













SFU、阿里提出通用QuadTree Attention,復雜度變線性,性能更強
Transformer模型能夠捕捉長距離依賴和全局信息,在引入計算機視覺任務后,大多都取得了顯著的性能提升。
但Transformer的缺陷始終還是繞不過:時間和空間復雜度太高,都是輸入序列長度的二次方。
通常情況下,一個輸入圖像被劃分為patch,然后flatten這些patch為一個token序列送入Transformer,序列越長,復雜度也就越高。
所以,很多視覺任務中為了利用上Transformer,選擇將其應用于低分辨率或將注意力機制限制在圖像局部。
但在高分辨率上應用Transformer能夠帶來更廣闊的應用前景和性能提升,因此,許多工作都在研究設計有效的Transformer以降低計算的復雜性。
有學者提出線性近似Transformer,用線性方法近似于標準的Transformer。然而,實驗結果顯示這些線性Transformer在視覺任務中的性能是比較差的。為了降低計算成本,PVT使用降采樣的key和value,使得模型捕捉像素級細節的能力有所下降。相比之下,Swin變換器則是限制了全局注意力的交互信息來減少計算量
與以往的工作方向不同,來自西蒙菲莎大學和阿里巴巴AI Lab的研究人員提出了一個全新的注意力機制QuadTree attention,由粗到細地建立注意力機制,能夠同時包含全局交互和細粒度的信息,將時間復雜度降低為線性,論文已被ICLR 2022接收。

論文地址:https://arxiv.org/abs/2201.02767
代碼地址:https://github.com/Tangshitao/QuadTreeAttention
當我們看一張圖片的時候,可以發現,大多數圖像區域都是不相關的,所以我們可以建立一個token金字塔,以從粗到細的方式計算注意力。通過這種方式,如果對應的粗級區域不相關,那么我們也可以快速跳過精細級別的不相關區域。

例如,第一層計算了圖像A中的藍色區域的注意力,即計算圖像A中的藍色patch與圖像B中的所有patch的注意力,并選擇前K個patch,把這些patch也被標記為藍色,代表他們是相關的區域。
在第二層,對于圖像A中的第一層中藍色patch的四個子patch,我們只計算它們與對應第一層圖像B中top K個patch的子patch的注意力,其他所有其他陰影的子patch都被跳過以減少計算量。我們將圖像A中的兩個patch用黃色和綠色表示,它們在圖像B中對應的前K個patch也用同樣的顏色突出顯示。
整個過程在第三層迭代進行,通過這種方式,既能獲得精細的注意力,還能夠保留長距離的依賴連接。
最重要的是,在整個過程中只需要計算少量的注意力。因此,這種方法具有更低的內存消耗和計算成本。
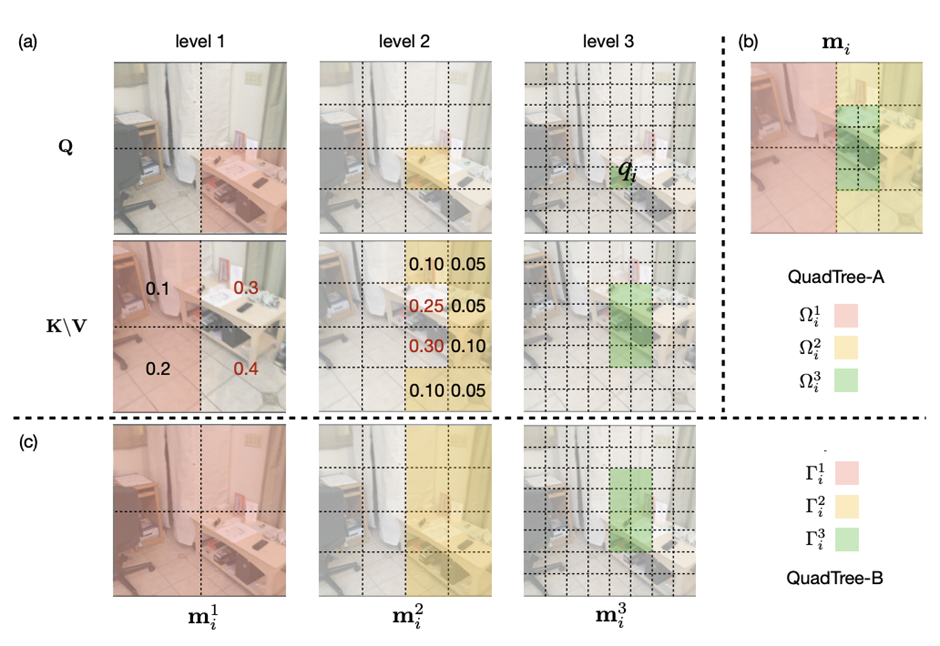
在實現上,研究人員采用了Quadtree 這種數據結構去構建注意力機制。
與傳統注意力機制一樣,首先將embeddings映射Q,K,V。然后用kernel size為2x2的pooling層或者卷積層將他們降采樣若干次構建token金字塔。
從最粗的那層開始,每一層只選K個最高注意力分數的patch參與下一層的計算。根據計算方式的不同設計了2種機制:QuadTree-A與QuadTree-B。
在QuadTree-B方法中,對于最粗的那層,只需根據注意力公式計算。
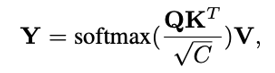
對于其余幾層,則是從上一層選k個注意力分數最高的patch,然后計算message passing。
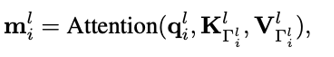
最后把每層的信息結合起來即可,其中w_i是第i層可學參數。
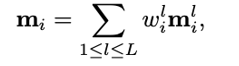
實驗結果
尋找不同圖像之間的特征對應關系(feature corresponding)是一個經典三維計算機視覺任務,通常的評估方式就是對應點的相機姿態估計準確率。
研究人員使用最近提出的SOTA框架LoFTR,其中包括一個基于CNN的特征提取器和一個基于Transformer的匹配器。
為了驗證QuadTree Transformer的效果,研究人員將LoFTR中的線性變換器替換為QuadTree。此外,文章內還實現了一個新版本的LoFTR與spatial reduction(SR)注意力進行對比。
研究人員在包含1513個場景的ScanNet上進行了實驗。
對于QuadTree Transformer的參數,使用三層金字塔,最粗的分辨率為15×20個像素。在最精細的級別的參數K設置為8,而在較粗的級別上則為兩倍。對于SR注意力,將value和key tokens平均池化到8×8的大小以保證和QuadTree Attention相似的內存消耗和flops。
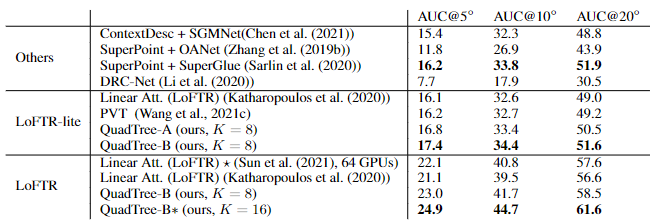
在(5?,10?,20?)下相機姿勢誤差的AUC實驗結果中可以看到,SR注意力與線性Transformer取得了類似的結果。相比之下,QuadTreeA 和QuadTreeB在很大程度上超過了線性Transformer和SR注意力,并且Quadtree-B 總體上比Quadtree-A表現得更好。
為了進一步提高結果,研究人員還訓練了一個K=16的模型,可以看到模型的性能得到進一步提升。
在雙目視差估計(stereo matching)任務中,目的是在兩幅圖像之間找到對應的線上的像素。最近的工作STTR將Transformer應用于epipolar line之間的特征點,并取得了SOTA的性能。
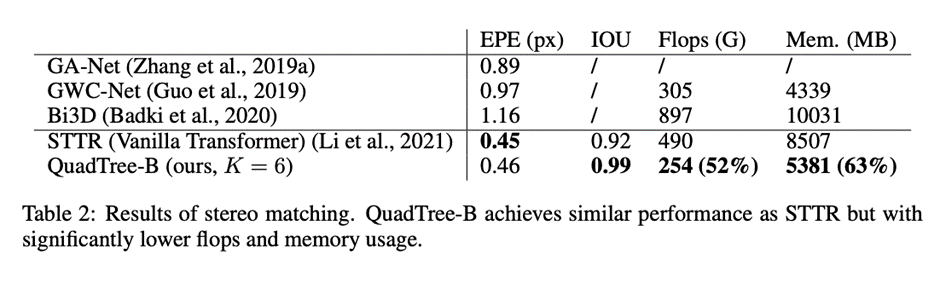
在將STTR中的標準Transformer替換為QuadTree Transformer后,在Scene Flow FlyingThings3D合成數據集上進行實驗,該數據集包含25,466張分辨率為960×540的圖像。
研究人員建立了四層的金字塔來評估QuadTree Attention,實驗結果可以看到非遮擋區域的EPE(End-Point-Error)和遮擋區域的IOU(Intersection-over- Union),表中還包括計算復雜性和內存使用量也被報告。
與基于標準Transformer的STTR相比,QuadTree Transformer實現了類似的EPE(0.45 px vs 0.46 px)和更高的閉塞估計IOU,但計算和內存成本低得多,只有52%的FLOPs和63%的內存消耗。
研究人員還在基本的self-attention任務中測試了QuadTree Transformer的性能。
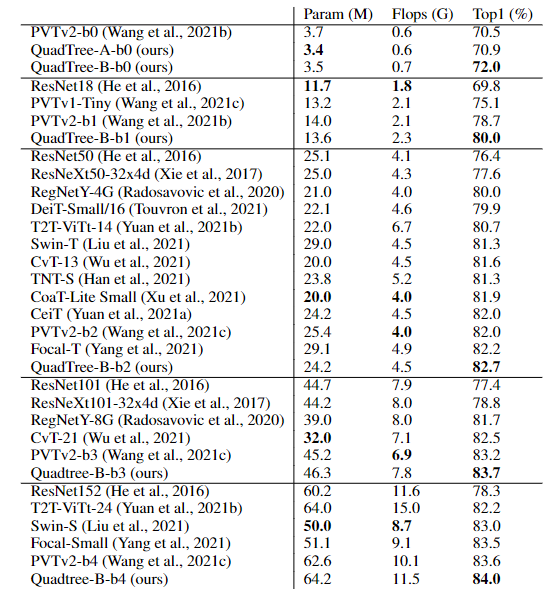
首先在ImageNet上的圖像分類任務實驗結果中可以看到,基于PVTv2的模型,將其中的spatial reduction attention替換成quadtree attention,就能夠在ImageNet上實現了84.0%的top 1準確度,在不同大小的模型上比PVTv2高0.4-1.5個百分點。
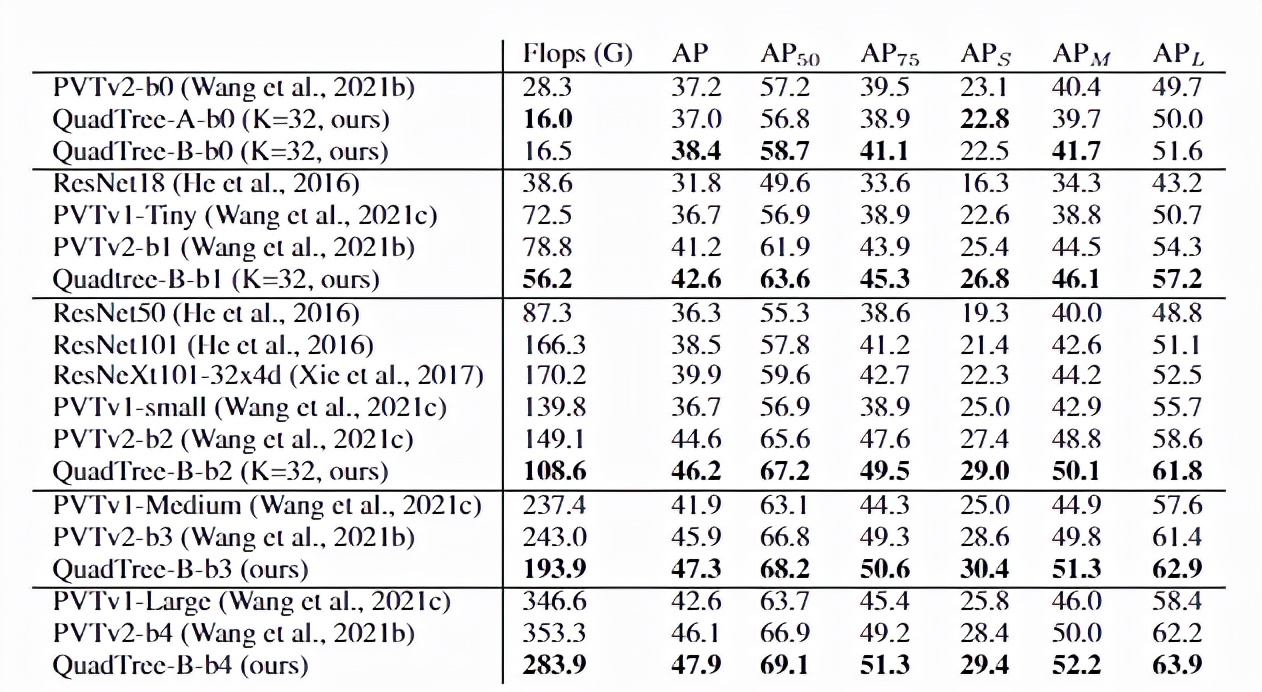
在COCO目標檢測數據集的實驗結果中可以看到,對于QuadTree Attention來說,一個小的K就足夠捕捉粗到細的信息了。因此,在使用高分辨率的圖像時,可以減少更多計算量。
并且QuadTree-B實現了更高的性能,同時比PVTv2的flops少得多,而且性能也同時超過了ResNet和ResNeXt。QuadTree-B-b2的性能比ResNet101和ResNeXt101-32x4d分別高出7.7AP和6.3AP,骨干flops減少約40%。
在ADE20K的語義分割實驗中,在相似的參數量與flops下,比PVTv2提升了0.8-1.3。
作者介紹
一作唐詩濤,現在西蒙菲莎大學三年級在讀博士,導師譚平,研究方向為深度學習,三維視覺。在ECCV、ICCV、CVPR、ICML、ICLR等會議上發表多篇論文。

共同一作張家輝,現任阿里巴巴算法工程師。2020年于清華大學取得博士學位,研究方向為三維重建、三維深度學習。博士期間在Intel中國研究院及港科大實習或交流。在ECCV、ICCV、CVPR、ICLR、TPAMI、TVCG等會議或期刊上發表多篇論文。

朱思語博士,阿里云人工智能實驗室算法團隊負責人。他于香港科技大學獲得博士學位。在攻讀博士學位期間,共同創辦了3D視覺公司Altizure。朱思語博士在ICCV、CVPR、ECCV、PAMI等計算機視覺國際學術會議和期刊上發表30多篇論文。

譚平,現就職于阿里巴巴XR實驗室,曾任西蒙菲莎大學終身副教授、新加坡國立大學副教授。主要研究興趣包括計算機視覺、計算機圖形學、機器人技術、3D 重建、基于圖像的建模、圖像和視頻編輯、照明和反射建模。
?
 ?
?

















