













Java并發編程,看這篇就夠了!
本文轉載自微信公眾號「無敵碼農」,作者無敵碼農。轉載本文請聯系無敵碼農公眾號。
大家好!我是"無敵碼農"。今天的文章將給大家分享Java并發編程相關的知識點,雖然類似的文章已有很多,但本文將以更貼近實際使用場景的方式進行闡述。具體將對Java常見的并發編程方式和手段進行總結,以便可以從使用角度更好地感知Java并發編程帶來的效果,從而為后續更深入的理解Java并發機制進行鋪墊。
Java多線程概述
在Java中使用多線程是提高程序并發響應能力的重要手段,但同時它也是一把雙刃劍;如果使用不當也很容易導致程序出錯,并且還很難直觀地找到問題。這是因為:1)、線程運行本身是由操作系統調度,具有一定的隨機性;2)、Java共享內存模型在多線程環境下很容易產生線程安全問題;3)、不合理的封裝依賴,極容易導致發布對象的不經意逸出。
所以,要用好多線程這把劍,就需要對Java內存模型、線程安全問題有較深的認識。但由于Java豐富的生態,在實際研發工作中,需要我們自己進行并發處理的場景大都被各類框架或組件給屏蔽了。這也是造成很多Java開發人員對并發編程意識淡薄的主要原因。
首先從Java內存模型的角度理解下使用多線程編程最核心的問題,具體如下圖所示:
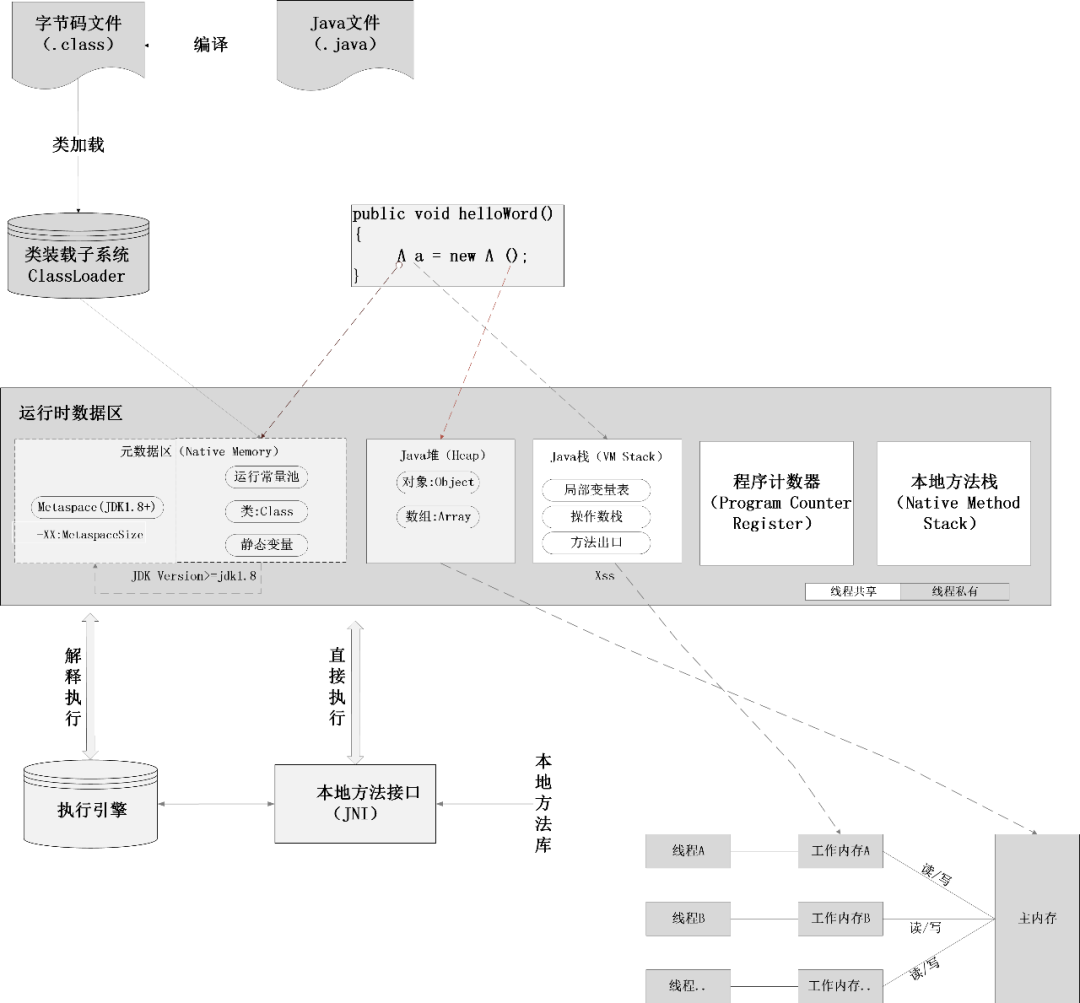
如上圖所示,在Java內存模型中,對于用戶程序來說用得最頻繁的就是堆內存和棧內存,其中堆內存主要存放對象及數組,例如由new()產生的實例。而棧內存則主要是存儲運行方法時所需的局部變量、操作數及方法出口等信息。
其中堆內存是線程共享的,一個類被實例化后生成的對象、及對象中定義的成員變量可以被多個線程共享訪問,這種共享主要體現在多個線程同時執行、同一個對象實例的某個方法時,會將該方法中操作的對象成員變量分別以多個副本的方式拷貝到方法棧中進行操作,而不是直接修改堆內存中對象的成員變量值;線程操作完成后,會再次將修改后的變量值同步至堆內存中的主內存地址,并實現對其他線程的可見。
這個過程雖然看似行云流水,但在JVM中卻至少需要6個原子步驟才能完成,具體如下圖所示:
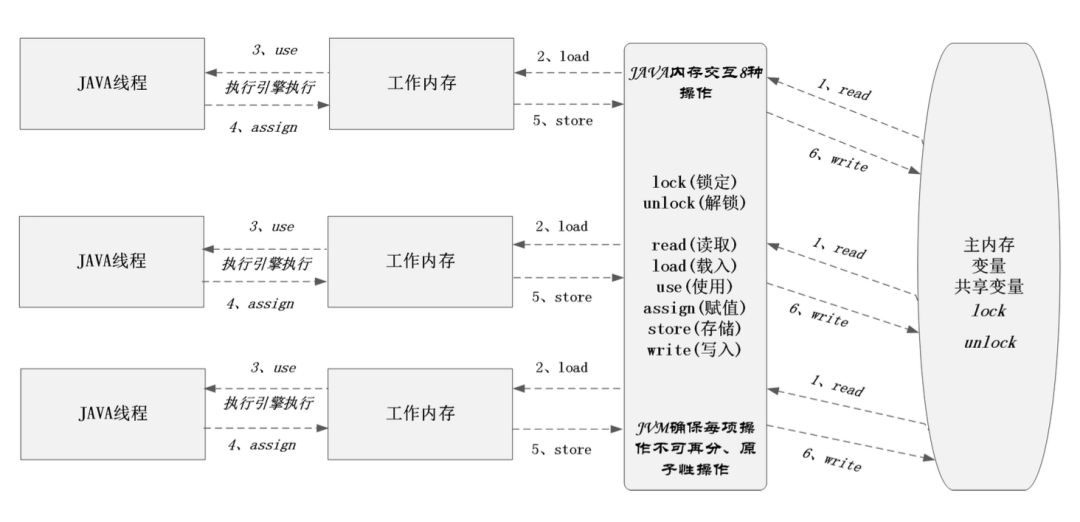
如上圖所示,在不考慮對共享變量進行加鎖的情況下,堆內存中一個對象的成員變量被線程修改大概需要以下6個步驟:
1、read(讀取):從堆內存中的讀取要操作的變量;
2、load(載入):將讀取的變量拷貝到線程棧內存;
3、use(使用):將棧內存中的變量值傳遞給執行引擎;
4、assign(賦值):將從執行引擎得到的結果賦值給棧內存中變量;
5、store(存儲):將變更后的棧內存中的變量值傳遞到主內存;
6、write(寫入):變更主內存中的變量值,此時新值對所有線程可見;
由此可見,每個線程都可以按這幾個步驟并行操作同一個共享變量。可想而知,如果沒有任何同步措施,那么在多線程環境下,該共享變量的值將變得飄忽不定,很難得到最終正確的結果。而這就是所謂的線程安全問題,也是我們在使用多線程編程時,最需要關注的問題!
線程池的使用
在實際場景中,多線程的使用并不是單打獨斗,線程作為寶貴的系統資源,其創建和銷毀都需要耗費一定的系統資源;而無限制的創建線程資源,也會導致系統資源的耗盡。所以,為了重復使用線程資源、限制線程的創建行為,一般都會通過線程池來實現。以Java Web服務中使用最廣的Tomcat服務器舉例,為了并行處理網絡請求就使用了線程池,源碼示例如下:
- public boolean processSocket(SocketWrapperBase<S> socketWrapper,
- SocketEvent event, boolean dispatch) {
- try {
- if (socketWrapper == null) {
- return false;
- }
- SocketProcessorBase<S> sc = null;
- if (processorCache != null) {
- sc = processorCache.pop();
- }
- if (sc == null) {
- sc = createSocketProcessor(socketWrapper, event);
- } else {
- sc.reset(socketWrapper, event);
- }
- //這里通過線程池對線程執行進行管理
- Executor executor = getExecutor();
- if (dispatch && executor != null) {
- executor.execute(sc);
- } else {
- sc.run();
- }
- } catch (RejectedExecutionException ree) {
- getLog().warn(sm.getString("endpoint.executor.fail", socketWrapper) , ree);
- return false;
- } catch (Throwable t) {
- ExceptionUtils.handleThrowable(t);
- // This means we got an OOM or similar creating a thread, or that
- // the pool and its queue are full
- getLog().error(sm.getString("endpoint.process.fail"), t);
- return false;
- }
- return true;
- }
上述代碼為Tomcat源碼使用線程池并發處理網絡請求的示例,這里以Tomcat為例,主要是因為基于Spring Boot、Spring MVC開發的Web服務大都運行在Tomcat容器,而對于線程、線程池使用的復雜度都被屏蔽在中間件和框架中了,所以很多同學雖然寫了不少Java代碼,但在業務研發中額外使用線程的場景可能并不多,舉這個例子的目的就是為了提升下并發編程的意識!
在Java中使用線程池的主要方式是Executor框架,該框架作為JUC并發包的一部分,為Java程序提供了一個靈活的線程池實現。其邏輯層次如下圖所示:
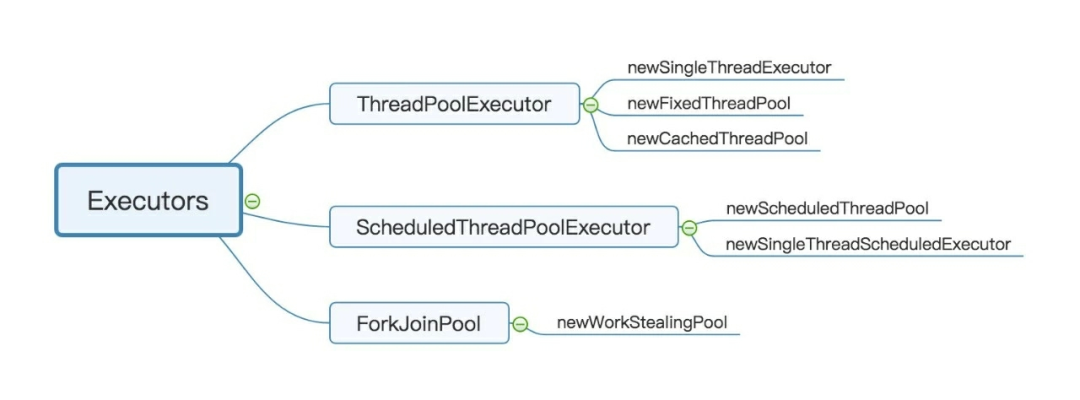
如圖所示,使用Executor框架,既可以通過直接自定義配置、擴展ThreadPoolExecutor來創建一個線程池,也可以通過Executors類直接調用“newSingleThreadExecutor()、newFixedThreadPool()、newCachedThreadPool()”這三個方法來創建具有一定功能特征的線程池。
除此之外,也可以通過自定義配置、擴展ScheduledThreadPoolExecutor來創建一個具有周期性、定時功能的線程池,例如線程10s后運行、線程每分鐘運行一次等。同樣,與ThreadPoolExecutor一樣,如果不想自定義配置,也可以通過Executors類直接調用“newScheduledThreadPool()、newSingleThreadScheduledExecutor()”這兩個方法來分別創建具備自動線程規模擴展能力和線程池中只允許有單個線程的特定線程池。
而ForkJoinPool是jdk1.8以后新增的一種線程池實現類型,類似于Fork-Join框架所支持的功能。這是一種可以將一個大任務拆分成多個任務隊列,并具體分配給不同線程處理的機制,而關鍵的特性在于,通過竊取算法,某個線程在執行完本隊列任務后,可以竊取其他隊列的任務進行執行,從而最大限度提高線程的利用效率。
在實際應用中,雖然可以通過Executors方便的創建單個線程、固定線程或具備自動收縮能力的線程池,但一般還是建議直接通過ThreadPoolExecutor或ScheduledThreadPoolExecutor自定義配置,這主要是因為Executors默認創建的線程池,很多采用的是無界隊列,例如LinkedBlockingQueue,這樣線程就可以被無限制的添加都線程池的任務執行隊列,如果請求量過大容易造成OOM。
接下來以一個實際的例子來演示通過ThreadPoolExecutor如何自定義配置一個業務線程池,具體如下:
1)、配置一個線程池類
- public final class SingleBlockPoolExecutor {
- /**
- * 自定義配置線程池(線程池核心線程數、最大線程數、存活時間設置、采用的隊列類型、線程工廠類、線程池拒絕處理類)
- */
- private final ThreadPoolExecutor pool = new ThreadPoolExecutor(30, 100, 5, TimeUnit.MINUTES,
- new ArrayBlockingQueue<Runnable>(100), new BlockThreadFactory(), new BlockRejectedExecutionHandler());
- public ThreadPoolExecutor getPool() {
- return pool;
- }
- private SingleBlockPoolExecutor() {
- }
- /**
- * 定義線程工廠
- */
- public static class BlockThreadFactory implements ThreadFactory {
- private AtomicInteger count = new AtomicInteger(0);
- @Override
- public Thread newThread(Runnable r) {
- Thread t = new Thread(r);
- String threadName = SingleBlockPoolExecutor.class.getSimpleName() + "-" + count.addAndGet(1);
- t.setName(threadName);
- return t;
- }
- }
- /**
- * 定義線程池拒絕機制處理類
- */
- public static class BlockRejectedExecutionHandler implements RejectedExecutionHandler {
- @Override
- public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
- try {
- //被拒線程再次返回阻塞隊列進行等待處理
- executor.getQueue().put(r);
- } catch (InterruptedException e) {
- Thread.currentThread().interrupt();
- }
- }
- }
- /**
- * 在靜態內部類中持有單例類的實例,并且可直接被初始化
- */
- private static class Holder {
- private static SingleBlockPoolExecutor instance = new SingleBlockPoolExecutor();
- }
- /**
- * 調用getInstance方法,事實上是獲得Holder的instance靜態屬性
- *
- * @return
- */
- public static SingleBlockPoolExecutor getInstance() {
- return Holder.instance;
- }
- /**
- * 線程池銷毀方法
- */
- public void destroy() {
- if (pool != null) {
- //線程池銷毀
- pool.shutdownNow();
- }
- }
- }
如上述代碼所示,通過單例模式配置了一個線程池。在對ThreadPoolExecutor的配置中,需要設置“核心線程數、最大線程數、存活時間設置、采用的隊列類型、線程工廠類、線程池拒絕處理類”,這幾個核心參數。
2)、定義系統全局線程池管理類
- public class AsyncManager {
- /**
- * 任務處理公共線程池
- */
- public static final ExecutorService service = SingleBlockPoolExecutor.getInstance().getPool();
- }
在應用中,除了框架定義的線程池外,如果自定義線程池,為了方便統一管理和使用,可以建立一個全局管理類,如上所示,該類通過靜態變量的方式初始化了前面我們所定義的線程池。
3)、業務中使用
- @Service
- @Slf4j
- public class OrderServiceImpl implements OrderService {
- @Override
- public CreateOrderBO createOrder(CreateOrderDTO createOrderDTO) {
- //1、同步處理核心業務邏輯
- log.info("同步處理業務邏輯");
- //2、通過線程池提交,異步處理非核心邏輯,例如日志埋點
- AsyncManager.service.execute(() -> {
- System.out.println("線程->" + Thread.currentThread().getName() + ",正在執行異步日志處理任務");
- });
- return CreateOrderBO.builder().result(true).build();
- }
- }
如上代碼所示,業務中需要通過線程池異步處理時,可以通過線程池管理類獲取對應的線程池,并向其提交執行線程任務。
FutureTask實現異步結果返回
在使用Thread或Runnable實現的線程處理中,一般是不能返回線程處理結果的。但如果希望在調用線程異步處理完成后,能夠獲得線程異步處理的結果,那么就可以通過FutureTask框架實現。示例代碼如下:
- @Service
- @Slf4j
- public class OrderServiceImpl implements OrderService {
- @Override
- public CreateOrderBO createOrder(CreateOrderDTO createOrderDTO) {
- //Future異步處理返回執行結果
- //定義接收線程執行結果的FutureTask對象
- List<Future<Integer>> results = Collections.synchronizedList(new ArrayList<>());
- //實現Callable接口定義線程執行邏輯
- results.add(AsyncManager.service.submit(new Callable<Integer>() {
- @Override
- public Integer call() throws Exception {
- int a = 1, b = 2;
- System.out.println("Callable接口執行中");
- return a + b;
- }
- }));
- //輸出線程返回結果
- for (Future<Integer> future : results) {
- try {
- //這里獲取結果,等待時間設置200毫秒
- System.out.println("a+b=" + future.get(200, TimeUnit.MILLISECONDS));
- } catch (InterruptedException e) {
- e.printStackTrace();
- } catch (ExecutionException e) {
- e.printStackTrace();
- } catch (TimeoutException e) {
- e.printStackTrace();
- }
- }
- //判斷線程是否執行完畢,完畢則獲取執行結果
- return CreateOrderBO.builder().result(true).build();
- }
- }
如上述代碼,如果希望線程返回執行結果,那么可以通過實現Callable接口定義線程類,并通過FutureTask接收線程處理結果。不過在實際使用時,需要注意線程暫時未執行完成情況下的業務處理邏輯。
CountDownLatch實現線程并行同步
在并發編程中,一個復雜的業務邏輯可以通過多個線程并發執行來提高速度;但如果需要同步等待這些線程執行完后才能進行后續的邏輯,那么就可以通過CountDownLatch來實現對多個線程執行的同步匯聚。其邏輯示意圖如下:
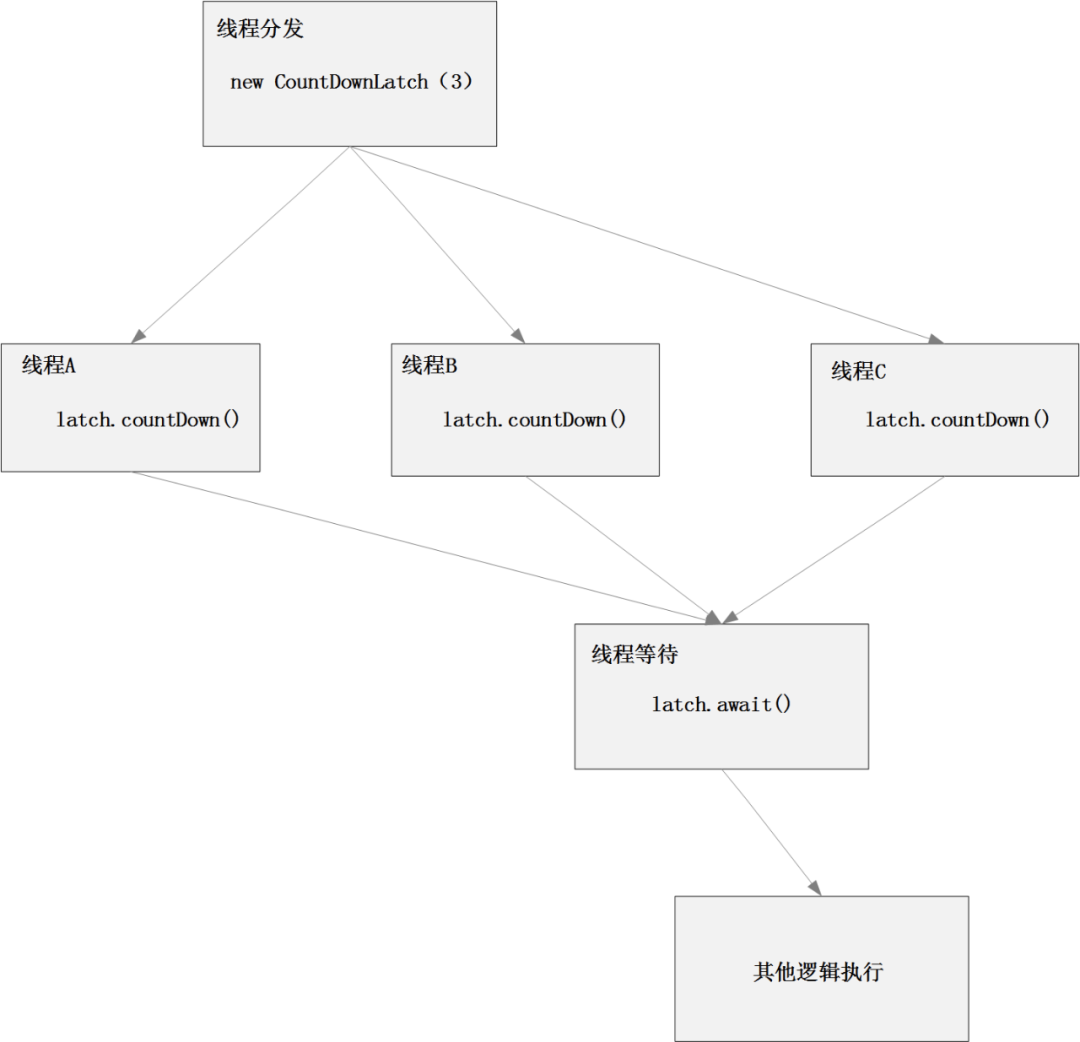
從原理上看CountDownLatch實際上是在其內部創建并維護了一個volatile類型的整數計數器,當調用countDown()方法時,會嘗試將整數計數器-1,當調用wait()方法時,當前線程就會判斷整數計數器是否為0,如果為0,則繼續往下執行,如果不為0,則使當前線程進入阻塞狀態,直到某個線程將計數器設置為0,才會喚醒在await()方法中等待的線程繼續執行。
常見的代碼使用示例如下:
1)、創建執行具體業務邏輯的線程處理類
- public class DataDealTask implements Runnable {
- private List<Integer> list;
- private CountDownLatch latch;
- public DataDealTask(List<Integer> list, CountDownLatch latch) {
- this.list = list;
- this.latch = latch;
- }
- @Override
- public void run() {
- try {
- System.out.println("線程->" + Thread.currentThread().getName() + ",處理" + list.size());
- } finally {
- //處理完計數器遞減
- latch.countDown();
- }
- }
- }
該線程處理類,在實例化時接收除了待處理數據參數外,還會接收CountDownLatch對象,在執行完線程邏輯,注意,無論成功或失敗,都需要調用countDown()方法。
2)、具體的使用方法
- @Service
- @Slf4j
- public class OrderServiceImpl implements OrderService {
- @Override
- public CreateOrderBO createOrder(CreateOrderDTO createOrderDTO) {
- //CountDownLatch的使用示例
- //模擬待處理數據生成
- Integer[] array = {10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 101, 102};
- List<Integer> list = new ArrayList<>();
- Arrays.asList(array).stream().map(o -> list.add(o)).collect(Collectors.toList());
- //對數據進行分組處理(5條記錄為1組)
- Map<String, List<?>> entityMap = this.groupListByAvg(list, 6);
- //根據數據分組數量,確定同步計數器的值
- CountDownLatch latch = new CountDownLatch(entityMap.size());
- Iterator<Entry<String, List<?>>> it = entityMap.entrySet().iterator();
- try {
- //將分組數據分批提交給不同線程處理
- while (it.hasNext()) {
- DataDealTask dataDealTask = new DataDealTask((List<Integer>) it.next().getValue(), latch);
- AsyncManager.service.submit(dataDealTask);
- }
- //等待分批處理線程處理完成
- latch.await();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- return CreateOrderBO.builder().result(true).build();
- }
- }
如上所示代碼,在業務邏輯中如果處理數據量多,則可以通過分組的方式并行處理,而等待所有線程處理完成后,再同步返回調用方。這種場景就可以通過CountDownLatch來實現同步!
CycliBarrier柵欄實現線程階段性同步
CountDownLatch的功能主要是實現線程的一次性同步。而在實際的業務場景中也可能存在這樣的情況,執行一個階段性的任務,例如”階段1->階段2->階段3->階段4->階段5"。那么在并發處理這個階段性任務時,就要在每個階段設置柵欄,只有當所有線程執行到某個階段點之后,才能繼續推進下一個階段任務的執行,其邏輯如圖所示:
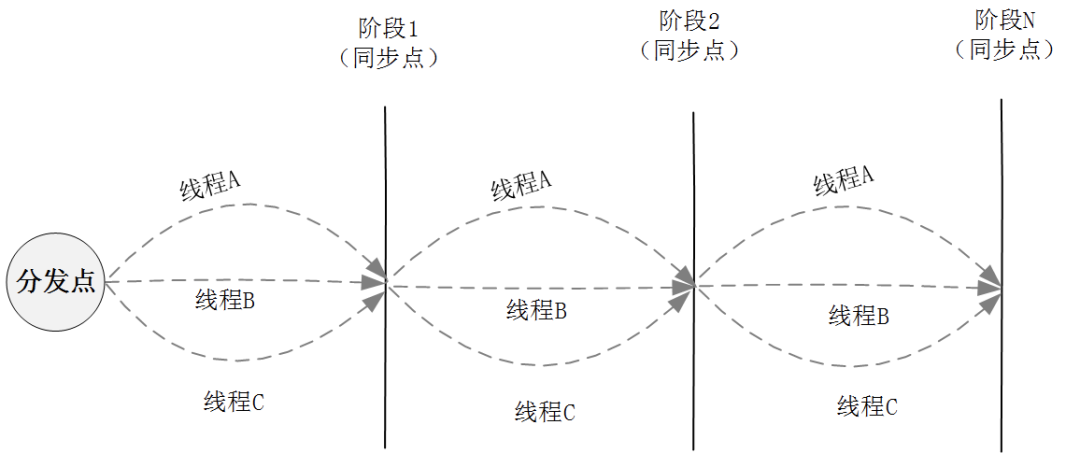
針對上述場景,就可以通過CycliBarrier來實現。而從實現上看,CyclicBarrier使用了基于ReentrantLock的互斥鎖實現;在CyclicBarrier的內部有一個計數器 count,當count不為0時,每個線程在到達同步點會先調用await方法將自己阻塞,并將計數器會減1,直到計數器減為0的時候,所有因調用await方法而被阻塞的線程就會被喚醒繼續執行。并進入下一輪阻塞,此時在new CyclicBarrier(parties) 時設置的parties值,會被賦值給 count 從而實現復用。
例如,計算某個部門的員工工資,要求在所有員工工資都計算完之后才能進行下一步整合操作。其代碼示例如下:
- @Slf4j
- @Service
- public class SalaryStatisticServiceImpl implements SalaryStatisticService {
- /**
- * 模擬部門員工存儲數據
- */
- public static Map<String, List<EmployeeSalaryInfo>> employeeMap = Collections.synchronizedMap(new HashMap<>());
- static {
- EmployeeSalaryInfo employeeA = new EmployeeSalaryInfo();
- employeeA.setEmployeeNo("100");
- employeeA.setBaseSalaryAmount(10000);
- employeeA.setSubsidyAmount(3000);
- EmployeeSalaryInfo employeeB = new EmployeeSalaryInfo();
- employeeB.setEmployeeNo("101");
- employeeB.setBaseSalaryAmount(30000);
- employeeB.setSubsidyAmount(3000);
- List<EmployeeSalaryInfo> list = new ArrayList<>();
- list.add(employeeA);
- list.add(employeeB);
- employeeMap.put("10", list);
- }
- @Override
- public StatisticReportBO statisticReport(StatisticReportDTO statisticReportDTO) {
- //查詢部門下所有員工信息(模擬)
- List<EmployeeSalaryInfo> employeeSalaryInfos = employeeMap.get(statisticReportDTO.getDepartmentNo());
- if (employeeSalaryInfos == null) {
- log.info("部門員工信息不存在");
- return StatisticReportBO.builder().build();
- }
- //定義統計總工資的安全變量
- AtomicInteger totalSalary = new AtomicInteger();
- //開啟柵欄(在各線程觸發之后觸發)
- CyclicBarrier cyclicBarrier = new CyclicBarrier(employeeSalaryInfos.size(), new Runnable() {
- //執行順序-B1(隨機)
- //該線程不會阻塞主線程
- @Override
- public void run() {
- log.info("匯總已分別計算出的兩個員工的工資->" + totalSalary.get() + ",執行順序->B");
- }
- });
- //執行順序-A
- for (EmployeeSalaryInfo e : employeeSalaryInfos) {
- AsyncManager.service.submit(new Callable<Integer>() {
- @Override
- public Integer call() {
- int totalAmount = e.getSubsidyAmount() + e.getBaseSalaryAmount();
- log.info("計算出員工{}", e.getEmployeeNo() + "的工資->" + totalAmount + ",執行順序->A");
- //匯總總工資
- totalSalary.addAndGet(totalAmount);
- try {
- //等待其他線程同步
- cyclicBarrier.await();
- } catch (InterruptedException e) {
- e.printStackTrace();
- } catch (BrokenBarrierException e) {
- e.printStackTrace();
- }
- return totalAmount;
- }
- });
- }
- //執行順序-A/B(之前或之后隨機,totalSalary值不能保證一定會得到,所以CyclicBarrier更適合無返回的可重復并行計算)
- //封裝響應參數
- StatisticReportBO statisticReportBO = StatisticReportBO.builder().employeeCount(employeeSalaryInfos.size())
- .departmentNo(statisticReportDTO.getDepartmentNo())
- .salaryTotalAmount(totalSalary.get()).build();
- log.info("封裝接口響應參數,執行順序->A/B");
- return statisticReportBO;
- }
- @Data
- public static class EmployeeSalaryInfo {
- /**
- * 員工編號
- */
- private String employeeNo;
- /**
- * 基本工資
- */
- private Integer baseSalaryAmount;
- /**
- * 補助金額
- */
- private Integer subsidyAmount;
- }
- }
上述代碼的執行結果如下:
- [kPoolExecutor-1] c.w.c.s.impl.SalaryStatisticServiceImpl : 計算出員工100的工資->13000,執行順序-
- [kPoolExecutor-2] c.w.c.s.impl.SalaryStatisticServiceImpl : 計算出員工101的工資->33000,執行順序-
- [kPoolExecutor-2] c.w.c.s.impl.SalaryStatisticServiceImpl : 匯總已分別計算出的兩個員工的工資->46000,
- [nio-8080-exec-2] c.w.c.s.impl.SalaryStatisticServiceImpl : 封裝接口響應參數,執行順序->A/B
從上述結果可以看出,受CycliBarrier控制的線程會等待其他線程執行完成后同步向后執行,并且CycliBarrier并不會阻塞主線程,所以最后響應參數封裝代碼可能在CycliBarrier匯總線程之前執行,也可能在其之后執行,使用時需要注意!
Semaphore(信號量)限制訪問資源的線程數
Semaphore可以實現對某個共享資源訪問線程數的限制,實現限流功能。以停車場線程為例,代碼如下:
- @Service
- @Slf4j
- public class ParkServiceImpl implements ParkService {
- /**
- * 模擬停車場的車位數
- */
- private static Semaphore semaphore = new Semaphore(2);
- @Override
- public AccessParkBO accessPark(AccessParkDTO accessParkDTO) {
- AsyncManager.service.execute(() -> {
- if (semaphore.availablePermits() == 0) {
- log.info(Thread.currentThread().getName() + ",車牌號->" + accessParkDTO.getCarNo() + ",車位不足請耐心等待");
- } else {
- try {
- //獲取令牌嘗試進入停車場
- semaphore.acquire();
- log.info(Thread.currentThread().getName() + ",車牌號->" + accessParkDTO.getCarNo() + ",成功進入停車場");
- //模擬車輛在停車場停留的時間(30秒)
- Thread.sleep(30000);
- //釋放令牌,騰出停車場車位
- semaphore.release();
- log.info(Thread.currentThread().getName() + ",車牌號->" + accessParkDTO.getCarNo() + ",駛出停車場");
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- });
- //封裝返回信息
- return AccessParkBO.builder().carNo(accessParkDTO.getCarNo())
- .currentPositionCount(semaphore.availablePermits())
- .isPermitAccess(semaphore.availablePermits() > 0 ? true : false).build();
- }
- }
上述代碼模擬停車場有2車位,并且每輛車進入車場后會停留30秒,然后并行模擬3次停車請求,具體執行效果如下:
- [kPoolExecutor-1] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-1,車牌號->10,成功進入停車場 順序->A
- [kPoolExecutor-2] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-2,車牌號->20,成功進入停車場 順序->A
- [kPoolExecutor-3] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-3,車牌號->30,車位不足請耐心等待00,執行順序->B
- [kPoolExecutor-1] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-1,車牌號->10,駛出停車場
- [kPoolExecutor-2] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-2,車牌號->20,駛出停車場
- [kPoolExecutor-4] c.w.c.service.impl.ParkServiceImpl : SingleBlockPoolExecutor-4,車牌號->30,成功進入停車場
可以看到由于通過Semaphore限制了可允許進入的線程數是2個,所以第三次請求會被拒絕,直到前兩次請求通過.release()方法釋放證書后第4次請求才會被允許進入!
后記
本文從應用層面總結了,JVM基本的內存模型以及線程對共享內存操作的原子方式,并著重介紹了線程池、FutrueTask、CountDownLatch、CycliBarrier以及Semaphore這幾種在Java并發編程中經常使用的JUC工具類。





















