













單個GPU無法訓(xùn)練GPT-3,但有了這個,你能調(diào)優(yōu)超參數(shù)了
偉大的科學(xué)成就不能僅靠反復(fù)試驗取得。例如太空計劃中的每一次發(fā)射都是基于數(shù)百年的空氣動力學(xué)、推進(jìn)和天體等基礎(chǔ)研究。同樣,在構(gòu)建大規(guī)模人工智能系統(tǒng)時,基礎(chǔ)研究大大減少了試錯次數(shù),效益明顯。
超參數(shù)(Hyperparameter,HP)調(diào)優(yōu)是深度學(xué)習(xí)的關(guān)鍵,但也是一個昂貴的過程,對于具有數(shù)十億參數(shù)的神經(jīng)網(wǎng)絡(luò)來說更是如此。假如 HP 選擇不當(dāng),會導(dǎo)致模型性能不佳、訓(xùn)練不穩(wěn)定。當(dāng)訓(xùn)練超大型深度學(xué)習(xí)模型時,這些問題更加嚴(yán)重。
最近,有研究 [54] 表明不同的神經(jīng)網(wǎng)絡(luò)參數(shù)化會導(dǎo)致不同的無限寬度限制(infinitewidth limits),他們提出了最大更新參數(shù)化(Maximal Update Parametrization,μP),該方法可以在限制內(nèi)實現(xiàn)「最大」特征學(xué)習(xí)。直觀地說,它確保每一層在訓(xùn)練期間以相同的順序更新,而不管寬度如何。相比之下,雖然標(biāo)準(zhǔn)參數(shù)化 (standard parametrization,SP) 在初始化時保證了激活是單位順序的,但實際上在訓(xùn)練 [54] 時,由于每層學(xué)習(xí)率的不平衡,導(dǎo)致激活在寬模型中爆炸。
來自微軟和 OpenAI 的研究者首次提出了基礎(chǔ)研究如何調(diào)優(yōu)大型神經(jīng)網(wǎng)絡(luò)(這些神經(jīng)網(wǎng)絡(luò)過于龐大而無法多次訓(xùn)練)。他們通過展示特定參數(shù)化保留不同模型大小的最佳超參數(shù)來實現(xiàn)這一點。利用 μP 將 HP 從小型模型遷移到大型模型。也就是說,該研究在大型模型上獲得了接近最優(yōu)的 HP。
論文作者之一、來自微軟的 Greg Yang 表示:「你不能在單個 GPU 上訓(xùn)練 GPT-3,更不用說調(diào)優(yōu)它的超參數(shù)(HP)了。但是由于新的理論進(jìn)步,你可以在單個 GPU 上調(diào)優(yōu) HP ?」
本文的想法非常簡單,論文中引入了一種特殊參數(shù)化 μP,窄和寬的神經(jīng)網(wǎng)絡(luò)共享一組最優(yōu)超參數(shù)。即使寬度→∞也是如此。
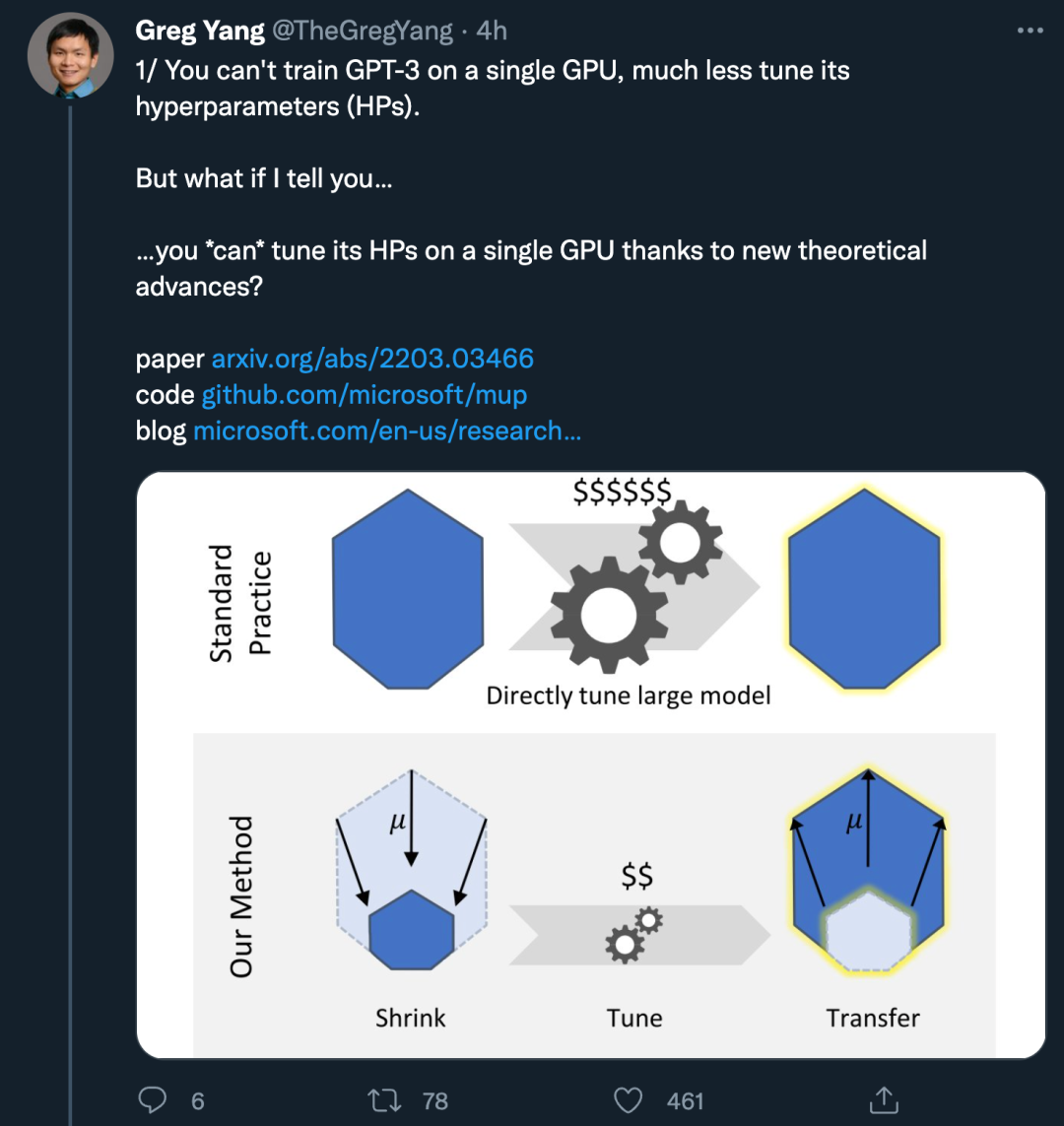
具體而言,該研究證明,在 μP 中,即使模型大小發(fā)生變化,許多最優(yōu)的 HP 仍保持穩(wěn)定。這導(dǎo)致一種新的 HP 調(diào)優(yōu)范式:μTransfer,即在 μP 中對目標(biāo)模型進(jìn)行參數(shù)化,并在較小的模型上間接調(diào)優(yōu) HP,將其零樣本遷移到全尺寸模型上,無需調(diào)優(yōu)后者。該研究在 Transformer 和 ResNet 上驗證 μTransfer,例如,1)通過從 13M 參數(shù)的模型中遷移預(yù)訓(xùn)練 HP,該研究優(yōu)于 BERT-large (350M 參數(shù)),總調(diào)優(yōu)成本相當(dāng)于一次預(yù)訓(xùn)練 BERT-large;2)通過從 40M 參數(shù)遷移,該研究的性能優(yōu)于已公開的 6.7B GPT-3 模型,調(diào)優(yōu)成本僅為總預(yù)訓(xùn)練成本的 7%。

- 論文地址:https://arxiv.org/pdf/2203.03466.pdf
- 項目地址:https://github.com/microsoft/mup
通過大大減少猜測要使用哪些訓(xùn)練超參數(shù)的需要,這種技術(shù)可以加快對巨大神經(jīng)網(wǎng)絡(luò)的研究,例如 GPT-3 和未來可能更大的繼任者。
擴(kuò)展初始化容易,但擴(kuò)展訓(xùn)練難
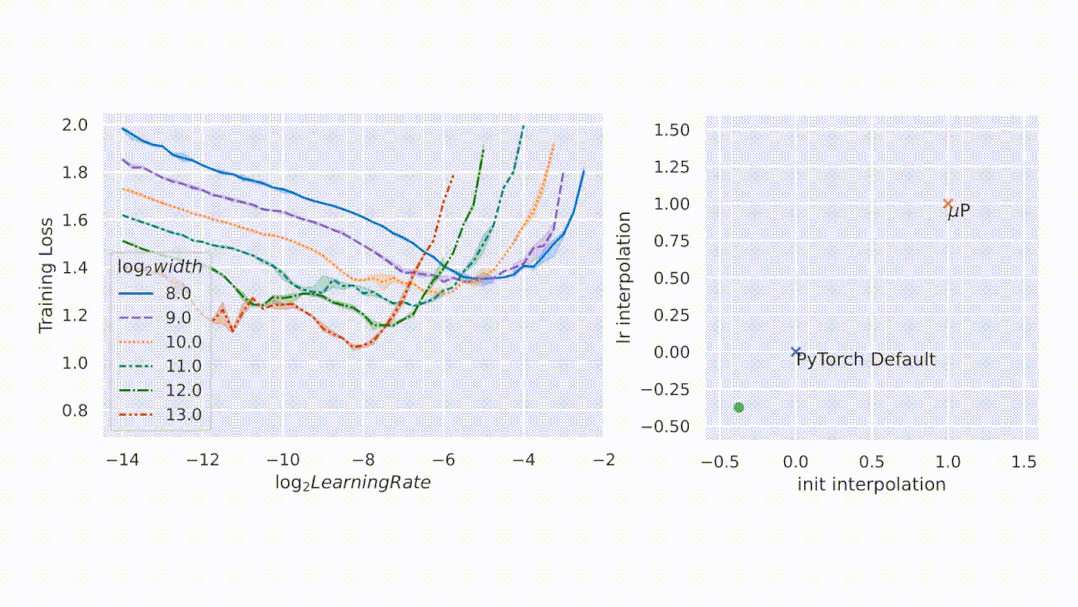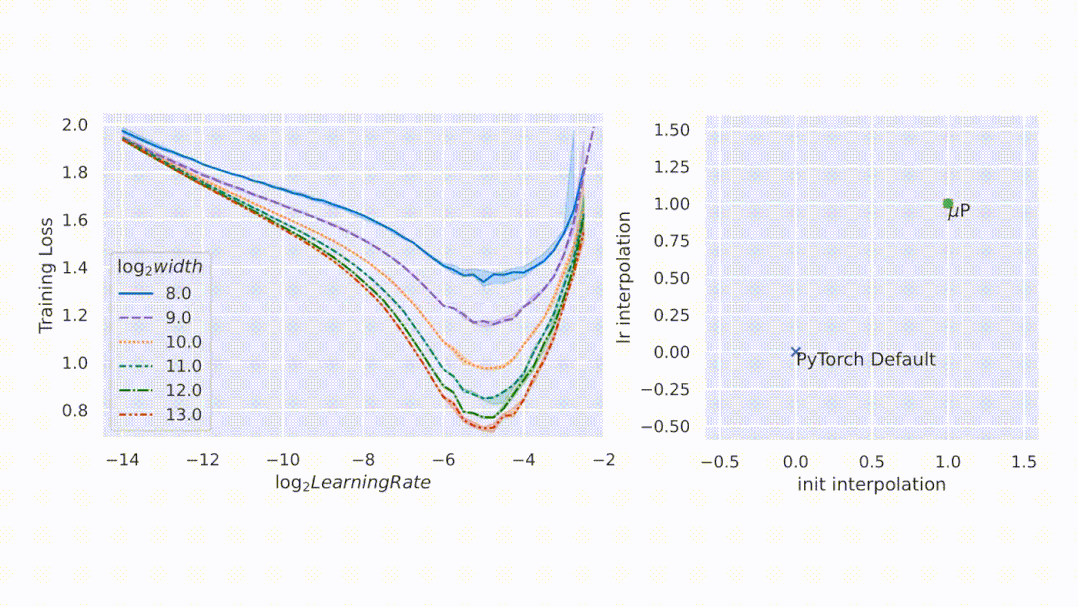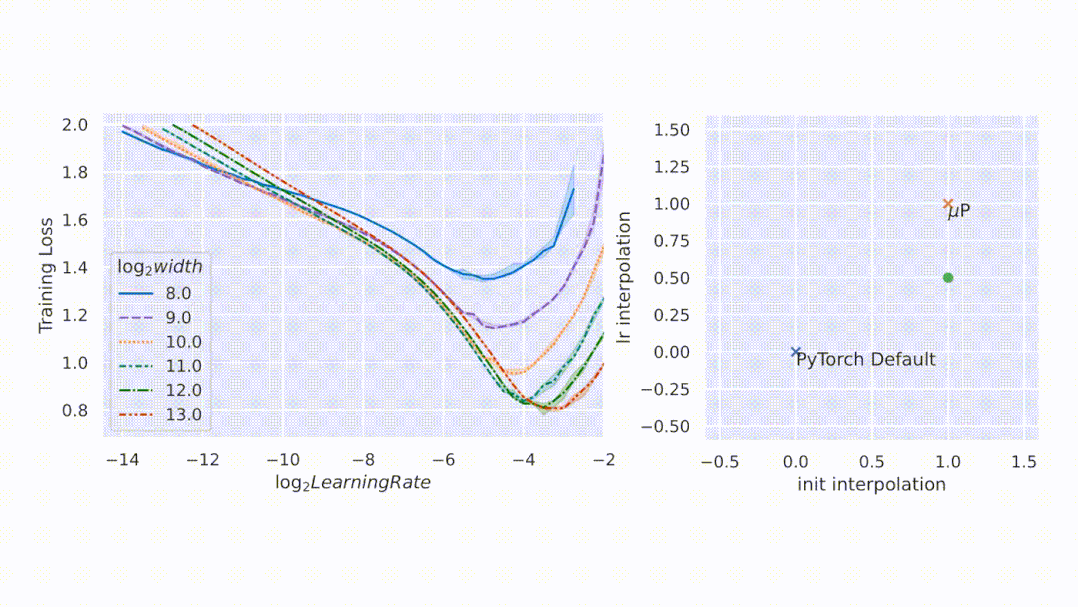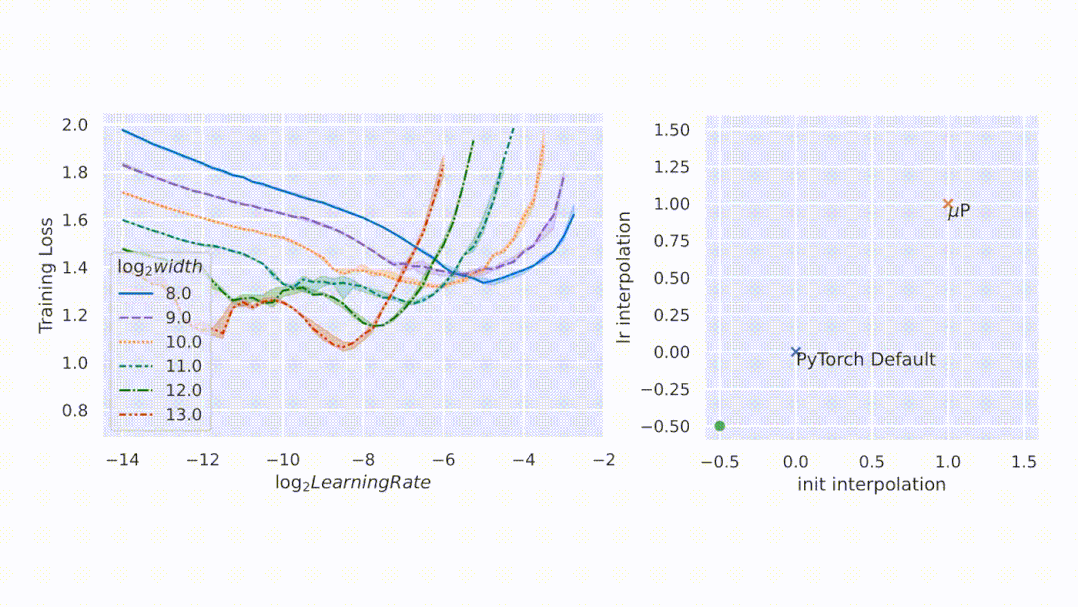
大型神經(jīng)網(wǎng)絡(luò)很難訓(xùn)練,部分原因是不了解其行為如何隨著規(guī)模增加而變化。在深度學(xué)習(xí)的早期工作中,研究者采用啟發(fā)式算法。一般來說,啟發(fā)式方法試圖在模型初始化時保持激活擴(kuò)展一致。然而,隨著訓(xùn)練的開始,這種一致性會在不同的模型寬度處中斷,如圖 1 左側(cè)所示。
與隨機(jī)初始化不同,模型訓(xùn)練期間的行為更難進(jìn)行數(shù)學(xué)分析。該研究用 μP 解決,如圖 1 右側(cè)所示,該圖顯示了網(wǎng)絡(luò)激活擴(kuò)展(activation scales)在模型寬度增加的最初幾個訓(xùn)練步驟中的穩(wěn)定性。
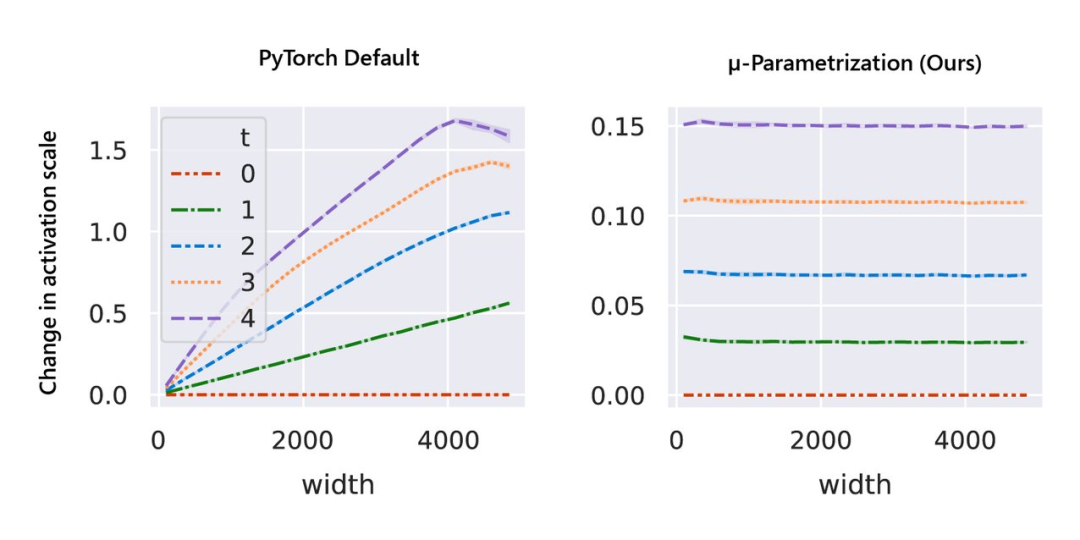
圖 1:在 PyTorch 的默認(rèn)參數(shù)化中,左圖,在經(jīng)過一次 step 訓(xùn)練后,激活擴(kuò)展的寬度會出現(xiàn)差異。但是在右圖的 μP 中,無論訓(xùn)練 step 寬度如何,激活擴(kuò)展都會發(fā)生一致的變化。
事實上,除了在整個訓(xùn)練過程中保持激活擴(kuò)展一致之外,μP 還確保不同且足夠?qū)挼纳窠?jīng)網(wǎng)絡(luò)在訓(xùn)練過程中表現(xiàn)相似,以使它們收斂到一個理想的極限,該研究稱之為特征學(xué)習(xí)極限。
如圖所示,μP 是唯一在寬度上保持最佳學(xué)習(xí)率的參數(shù)化,在寬度為 213 - 8192 的模型中實現(xiàn)了最佳性能,并且對于給定的學(xué)習(xí)率,更寬的模型性能更好——即曲線不相交。
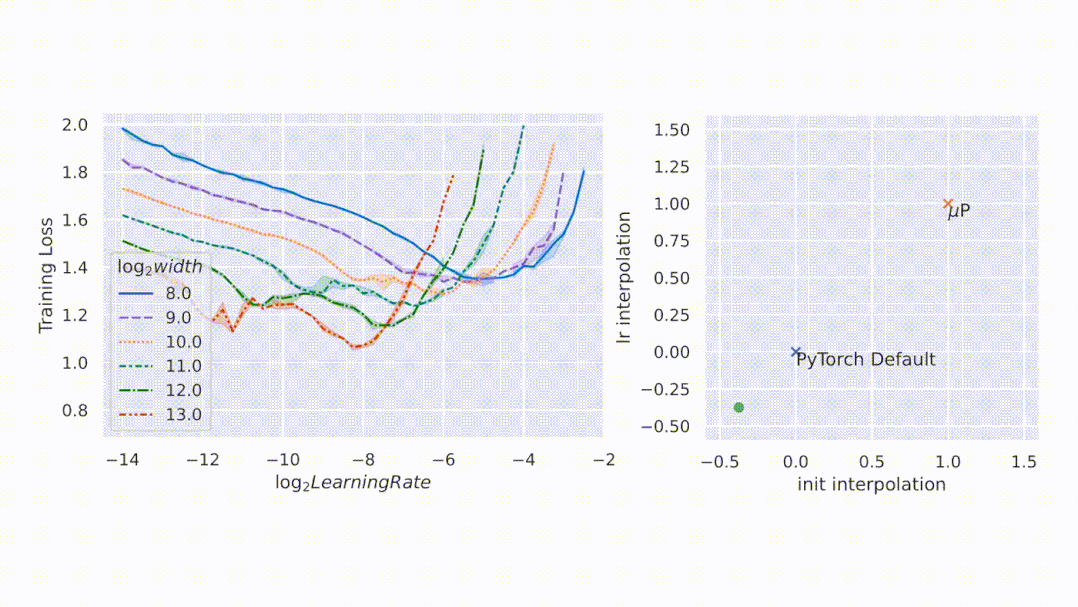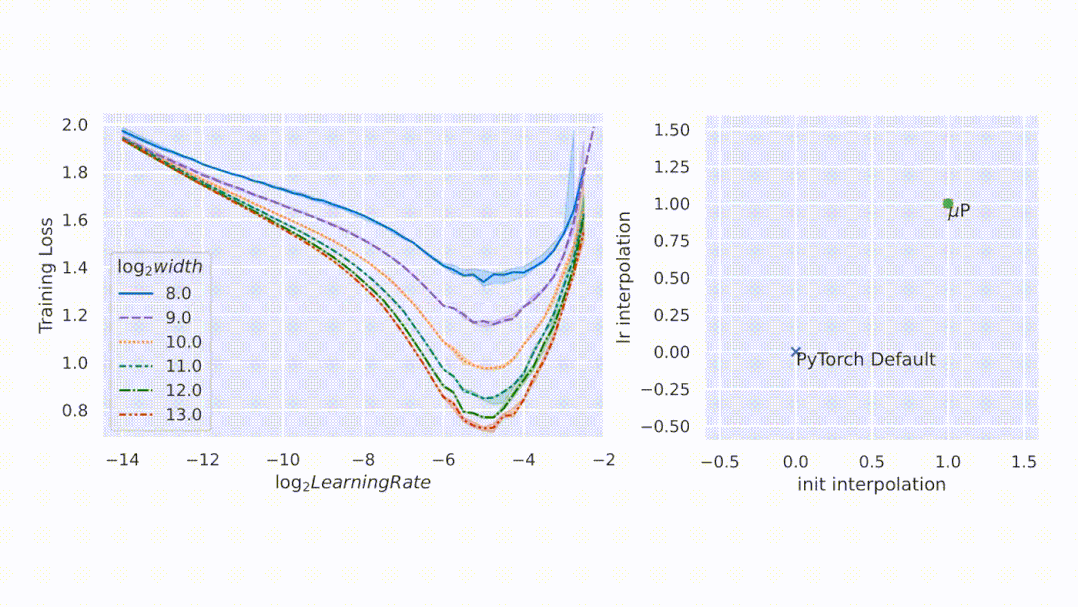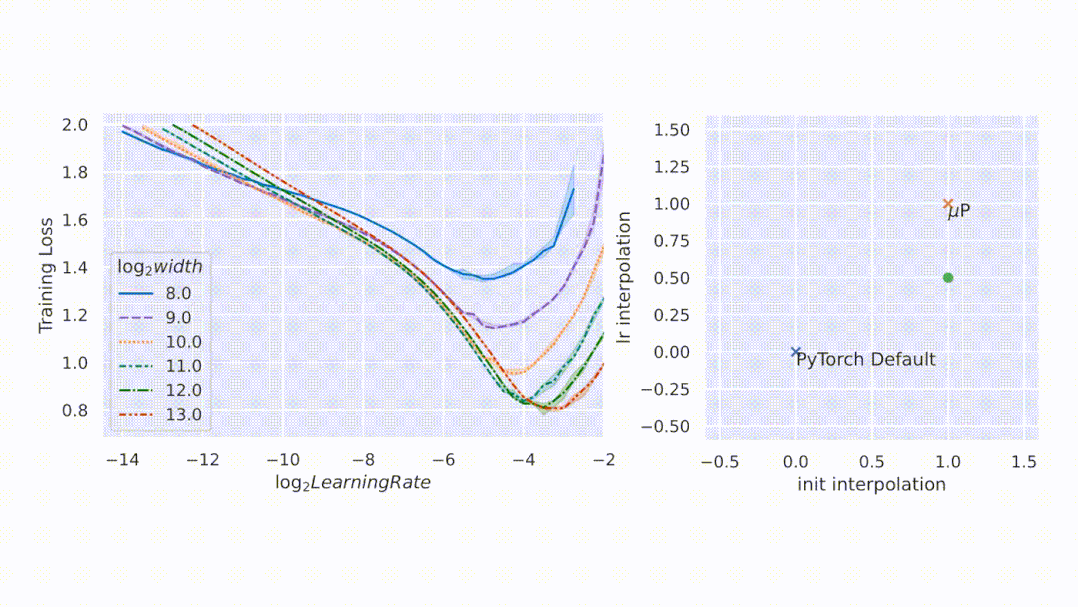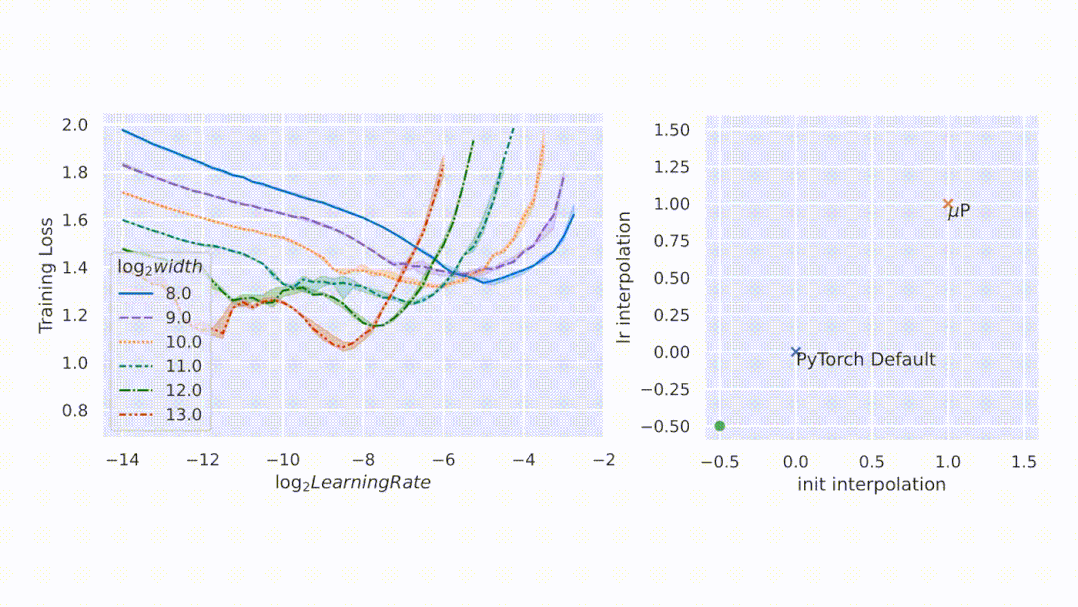
圖2左側(cè),該研究在 CIFAR10 上以不同的學(xué)習(xí)率(沿 x 軸顯示)訓(xùn)練不同寬度(對應(yīng)于不同顏色和圖案的曲線)的多層感知器 (MLP),并沿 y 軸繪制訓(xùn)練損失。右側(cè),參數(shù)化的 2D 平面由以下插值形成:1)PyTorch 默認(rèn)值和 μP(x 軸)之間的初始化擴(kuò)展,以及 2)PyTorch 默認(rèn)值和 μP(y 軸)之間的學(xué)習(xí)率擴(kuò)展。在這個平面上,PyTorch 默認(rèn)用 (0,0) 表示,μP 默認(rèn)用 (1,1) 表示。
基于張量程序(Tensor Programs)的理論基礎(chǔ),μTransfer 自動適用于高級架構(gòu),例如 Transformer 和 ResNet。此外,它還可以同時遷移各種超參數(shù)。
以 Transformer 為例,圖 3 展示了關(guān)鍵超參數(shù)如何在寬度上保持穩(wěn)定。超參數(shù)可以包括學(xué)習(xí)率、學(xué)習(xí)率 schedule、初始化、參數(shù)乘數(shù)等,甚至可以單獨針對每個參數(shù)張量。該研究在最大寬度為 4096 的 Transformer 上驗證了這一點。
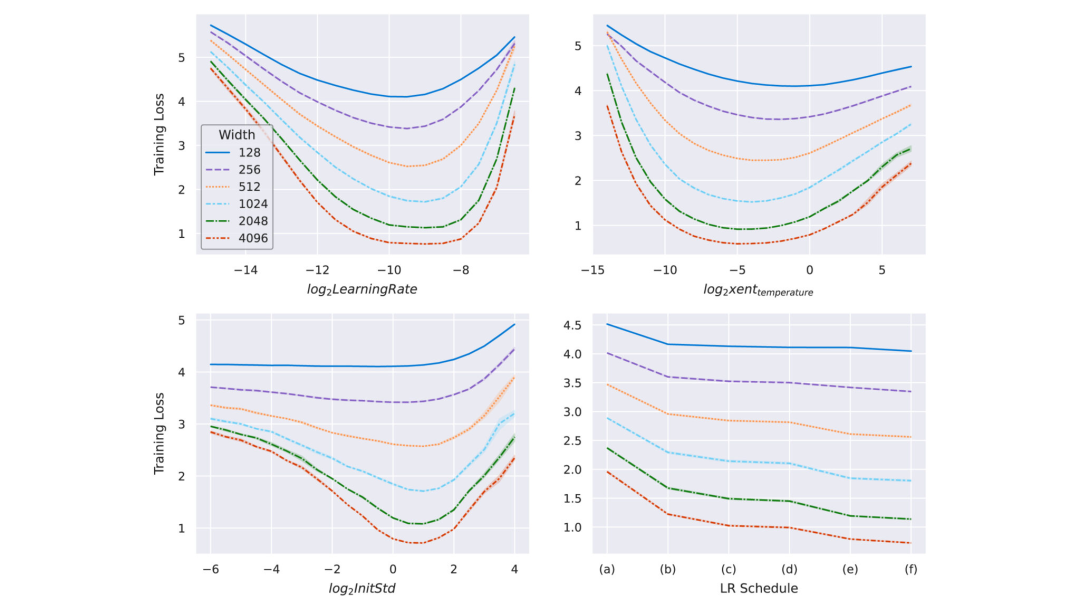
圖 3:在 μP 中參數(shù)化并在 WikiText-2 上訓(xùn)練的不同寬度的 transformer。隨著模型寬度的增加,最優(yōu)學(xué)習(xí)率、交叉熵溫度、初始化規(guī)模和學(xué)習(xí)率方案保持穩(wěn)定。查看網(wǎng)絡(luò)的超參數(shù)有助于預(yù)測更寬網(wǎng)絡(luò)的最佳超參數(shù)。在右下角的圖中,該研究嘗試了如下學(xué)習(xí)率方案:(a) 線性衰減,(b) StepLR @ [5k, 8k],衰減因子為 0.1,(c) StepLR @ [4k, 7k],衰減因子為 0.3,(d) 余弦退火,(e) 常數(shù),(f) 逆平方根衰減。
模型深度的實驗擴(kuò)展
現(xiàn)代神經(jīng)網(wǎng)絡(luò)擴(kuò)展不止涉及寬度一個維度。該研究還探索了如何通過將 μP 與非寬度維度的簡單啟發(fā)式算法相結(jié)合,將其應(yīng)用于現(xiàn)實的訓(xùn)練場景。下圖 4 使用相同的 transformer 設(shè)置來顯示最佳學(xué)習(xí)率如何在合理的非寬度維度范圍內(nèi)保持穩(wěn)定。
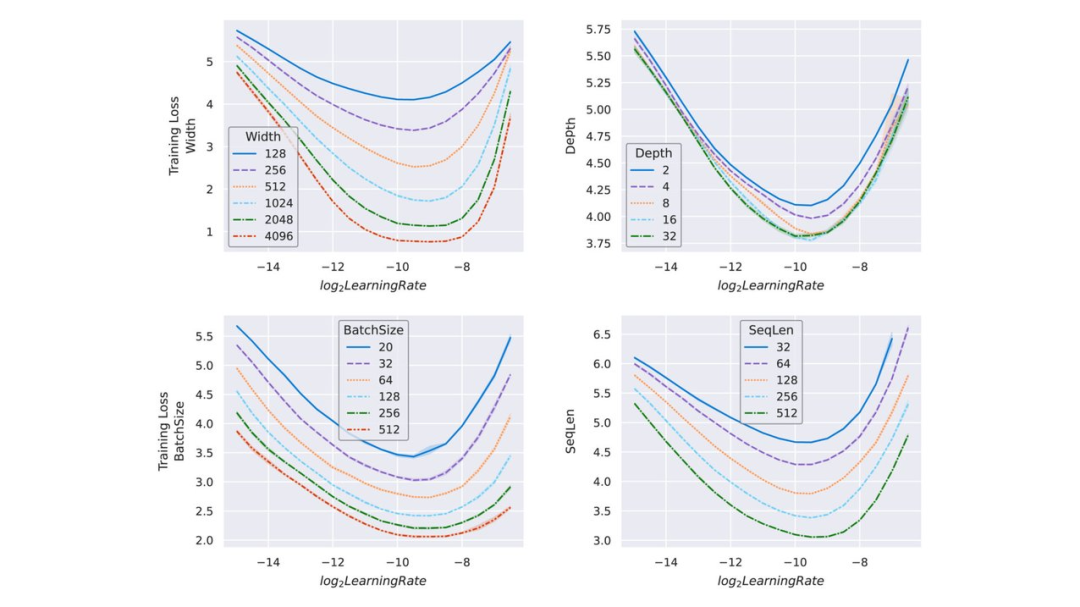
圖 4:在 μP 中參數(shù)化并在 Wikitext-2 上訓(xùn)練的不同大小的 transformer。如圖 3 所示,最優(yōu)學(xué)習(xí)率不僅可以跨寬度遷移,還可在測試范圍內(nèi)實驗性地跨其他擴(kuò)展維度遷移,例如深度、批大小和序列長度。這意味著可以將理論上的跨寬度遷移與實驗驗證的跨其他擴(kuò)展維度遷移相結(jié)合,以獲得能在小模型上間接調(diào)整超參數(shù)并遷移到大模型的 μTransfer。
除了學(xué)習(xí)率,其他超參數(shù)的情況如下圖所示:
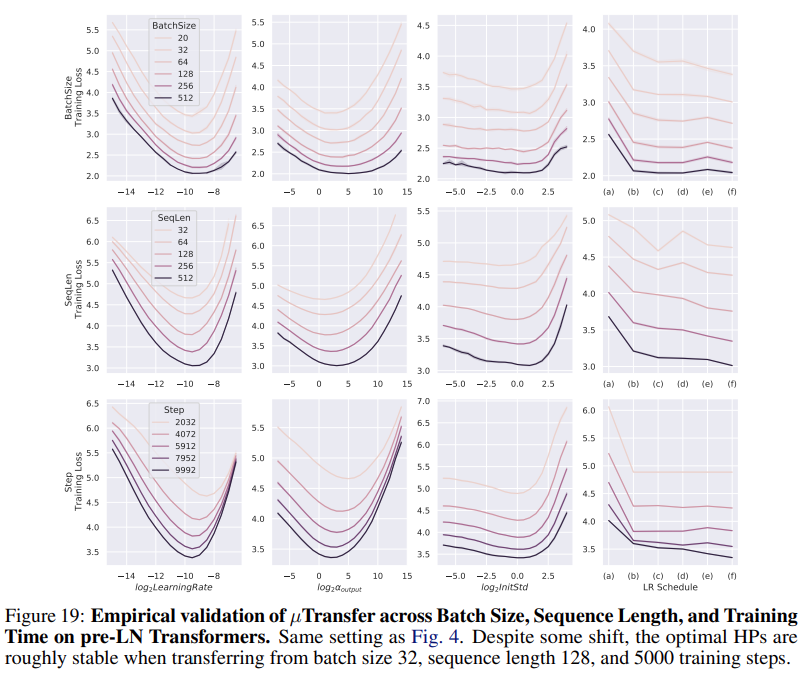
測試 μTransfer
在驗證完單個超參數(shù)的遷移之后,研究者試圖將它們組合到更現(xiàn)實的場景中。下圖 5 對比了兩種情況,一種是 μTransfer 從一個小型 proxy 模型遷移調(diào)整過的超參數(shù),另一種是直接調(diào)整大型目標(biāo)模型。在這兩種情況下,調(diào)整都是通過隨機(jī)搜索完成的。
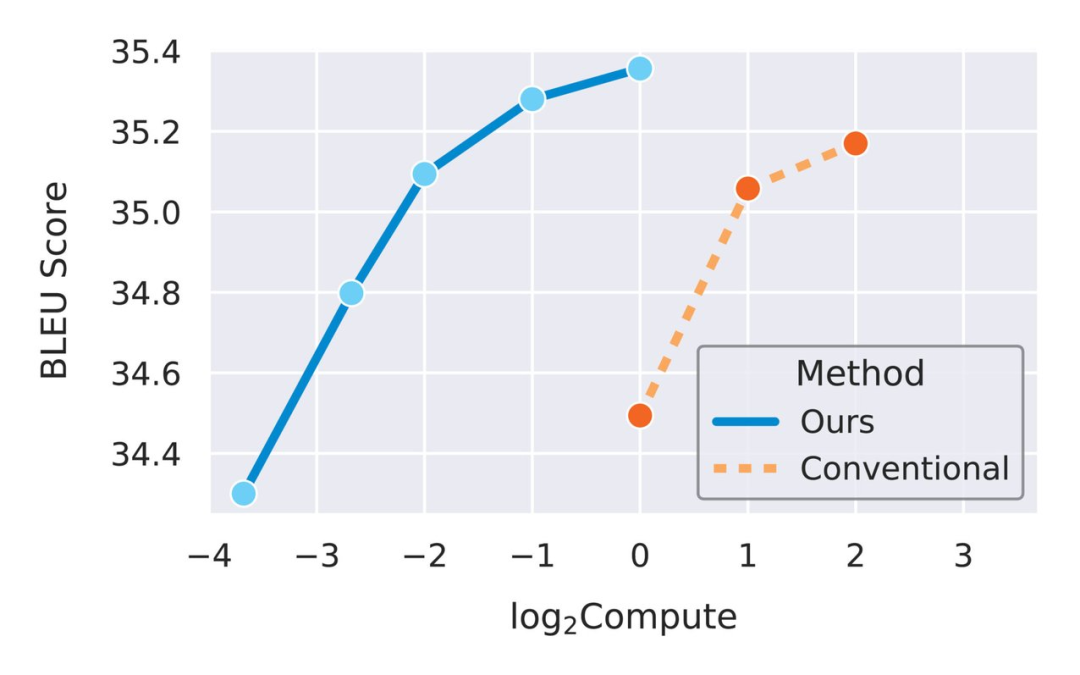
圖 5:μTransfer 大約將計算效率提高了一個數(shù)量級。
由于 proxy 模型即使很小也能有意義地預(yù)測最佳超參數(shù)(如圖 3、圖 4 所示),因此隨著該研究用數(shù)十億個參數(shù)訓(xùn)練更大的目標(biāo)模型,研究者預(yù)計性能差距會擴(kuò)大。
未來方向:μP + GPT-3
在這項工作之前,模型越大,調(diào)優(yōu)成本越高,預(yù)計調(diào)優(yōu)效果就越差。研究者預(yù)計 μTransfer 將給最大的模型帶來最大的增益,因此該研究與 OpenAI 合作,在 GPT-3 上評估 μTransfer。
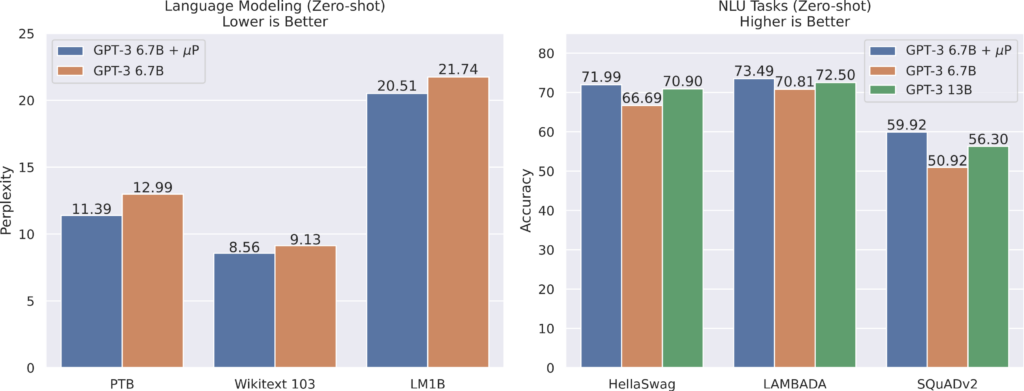
使用 μP 中的相對注意力對 GPT-3 的一個版本進(jìn)行參數(shù)化后,該研究調(diào)整了一個具有 4000 萬個參數(shù)的小型 proxy 模型,然后按照 μTransfer 的方法將最佳超參數(shù)組合復(fù)制到 GPT-3 的 67 億參數(shù)變體中。在此調(diào)整階段使用的總計算量僅為 67 億模型預(yù)訓(xùn)練使用計算量的 7%。如下圖 6 所示,這個使用 μTransfer 的模型優(yōu)于 GPT-3 論文中相同大小的模型(絕對注意力),它的性能與 GPT-3 論文中參數(shù)數(shù)量翻倍的模型(絕對注意力)相當(dāng)。
理論意義
μP 給出了一個擴(kuò)展規(guī)則,該規(guī)則在訓(xùn)練損失方面唯一地保留了跨不同寬度模型的最佳超參數(shù)組合。相反,其他擴(kuò)展規(guī)則(如 PyTorch 中的默認(rèn)初始化或 NTK 參數(shù)化),隨著網(wǎng)絡(luò)變得越來越寬,超參數(shù)空間中的最優(yōu)值卻越來越遠(yuǎn)。研究者認(rèn)為:實際使用特征學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)時,為了獲得適用的見解,μP 的特征學(xué)習(xí)限制會比 NTK 限制更自然。因此,過參數(shù)化神經(jīng)網(wǎng)絡(luò)應(yīng)該在大型寬度設(shè)置中重現(xiàn) μP 的特征學(xué)習(xí)限制。
過去幾年開發(fā)的張量程序 (TP) 理論使這項進(jìn)展成為可能。TP 理論使研究人員能夠計算任何通用計算圖在其矩陣維數(shù)變大時的極限。TP 方法產(chǎn)生了基本的理論結(jié)果,例如神經(jīng)網(wǎng)絡(luò) - 高斯過程對應(yīng)的架構(gòu)普遍性和動態(tài)二分定理,并通過推導(dǎo) μP 和特征學(xué)習(xí)限制形成了 μTransfer。研究者認(rèn)為將 TP 理論擴(kuò)展到深度、批大小等擴(kuò)展維度是大型模型在寬度之外可靠擴(kuò)展的關(guān)鍵。
研究者表示:基礎(chǔ)研究是對反復(fù)試錯的一種高成本效益補充,該研究將繼續(xù)推導(dǎo)出更具原則性的大規(guī)模機(jī)器學(xué)習(xí)方法。

























