擴(kuò)展我們的分析處理服務(wù)(Smartly.io):使用 Citus 對 PostgreSQL 數(shù)據(jù)庫進(jìn)行分片
在線廣告商正在根據(jù)績效數(shù)據(jù)做出越來越多的決策。無論是選擇要投資的受眾或創(chuàng)意,還是啟用廣告活動(dòng)預(yù)算的算法優(yōu)化,決策越來越依賴于隨時(shí)可用的數(shù)據(jù)。我們的開發(fā)團(tuán)隊(duì)構(gòu)建了強(qiáng)大的工具來幫助我們的客戶分析性能數(shù)據(jù)并做出更好的決策。
我們的解決方案由高度可定制的報(bào)告組成,包括由我們自己的極其靈活的查詢語言提供支持的下鉆表和圖表。支持查詢語言的數(shù)據(jù)服務(wù)處理數(shù) TB 的數(shù)據(jù)。除了作為我們面向用戶的分析工具的后端之外,它還為我們所有的自動(dòng)優(yōu)化功能和我們的一些內(nèi)部 BI 系統(tǒng)提供支持。在這篇博文中,我將向您介紹我們?nèi)绾瓮ㄟ^對后端系統(tǒng)使用的數(shù)據(jù)庫進(jìn)行分片來解決擴(kuò)展問題。
海量數(shù)據(jù)庫等于擴(kuò)展麻煩
我們的分析數(shù)據(jù)處理服務(wù),稱為 Distillery,使用 PostgreSQL 數(shù)據(jù)庫。該服務(wù)將 JSON 格式的查詢安全地轉(zhuǎn)換為最終在數(shù)據(jù)庫級(jí)別運(yùn)行的 SQL 查詢。大多數(shù)數(shù)據(jù)處理都發(fā)生在數(shù)據(jù)庫中,因此 Distillery 后端主要將我們自己的查詢語言轉(zhuǎn)換為 SQL 查詢。原始的 API 查詢很復(fù)雜,這使得一些生成的 SQL 查詢變得復(fù)雜,并使得它們對數(shù)據(jù)庫級(jí)別的要求很高。因此,當(dāng)我們在報(bào)告系統(tǒng)的開發(fā)過程中遇到擴(kuò)展問題時(shí),我們并不感到驚訝。
過去,我們垂直擴(kuò)展了我們的主副本數(shù)據(jù)庫架構(gòu),但后來很明顯我們已經(jīng)達(dá)到了這種方法的極限。我們的數(shù)據(jù)庫在運(yùn)行三年中積累了近 5TB 的數(shù)據(jù),并且變得無法管理。大尺寸使得更新繁重的應(yīng)用程序?qū)懭胨俣茸兟S護(hù)任務(wù)難以執(zhí)行。最后,最大的問題是我們的數(shù)據(jù)中心無法提供更大的服務(wù)器。
解決方案:使用 Citus 分片 PostgreSQL 數(shù)據(jù)庫
當(dāng)垂直擴(kuò)展失敗時(shí),我們不得不開始水平擴(kuò)展我們的報(bào)告數(shù)據(jù)庫。這意味著我們需要在多個(gè)數(shù)據(jù)庫服務(wù)器之間拆分?jǐn)?shù)據(jù)和處理。我們還必須縮小包含每個(gè)單獨(dú)數(shù)據(jù)庫實(shí)例中統(tǒng)計(jì)數(shù)據(jù)的龐大數(shù)據(jù)庫表。
這種將數(shù)據(jù)庫數(shù)據(jù)切片成更小單元的方法稱為數(shù)據(jù)庫分片。我們的團(tuán)隊(duì)決定使用 PostgreSQL Citus 插件來處理分片。這不是唯一的選擇 — 我們考慮使用自定義應(yīng)用程序級(jí)分片,但決定使用 Citus 插件,因?yàn)椋?/p>
- 我們有大量復(fù)雜的查詢,需要同時(shí)使用多個(gè)不同的分片。Citus 插件自動(dòng)處理這些復(fù)雜的查詢并在分片之間分配處理。
- 它還廣泛支持我們運(yùn)行復(fù)雜報(bào)告查詢所需的 PostgreSQL 功能。
- 該擴(kuò)展使分片管理相對容易,因此我們不必花費(fèi)太多精力來管理單獨(dú)數(shù)據(jù)庫實(shí)例中的分片表。
Citus 基于 coordinator(協(xié)調(diào)器) 和 worker(工作器) PostgreSQL 數(shù)據(jù)庫實(shí)例。worker 持有數(shù)據(jù)庫表分片,coordinator 計(jì)劃 SQL 查詢,以便它們可以跨 worker 之間的多個(gè)分片表運(yùn)行。這允許將大型表分布在多個(gè)服務(wù)器上,并分布到更小、更易于管理的數(shù)據(jù)庫表中。寫入較小的表更有效,因?yàn)閿?shù)據(jù)庫索引維護(hù)成本降低。此外,寫入負(fù)載是并行化的,并在數(shù)據(jù)庫實(shí)例之間共享。Citus 解決了我們最大的兩個(gè)痛點(diǎn):寫入效率低下和垂直擴(kuò)展即將結(jié)束。
Citus 的數(shù)據(jù)庫分片帶來了額外的好處,因?yàn)樾录軜?gòu)加速了我們的報(bào)告查詢。我們的一些查詢命中了多個(gè) worker 實(shí)例和分片,Citus 擴(kuò)展可以對其進(jìn)行優(yōu)化以在不同的數(shù)據(jù)庫實(shí)例中并行運(yùn)行它們。由于較小的表索引和更多資源可用于在單獨(dú)的 worker 中進(jìn)行查詢處理,因此僅針對單個(gè) worker 分片的查詢也會(huì)加快速度。
將大型數(shù)據(jù)庫和復(fù)雜的報(bào)告查詢遷移到這種類型的分片數(shù)據(jù)庫架構(gòu)中絕非易事。它涉及仔細(xì)的準(zhǔn)備和計(jì)劃,我們將在接下來進(jìn)行研究。
遷移到新數(shù)據(jù)庫
過去,我們通過舊的 PHP 單體運(yùn)行報(bào)告查詢。早在數(shù)據(jù)庫擴(kuò)展問題出現(xiàn)之前,我們就開始使用 Ruby on Rails 構(gòu)建更新的報(bào)告后端。在決定只在新后端處理 SQL 查詢遷移后,我們開始逐步淘汰舊后端。這使我們能夠?qū)iT針對 Citus 優(yōu)化新的報(bào)告查詢。它使從應(yīng)用程序級(jí)別的遷移更容易,因?yàn)槲覀冎恍柽w移此服務(wù)即可與 Citus 分片 PostgreSQL 一起使用。
分片數(shù)據(jù)庫對數(shù)據(jù)庫模式有一定的要求。模式必須具有一個(gè)作為分片條件的值。分片邏輯使用此值來區(qū)分?jǐn)?shù)據(jù)位于哪個(gè)分片上。在 Citus-PostgreSQL 中,分片是使用表主鍵控制的。此復(fù)合主鍵包含一個(gè)或多個(gè)列,其中第一個(gè)定義的列用作分片值:
ALTER TABLE ad_stats ADD PRIMARY KEY (account_id, ad_id, date);
SELECT create_distributed_table('ad_stats', 'account_id'); -- Defines sharding for Citus cluster
這里 account ID 列用作分片鍵,這意味著我們正在根據(jù)我們的客戶帳戶分配數(shù)據(jù)(單個(gè)客戶也可以有多個(gè)帳戶)。這意味著單個(gè)帳戶的數(shù)據(jù)位于單個(gè)表分片中。我們必須確保所有主鍵都采用這種格式,并且表中包含帳戶 ID 信息。我們還必須更改一些外鍵和唯一性約束,因?yàn)樗鼈冞€必須包含分片列。幸運(yùn)的是,所有這些更改都可以安全地應(yīng)用于正在運(yùn)行的生產(chǎn)數(shù)據(jù)庫,而沒有任何性能或數(shù)據(jù)完整性問題,盡管我們不得不進(jìn)行一些更廣泛的數(shù)據(jù)庫索引重建。
第二步是讓我們的報(bào)表后端生成的 SQL 查詢與分片數(shù)據(jù)庫兼容。首先,查詢必須包含 SQL WHERE 子句中的分片值。這意味著,例如,過濾器必須采用以下形式:
SELECT * FROM campaigns WHERE account_id = 'xxx' AND name = 'yyy'
如果我們沒有 account_id 條件,Citus 分布式查詢計(jì)劃器將沒有信息需要從哪個(gè)分片中找到相關(guān)行。從所有可能的分片中讀取不會(huì)像從單個(gè)分片中讀取那樣有效。
此外,Citus 對您可以在分片表之間執(zhí)行的 JOIN 類型有一定的限制。通常 JOIN 要求分片列出現(xiàn)在 JOIN 條件中。例如,這將不起作用:
SELECT *
FROM
campaigns
LEFT JOIN ads ON campaigns.id = ads.campaign_id
WHERE
campaigns.account_id = 'xxx'
這將導(dǎo)致錯(cuò)誤:
ERROR: cannot run outer join query if join is not on the partition column&
這意味著 SQL 外連接需要 Citus 無法從查詢中確定的表分片之間的一對一匹配。因此,查詢需要在 JOIN 條件中包含分片列,Citus 能夠從中檢測到 ads 表連接的范圍在一個(gè)分片內(nèi):
SELECT *
FROM
campaigns
LEFT JOIN ads ON campaigns.account_id = ads.account_id -- Use sharding column
AND campaigns.id = ads.campaign_id
WHERE
campaigns.account_id = 'xxx'
我們進(jìn)行了各種其他 SQL 查詢優(yōu)化,使 Citus 查詢規(guī)劃器能夠有效地運(yùn)行我們復(fù)雜的統(tǒng)計(jì)報(bào)告查詢。例如,我們使用通用表表達(dá)式 (CTE) 組織查詢,這允許 Citus 查詢計(jì)劃器為涉及同時(shí)讀取多個(gè)分片的繁重查詢選擇最佳計(jì)劃。這些針對多個(gè)帳戶的查詢也在 Citus worker 集群中高度并行化,從而提高數(shù)據(jù)處理效率。此外,我們還為 Citus 擴(kuò)展做出了貢獻(xiàn),增加了對 PostgreSQL JSON(B) 聚合的支持,我們的報(bào)告查詢將其用于某些數(shù)據(jù)預(yù)聚合步驟。您可以在 Github 中查看PR。
PR:https://github.com/citusdata/citus/pull/2015
運(yùn)行中的新數(shù)據(jù)庫系統(tǒng)
我們的數(shù)據(jù)庫系統(tǒng)完全從單一主副本配置遷移到 coordinator + 4 個(gè) worker 服務(wù)器,每個(gè)服務(wù)器都復(fù)制以實(shí)現(xiàn)高可用性。這意味著我們包含 5TB 數(shù)據(jù)的舊數(shù)據(jù)庫被分割成一個(gè)集群,其中每個(gè)數(shù)據(jù)庫服務(wù)器保存大約 1TB 數(shù)據(jù)。Citus 允許我們相當(dāng)容易地添加更多的 worker 服務(wù)器,以便在公司繼續(xù)發(fā)展時(shí)將其進(jìn)一步分割。我們還可以將擁有大量統(tǒng)計(jì)數(shù)據(jù)的最苛刻的客戶隔離到他們自己的數(shù)據(jù)庫服務(wù)器上。
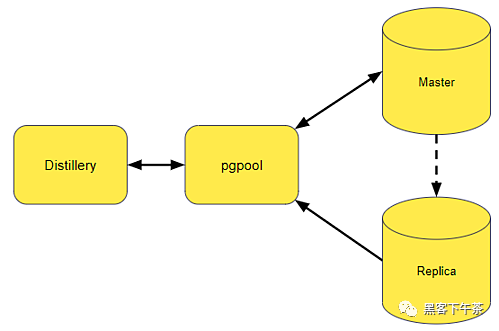
遷移前的數(shù)據(jù)庫架構(gòu)。
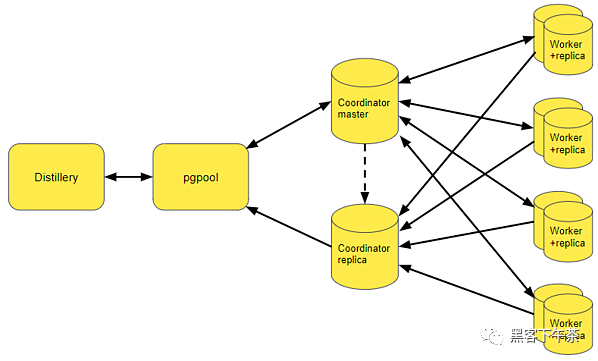
遷移后的數(shù)據(jù)庫架構(gòu)。
上圖描繪了遷移前后的數(shù)據(jù)庫架構(gòu)。與之前擁有 2 臺(tái)大型數(shù)據(jù)庫服務(wù)器的狀態(tài)相比,我們現(xiàn)在總共擁有 10 臺(tái)數(shù)據(jù)庫服務(wù)器。這些較小的數(shù)據(jù)庫實(shí)例更易于管理,因?yàn)榇蠖鄶?shù)數(shù)據(jù)存在于單獨(dú)的數(shù)據(jù)庫工作服務(wù)器中。協(xié)調(diào)器持有較少量的數(shù)據(jù),例如一些元數(shù)據(jù)和對分片不敏感的數(shù)據(jù)。第二張圖還顯示了我們用來確保在一個(gè)數(shù)據(jù)庫實(shí)例出現(xiàn)故障時(shí)快速恢復(fù)的數(shù)據(jù)庫副本。這種從 primary master 服務(wù)器到副本服務(wù)器的故障轉(zhuǎn)移由 pgpool 組件處理。副本還共享來自主服務(wù)器的一些讀取負(fù)載。
最后,我們在數(shù)據(jù)處理方面要求最高的數(shù)據(jù)透視表報(bào)告查詢從新數(shù)據(jù)庫系統(tǒng)中獲得了 2-10 倍的性能提升。此功能生成的數(shù)據(jù)庫查詢非常復(fù)雜,因?yàn)槲覀冊试S用戶自由定義數(shù)據(jù)的分組、過濾和聚合方式。它還允許查詢跨分片自由運(yùn)行,因?yàn)橛脩艨梢远x任何帳戶組合。Citus 分片數(shù)據(jù)庫的好處真正體現(xiàn)在這些特定的查詢中。數(shù)據(jù)庫遷移非常必要,因?yàn)槲覀兊呐f數(shù)據(jù)庫基礎(chǔ)架構(gòu)幾乎被它生成的復(fù)雜查詢所淹沒。
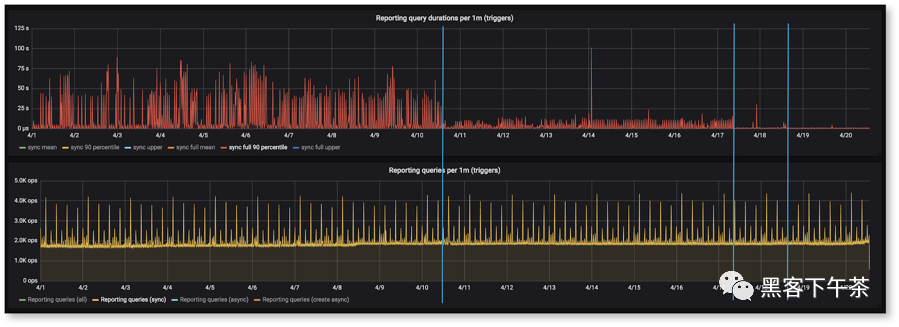
該圖顯示了在數(shù)據(jù)庫遷移項(xiàng)目期間,某些類型的查詢獲得性能提升的 90 個(gè)百分點(diǎn)的持續(xù)時(shí)間。