了解MQ,讀這篇就夠了
一、簡介
MQ全稱為Message Queue-消息隊列,是一種應用程序對應用程序的消息通信,一端只管往隊列不斷發布信息,另一端只管往隊列中讀取消息,發布者不需要關心讀取消息的誰,讀取消息者不需要關心發布消息的是誰,各干各的互不干擾。
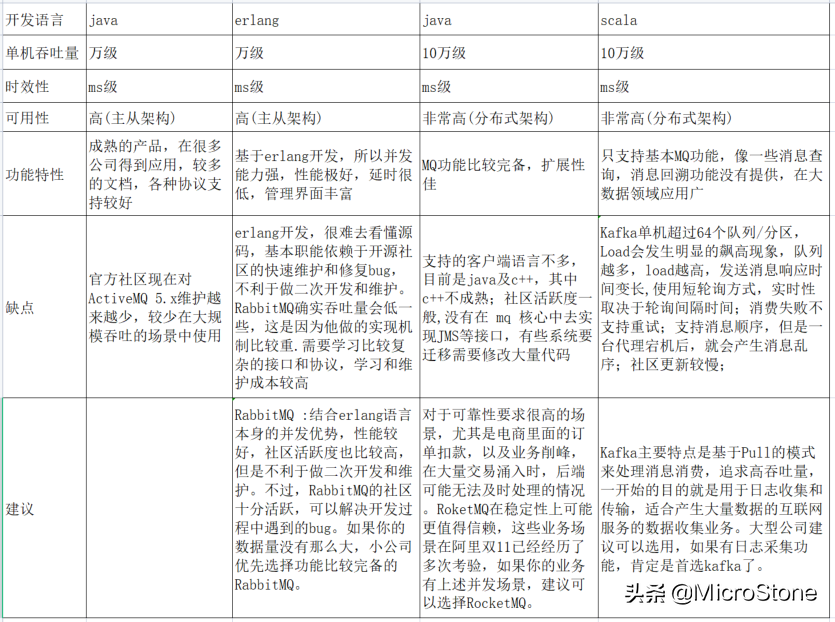
市場上現在常用的消息隊列有:RabbitMQ、RocketMQ、Kafka,ActiveMQ。
二、MQ的優勢
(1) 解耦
使用消息MQ后,只需要保證消息格式不變,不需要關心發布者及消費者之間的關系,這兩者不需要彼此聯系。
(2) 異步
在一些不需要即時(同步)的返回結果操作,通過消息隊列來實現異步。
(3) 削峰
在大量請求時(秒殺場景),使用消息隊列做緩沖處理,削弱峰值流量,防止系統在短時間內被峰值流量沖垮。
場景:在大量流量涌入高峰,如數據庫只能抗住2000的并發流量,可以使用MQ控制2000到數據庫中。
(4) 日志處理
日志存儲在消息隊列中,用來處理日志,比如kafka。
三、MQ的劣勢
- 系統的可用性降低
在還未引進MQ之前,系統只需要關系生產端與消費端的接口一致性就可以了,現在引進后,系統需要關注生產端、MQ與消費端三者的穩定性,這增加系統的負擔,系統運維成本增加。
- 系統的復雜性提高
引入了MQ,需要考慮的問題就增加了,如何保障消息的一致性,消費不被重復消費等問題。
- 一致性問題
A系統發送完消息直接返回成功,但是BCD系統之中若有系統寫庫失敗,則會產生數據不一致的問題。
四、常見問題
(1) 怎么保證消息沒有重復消費?使用消息隊列如何保證冪等性
冪等性:就是用戶對于同一操作發起的一次請求或者多次請求的結果是一致的,不會因為多次點擊而產生了副作用。
問題出現原因
我們先來了解一下產生消息重復消費的原因,對于MQ的使用,有三個角色:生產者、MQ、消費者,那么消息的重復這三者會出現:
- 生產者:生產者可能會推送重復的數據到MQ中,有可能controller接口重復提交了兩次,也可能是重試機制導致的。
- MQ:假設網絡出現了波動,消費者消費完一條消息后,發送ack時,MQ還沒來得及接受,突然掛了,導致MQ以為消費者還未消費該條消息,MQ回復后會再次推送了這條消息,導致出現重復消費。
- 消費者:消費者接收到消息后,正準備發送ack到MQ,突然消費者掛了,還沒得及發送ack,這時MQ以為消費者還沒消費該消息,消費者重啟后,MQ再次推送該條消息。
解決方案
在正常情況下,生產者是客戶,我們很難避免出現用戶重復點擊的情況,而MQ是允許存在多條一樣的消息,但消費者是不允許出現消費兩條一樣的數據,所以冪等性一般是在消費端實現的:
狀態判斷:消費者把消費消息記錄到redis中,再次消費時先到redis判斷是否存在該數據,存在則表示消費過,直接丟棄。
業務判斷:消費完數據后,都是需要插入到數據庫中,使用數據庫的唯一約束防止重復消費。插入數據庫前先查詢是否存在該數據,存在則直接丟棄消息,這種方式是比較簡單粗暴地解決問題。
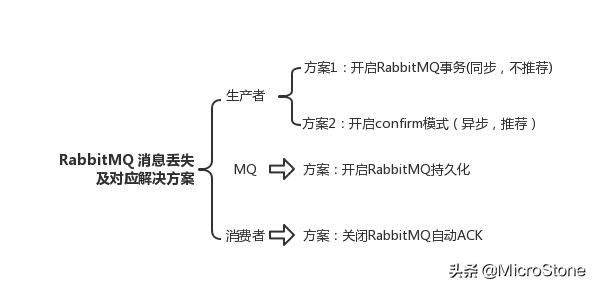
(2) 消息丟失的情況
(3) 消息的傳輸順序性
解決思路
在生產端發布消息時,每次法發布消息都把上一條消息的ID記錄到消息體中,消費者接收到消息時,做如下操作。
- 先根據上一條Id去檢查是否存在上一條消息還沒被消費,如果不存在(消費后去掉id),則正常進行,如果正常操作。
- 如果存在,則根據id到數據庫檢查是否被消費,如果被消費,則正常操作。
- 如果還沒被消費,則休眠一定時間(比如30ms),再重新檢查,如被消費,則正常操作。
- 如果還沒被消費,則拋出異常。
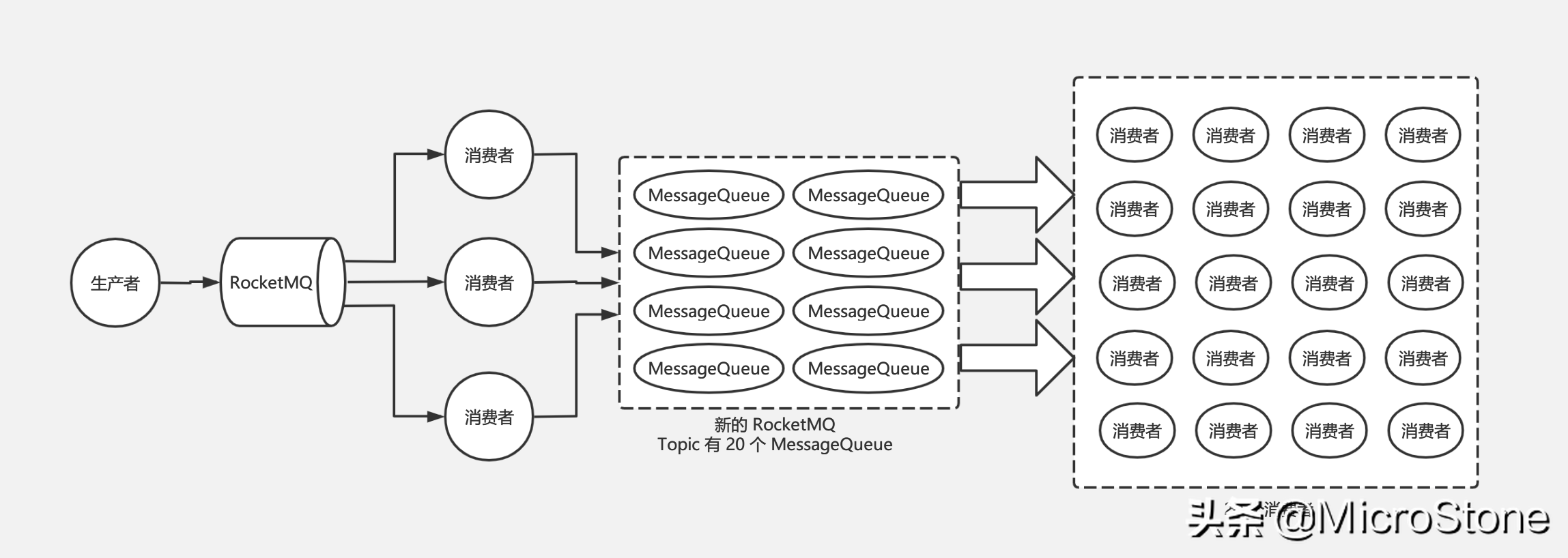
(4) 怎么解決百萬消息積壓問題
根據消息重要程度,可以分為兩種情況處理:
- 如果消息可以被丟棄,那么直接丟棄就好了。
- 一般情況下,消息是不可以被丟棄的,那么這樣需要考慮策略了,我們可以把原來的消費端重新當做生產端,重新部署一天MQ,再后面出現增加消費端,這樣形成另一條生產-消息-消費的線路。