













把大核卷積拆成三步,清華胡事民團隊新視覺Backbone刷榜三大任務(wù)
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
在視覺任務(wù)上,CNN、ViT各有各的優(yōu)勢和劣勢。
于是,以經(jīng)典Backbone為基礎(chǔ)、細節(jié)上相互借鑒,成了最近一個熱門研究方向。
前有微軟SwinTransformer引入CNN的滑動窗口等特性,刷榜下游任務(wù)并獲馬爾獎。
后有Meta AI的ConvNeXT用ViT上的大量技巧魔改ResNet后實現(xiàn)性能反超。
現(xiàn)在一種全新Backbone——VAN(Visiual Attention Network, 視覺注意力網(wǎng)絡(luò))再次引起學(xué)界關(guān)注。
因為新模型再一次刷榜三大視覺任務(wù),把上面那兩位又都給比下去了。
VAN號稱同時吸收了CNN和ViT的優(yōu)勢且簡單高效,精度更高的同時參數(shù)量和計算量還更小。
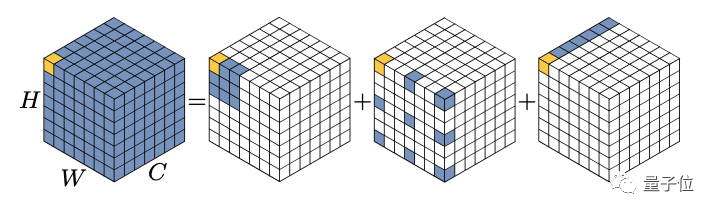
VAN來自清華計圖胡事民團隊,他們提出一個標準大核卷積可以拆解成三部分:
深度卷積(DW-Conv)、深度擴張卷積(DW-D-Conv)和1 × 1卷積(1 × 1 Conv)。
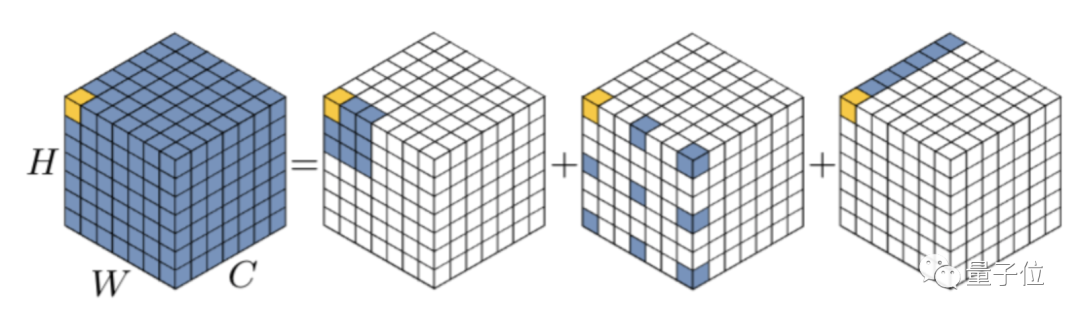
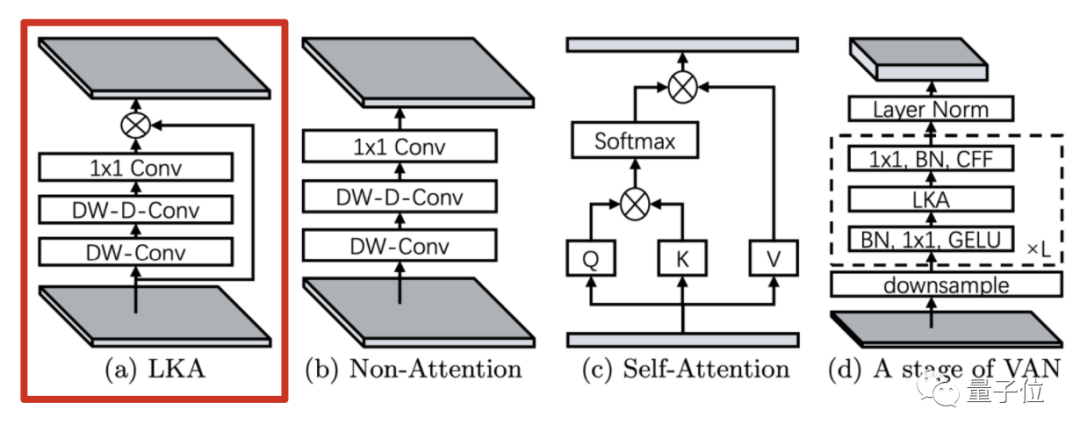
更關(guān)鍵的是,再加上一步element-wise相乘可以獲得類似注意力的效果,團隊把新的卷積模塊命名為大核注意力LKA(Large Kernel Attention)
論文最后還提到,現(xiàn)在的VAN只是一個直覺的原始版本、沒有仔細打磨,也就是說后續(xù)還有很大提升潛力。
(代碼已開源,地址在文末)
拆解大核卷積能算注意力
注意力機制,可以理解為一種自適應(yīng)選擇過程,能根據(jù)輸入辨別出關(guān)鍵特征并自動忽略噪聲。
關(guān)鍵步驟是學(xué)習(xí)輸入數(shù)據(jù)的長距離依賴,生成注意力圖。
有兩種常用方法來生成注意圖。
第一種是從NLP來的自注意力機制,但用在視覺上還有一些不足,比如把圖像轉(zhuǎn)換為一維序列會忽略其二維結(jié)構(gòu)。
第二種是視覺上的大核卷積方法,但計算開銷又太大。
為克服上面的問題,團隊提出的LKA方法把大核卷積拆解成三部分。
設(shè)擴張間隔為d,一個K x K的卷積可以拆解成K/d x K/d的深度擴張卷積,一個(2d ? 1) × (2d ? 1)的深度卷積核一個1 x 1的point-wise卷積。
△c為通道(channel)
這樣做,在捕捉到長距離依賴的同時節(jié)省了計算開銷,進一步可以生成注意力圖。

LKA方法不僅綜合了卷積和自注意力的優(yōu)勢,還額外獲得了通道適應(yīng)性。
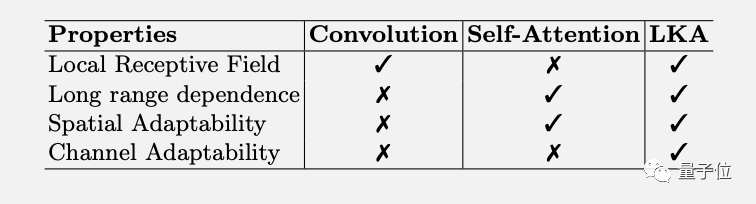
在CNN里,LKA方法與MobileNet的兩部分拆解法類似,增加的深度擴張卷積可以捕獲長距離依賴。
與ViT相比,解決了自注意力的二次復(fù)雜度對高分辨率圖像計算代價太大的問題,
MLP架構(gòu)中的gMLP也引入了注意力機制,但只能處理固定分辨率的圖像,且只關(guān)注了全局特征,忽略了圖像的局部結(jié)構(gòu)。
從理論上來說,LKA方法綜合了各方優(yōu)勢,同時克服了上述缺點。
那么,實際效果如何?
新Backbone刷榜三大任務(wù)
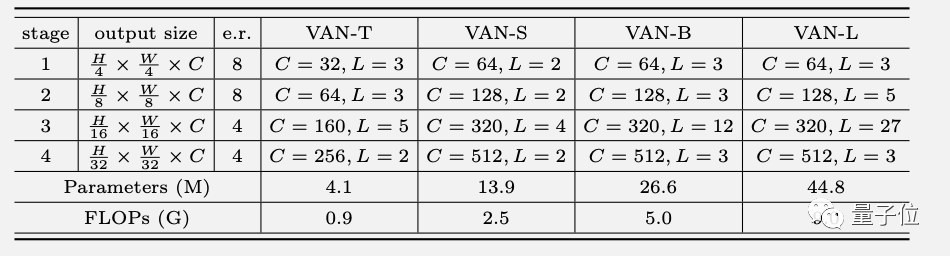
根據(jù)LKA方法設(shè)計的新Backbone網(wǎng)絡(luò)VAN,延續(xù)了經(jīng)典的四階段設(shè)計,具體配置如下。
每個階段的結(jié)構(gòu)如圖所示,其中下采樣率由步長控制,CFF代表卷積前饋網(wǎng)絡(luò)( convolutional feed-forward network)
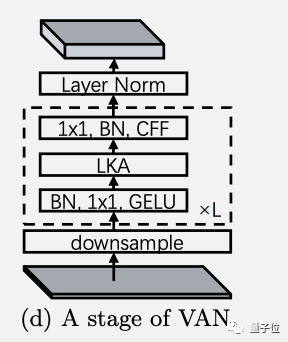
假輸入和輸出擁有相等的寬高和通道數(shù),可以算出計算復(fù)雜性。
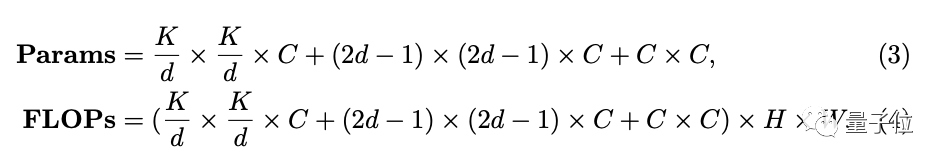
其中當卷積核大小(K)為21時,擴張間隔(d)取3可以讓參數(shù)量最小,便以此為默認配置。
團隊認為按此配置對于全局特征和局部特征的提取效果都比較理想。
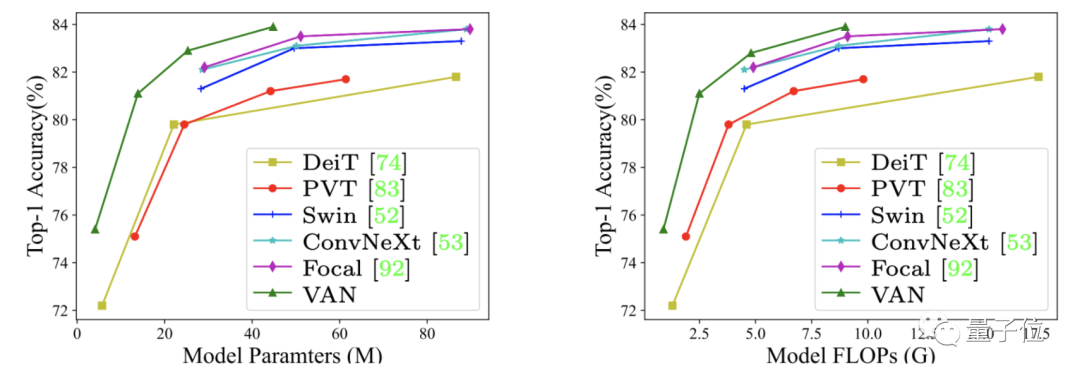
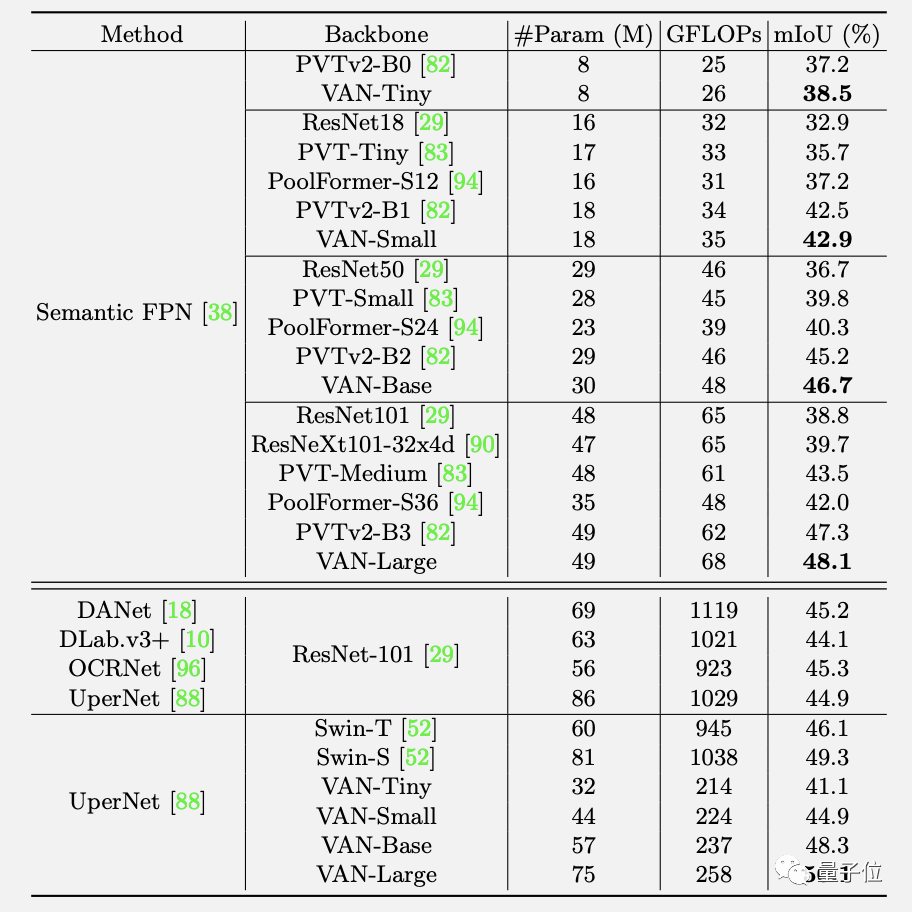
最終,在ImageNet上不同規(guī)模的VAN精度都超過了各類CNN、ViT和MLP。
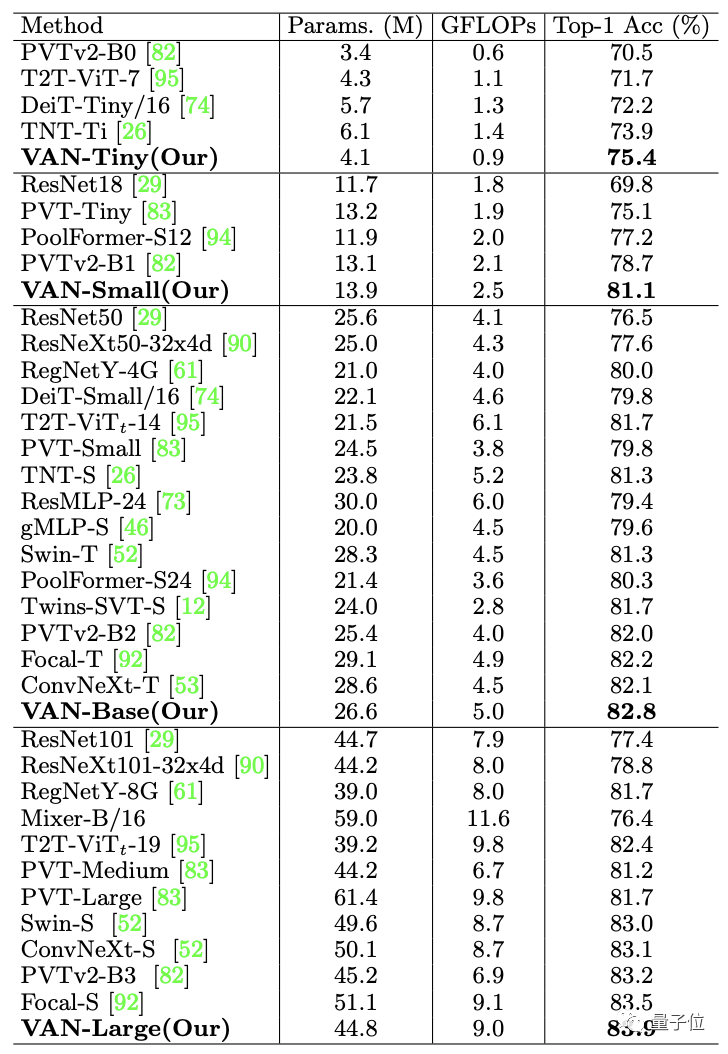
在COCO 2017目標檢測任務(wù)上,以VAN為Backbone應(yīng)用多種檢測方法也都領(lǐng)先。
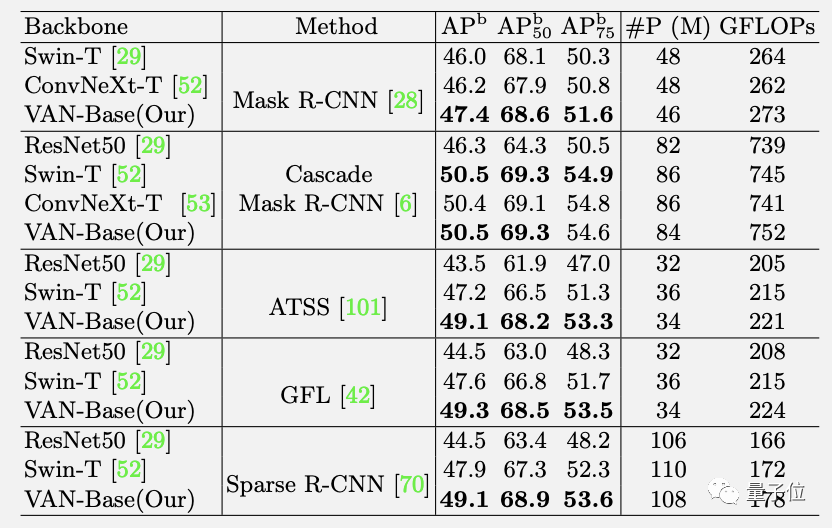
ADE20K語意分割任務(wù)上同樣如此。
而且正如前文所述,VAN未經(jīng)仔細打磨就已刷榜三大任務(wù),后續(xù)還有提升空間。
對于今后的改進方向,團隊表示可能會嘗試更大的卷積核,引入來自Res2Net的多尺度結(jié)構(gòu),或者Inception中的多分支結(jié)構(gòu)。
另外用VAN做圖像自監(jiān)督學(xué)習(xí)和遷移學(xué)習(xí),甚至能否做NLP都有待后續(xù)探索。
作者介紹
這篇論文來自清華大學(xué)計算機系胡事民團隊。
胡事民教授是清華計圖框架團隊的負責(zé)人,計圖框架則是首個由中國高校開源的深度學(xué)習(xí)框架。

一作博士生國孟昊,現(xiàn)就讀于清華大學(xué)計算機系,也是計圖團隊的成員。

這次論文的代碼已經(jīng)開源,并且提供了Pytorch版和計圖框架兩種版本。
該團隊之前有一篇視覺注意力的綜述,還成了arXiv上的爆款
配套的GitHub倉庫視覺注意力論文大合集Awesome-Vision-Attentions也有1.2k星。
最后八卦一下,莫非是團隊研究遍了各種視覺注意力機制后,碰撞出這個新的思路?
也是666了。
論文地址:
??https://arxiv.org/abs/2202.09741??
GitHub地址:
??https://github.com/Visual-Attention-Network??












