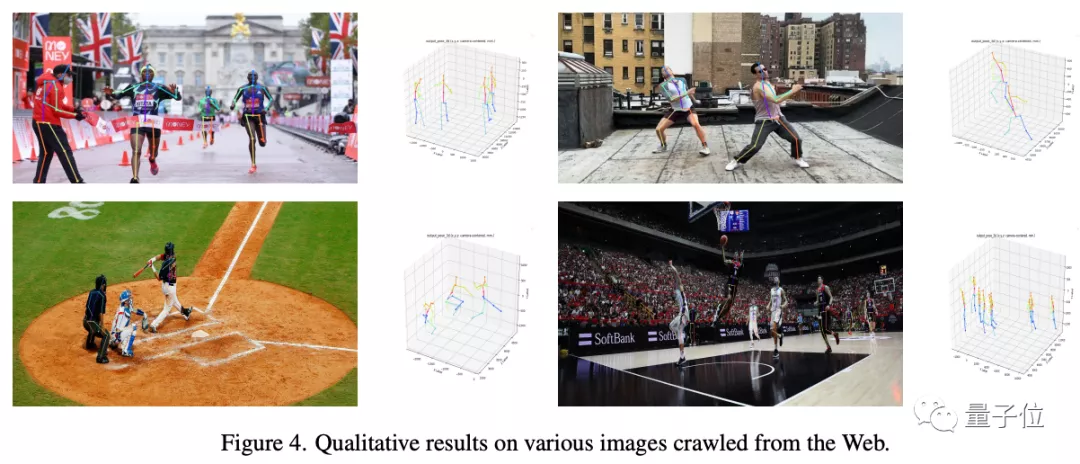
還是放在手機上都能hold得住的那種。來感受一下這個feel:

這種動作的健身操也沒問題:
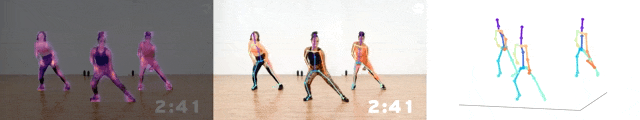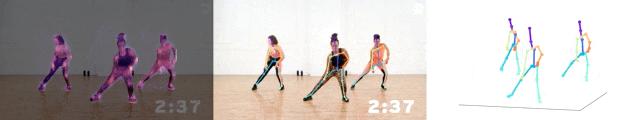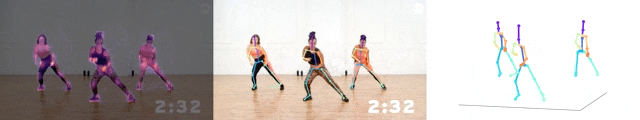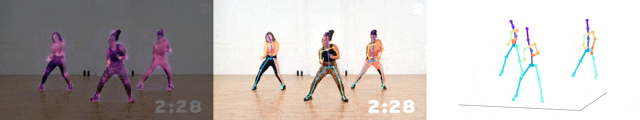
據了解,這個模型的尺寸,只有基于ResNet-50的模型的1/7,算力達到了3.92GFLOPS。
而且平均每關節位置誤差(MPJPE),也只有大約5厘米。
那么這一模型到底是如何在有限的算力下產生極佳性能的呢?
基于編碼器-解碼器結構的改進
這是一個從基本的編碼器-解碼器結構改良得來的模型。
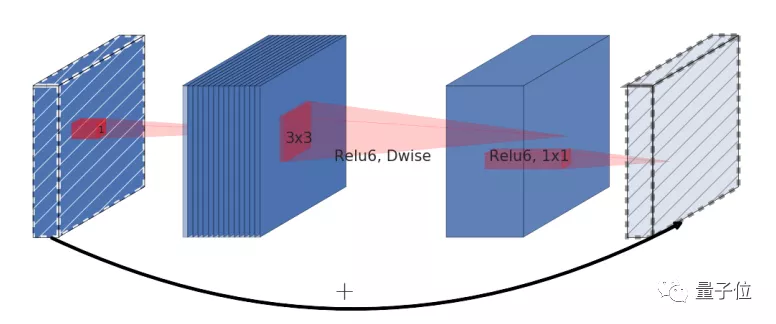
在編碼器用于全局特征提取,而解碼器進行姿態估計的基礎架構上,研究團隊對其主干網絡、激活函數,以及Skip concatenation功能都進行了修改。
先來看研究團隊選擇的主干網絡,MobileNetV2。
他們在MobileNetV2的前四個倒置殘差塊(Residual Block)處修改了通道大小,獲得了性能提升。
接下來,將PReLU函數用于實現激活功能,其中ai為學習參數 yi是輸入信號。
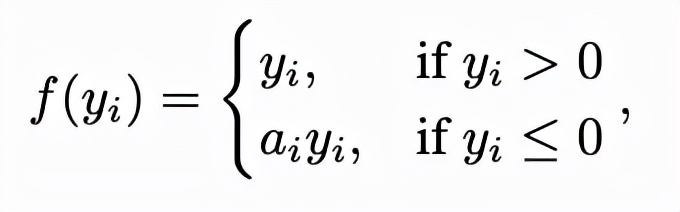
這一函數中的可學習參數能夠在每一層網絡都獲得額外的信息,因此在人體姿勢估計任務中使用參數化PReLU時可提升性能。
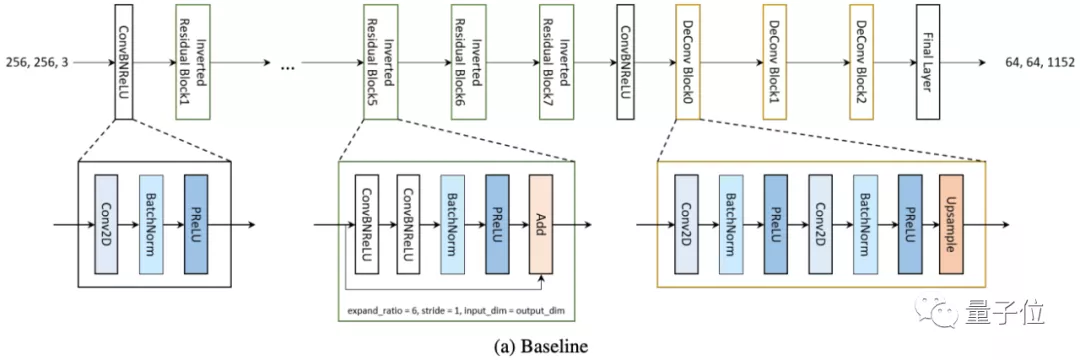
△修改了激活函數后的baseline
現在,模型的效率已經不低了,但考慮到推理速度,團隊使用Skip concatenation結構。這一結構能從編碼器到解碼器中導出低級別特征信號(Lowlevel feature signal),不會降低性能。

參數量減少5倍,計算成本降到1/3
團隊使用Human3.6M和MuCo-3DHP作為三維人體姿勢數據集,他們提出了MobileNetV2的大小兩個模型。
在Human3.6M上,MobileNetV2大模型實現了51.44毫米的平均每關節位置誤差。
且其參數量為4.07M,對比同類模型的20.4M(chen)減少了5倍,計算成本為5.49GFLOPS,是同類模型的1/3不到(14.1G)。
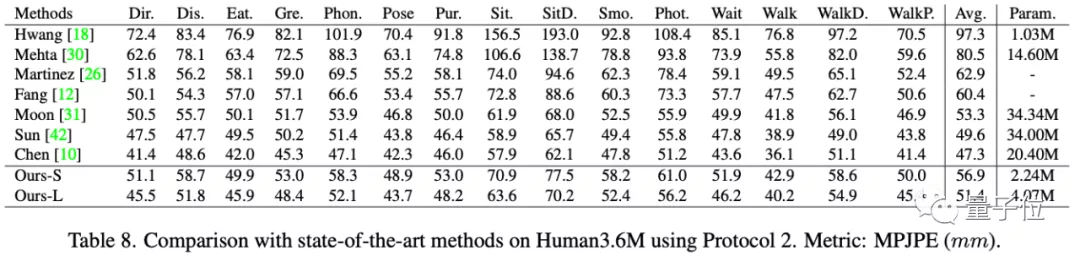
對于多人三維姿勢估計任務,研究者使用RootNet來估計每個人的絕對坐標,在MuPoTS的20個場景中進行了實驗:
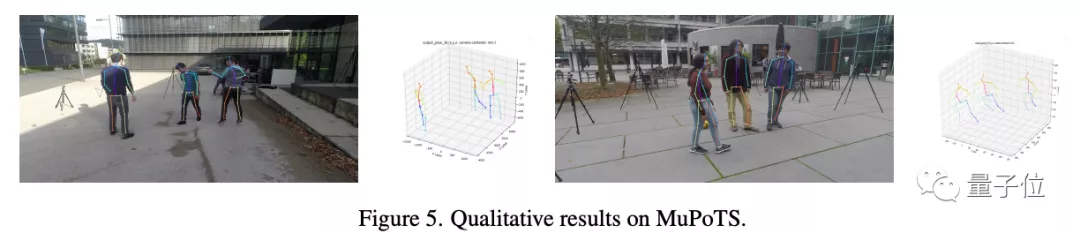
實驗結果證明,對比Zerui Chen等研究者提出的獲ECCV 2020的三維人體姿態估計方法,MobileNetV2在一般場景中的性能都更好,且在少數場景中取得了最佳性能:

在模型效率上,MobileNetV2的大模型效率為2.24M/3.92GFLOPS,遠超同類模型的13.0M/10.7GFLOPS(Zerui Chen)。
而小模型也能實現56.94毫米的平均每關節位置誤差,有224萬個參數,計算成本為3.92GFLOPS。
作者介紹
論文的三位作者皆畢業于韓國高等技術研究院,一作Sangbum Choi為該校的電機及電子工程專業碩士。
論文:
https://openaccess.thecvf.com/content/CVPR2021W/MAI/html/Choi_MobileHumanPose_Toward_Real-Time_3D_Human_Pose_Estimation_in_Mobile_Devices_CVPRW_2021_paper.html
開源地址:
[1]https://github.com/SangbumChoi/MobileHumanPose
[2]https://github.com/ibaiGorordo/ONNX-Mobile-Human-Pose-3D























