













面試就面試,問我原理干嘛,Order By
本文轉載自微信公眾號「飛天小牛肉」,作者小牛肉。轉載本文請聯(lián)系飛天小牛肉公眾號。
假設有這么一張用戶表 user:
- id int(11):主鍵
- username varchar(16):用戶名
- age int(11):年齡
- city varchar(16):城市
假設有這么一個需求:查詢出城市是 “南京” 的所有用戶名,并且按照用戶名進行排序,返回前 1000 個人的姓名、年齡。
眾所周知,排序使用的關鍵字是 order by,不難寫出這樣的 SQL 語句:
select city, username, age from user where city = '南京' order by username limit 1000;
這篇文章,我們就來解釋下,涉及 order by 的語句具體是怎么執(zhí)行的,以及有什么參數會影響執(zhí)行的行為
全字段排序
為避免全表掃描,我們在查詢條件的 city 字段上面建立索引。然后用 explain 命令來看看這個語句的執(zhí)行情況:

偷個懶,因為我其實一條數據也沒插入(狗頭保命),所以大伙兒在上圖中看見的 explain 分析出來的這條 SQL 的影響行數 rows 是 1
Extra 這個字段中的 Using filesort 表示的就是需要排序,MySQL 會給每個線程分配一塊內存用于排序,稱為 sort_buffer。
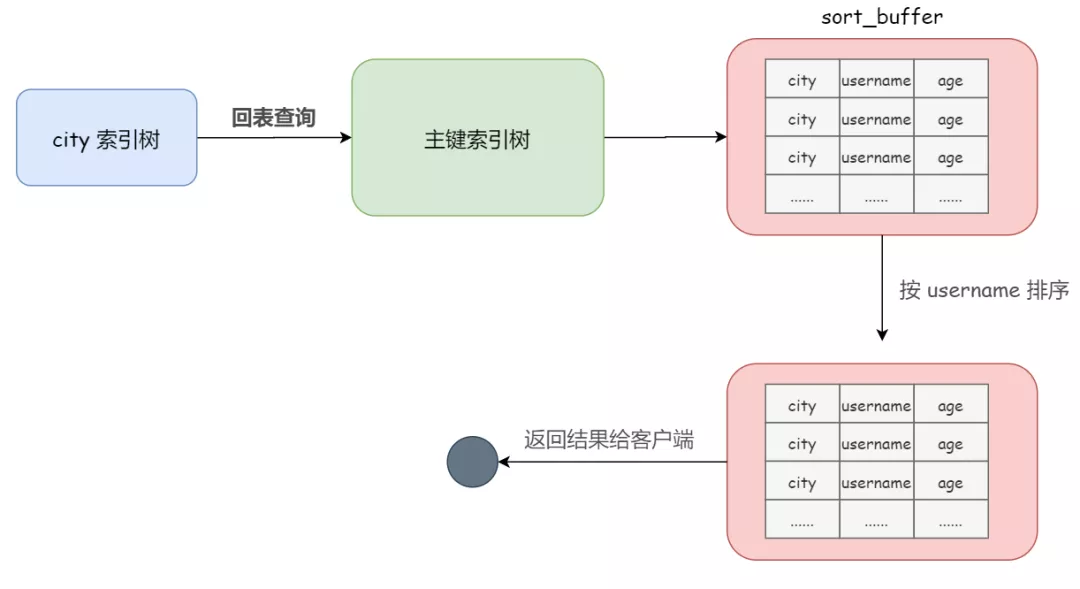
通常情況下,這個語句執(zhí)行流程如下所示 :
1)初始化 sort_buffer,放入 city、username、age 這三個字段;
2)從索引 city 找到第一個滿足 city='南京' 條件的主鍵 id
3)到主鍵 id 的索引樹上查找到對應的整行數據(回表查詢),然后取出 city、username、age 三個字段的值,存入 sort_buffer 中
4)從索引 city 取下一個記錄的主鍵 id
5)重復步驟 3、4 直到 city 的值不滿足查詢條件為止
6)對 sort_buffer 中的數據按照字段 username 做快速排序
按照字段 username 做快速排序這個動作,可能在內存中完成,也可能需要使用外部排序,這取決于排序所需的內存和 sort_buffer 的大小,由參數 sort_buffer_size 決定。
如果要排序的數據量小于 sort_buffer_size,排序就在內存中完成。但如果排序數據量太大,內存放不下,則就需要利用磁盤臨時文件來輔助排序。
解釋下這里使用磁盤臨時文件來進行輔助排序的含義,外部排序常用的排序算法是多路歸并排序算法,具體步驟如下:
- 到主鍵 id 索引樹上查找到對應的整行數據后,取 city、username、age 三個字段的值,存入 sort_buffer 中,能存多少是多少,當 sort_buffer 快要滿時,就對 sort_buffer 中的數據進行排序,排完后,把數據臨時放到磁盤的一個小文件中,然后清空 sort_buffer(這樣的話,一個很大的數據,就會被分成若干個臨時磁盤文件)
- 繼續(xù)回到主鍵 id 索引樹取數據,重復上一步,直到取出所有滿足條件的數據
- 最后,歸并已經有序的若干個臨時磁盤文件,形成一個完整的有序大文件
7)按照排序結果取前 1000 行返回給客戶端
可以看出,整個排序過程,我們要查詢的 city、username、age 全都參與了,所以,暫且把這個排序過程,稱為全字段排序
整條語句的執(zhí)行流程的示意圖如下所示:
針對上面利用磁盤臨時文件進行輔助排序的過程,不知道大家會不會有個很自然的想法:sort_buffer 內存放不下,需要用到臨時磁盤文件,磁盤文件越多,排序效率顯然就會越低下。那為什么還要把排序不相關的字段 city、username 放到 sort_buffer 中呢?只存放排序相關的 age 字段,這樣劃分的磁盤文件不就相對變少了嘛~
這就是 rowid 排序 ??
rowid 排序
rowid 排序,聽名字大概就能理解,就是,只把需要用于排序的字段和對應的主鍵 id,放到 sort_buffer 中。
那怎么確定走的是全字段排序還是 rowid 排序呢?
實際上有個參數控制的。這個參數就是 max_length_for_sort_data,是 MySQL 中專門控制用于排序的行數據的長度的一個參數。它的意思是,如果單行的長度超過這個值,MySQL 就認為單行太大(那么數據量肯定就越大,sort_buffer 可能不夠用),不能再像之前那樣把所有 select 的字段都存進 sort_buffer 了,要換一個算法,只存排序相關的字段
show variables like 'max_length_for_sort_data';
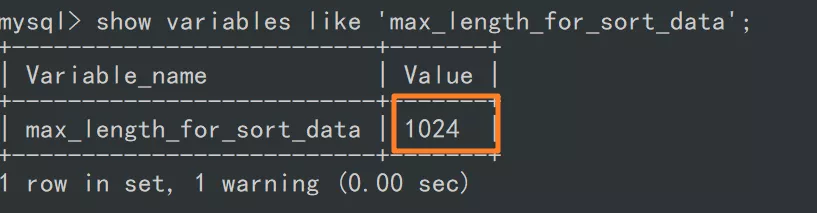
可以看到,max_length_for_sort_data 的默認值是 1024
可以通過下面這行命令進行修改
SET max_length_for_sort_data = 16;
表中我們定義的這三個字段 city、username、age 的總長度是 36,我把 max_length_for_sort_data 設置為 16,顯然,單行的長度已經超過這個值了,排序算法應該由全字段排序轉成了 rowid 排序。
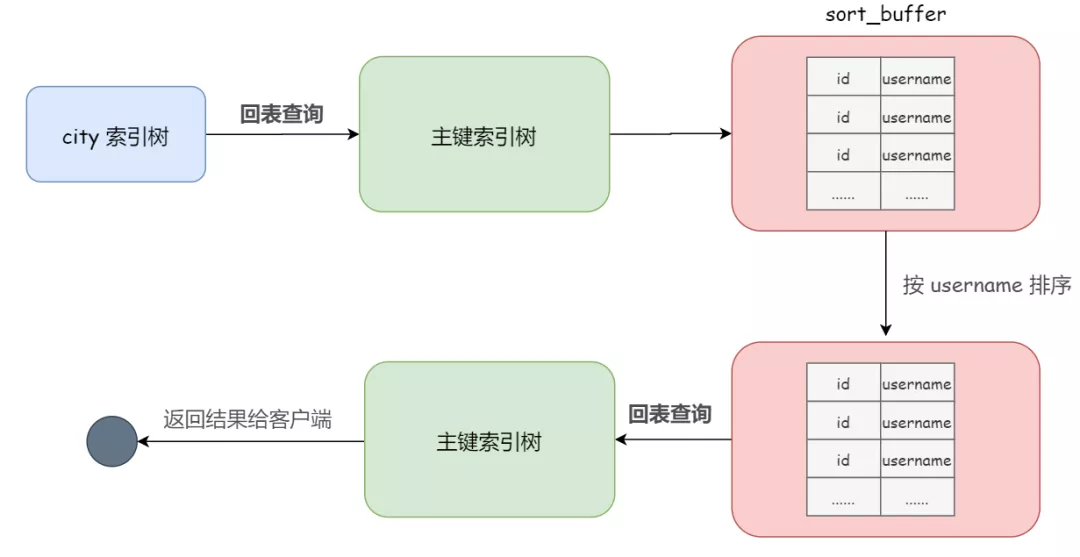
整個執(zhí)行流程就變成如下所示的樣子:
1)初始化 sort_buffer,放入兩個字段,即 username 和主鍵 id
2)從 city 索引中找到第一個滿足 city='南京' 條件的主鍵 id
3)到主鍵 id 的索引樹上查找到對應的整行數據(回表查詢),取出 username 和 id 這兩個字段,存入 sort_buffer 中
4)從 city 索引中取下一個記錄的主鍵 id;重復步驟 3、4 直到不滿足 city='南京' 的條件為止
5)對 sort_buffer 中的數據按照字段 username 進行排序
6)遍歷排序結果,取前 1000 行,并按照 id 的值回到主鍵 id 的索引樹中取出 city、username 和 age 三個字段返回給客戶端
可以看到,新的 rowid 算法放入 sort_buffer 的字段,只有要排序的列(即 username 字段)和主鍵 id。但有利有弊,存放在 sort_buffer 中的數據因為少了 city 和 age 字段的值,所以不能直接返回給客戶端了,需要再進行一次回表查詢。
這個執(zhí)行流程的示意圖如下:
從上面我們可以看出來,事實上,如果內存足夠大的話,MySQL 優(yōu)先選擇的仍然是全字段排序,把需要的字段都放到 sort_buffer 中,這樣排序后就會直接從內存里面返回查詢結果了,不用再回表查詢,減少磁盤訪問。
回表的話應該首先去緩沖池 Buffer Pool 中找到對應版本的數據,若找不到,則需要進行磁盤讀(索引文件是磁盤文件),理論上不會觸發(fā)磁盤讀,因為取 id 的時候已經從磁盤讀取了一次放到了緩沖池 Buffer Pool 中了,但不排除,第一次取完數據放到 sort buffer 后緩存中的數據頁被淘汰了,可能會觸發(fā)磁盤讀
order by 優(yōu)化
很顯然,如果不排序就能得到正確的結果,那對系統(tǒng)的消耗會小很多,語句的執(zhí)行時間也會變得更短。
那么,是不是所有的 order by 都需要排序操作呢?
并不是!
從上面分析的執(zhí)行過程我們可以看到,MySQL 之所以需要 sort_buffer,并且在 sort_buffer 上做排序操作,其原因是原來的數據都是無序的。
回顧下我們的需求:查詢出 city 是 “南京” 的所有 username,并且按照 username 進行排序,返回前 1000 個人的姓名、年齡。
那,如果能夠保證從 city 這個索引上取出來的數據行,已經天然就是按照 username 進行遞增排序的話,不就不用再排序了嗎
所以,我們可以在這張表上創(chuàng)建一個 city 和 username 的聯(lián)合索引:
alter table user add index idx_city_username(city, username);
在這個聯(lián)合索引上,我們依然可以用樹搜索的方式定位到第一個滿足 city='南京' 的記錄,并且額外確保了,接下來按順序取 “下一條記錄” 的遍歷過程中,只要 city 的值是南京,username 的值就一定是有序的(不清楚的小伙伴可以回看下聯(lián)合索引相關的知識)。
這樣整個查詢過程的流程就變成了:
1)從聯(lián)合索引 (city, username) 上找到第一個滿足 city='南京' 條件的主鍵 id
2)到主鍵 id 的索引樹上查找到對應的整行數據(回表查詢),取出 username、city 和 age 這三個字段的值,作為結果集的一部分直接返回
3)從聯(lián)合索引 (city, username) 上取下一個記錄主鍵 id;
4)重復步驟 2、3,直到查到第 1000 條記錄,或者是不滿足 city='南京' 條件時循環(huán)結束
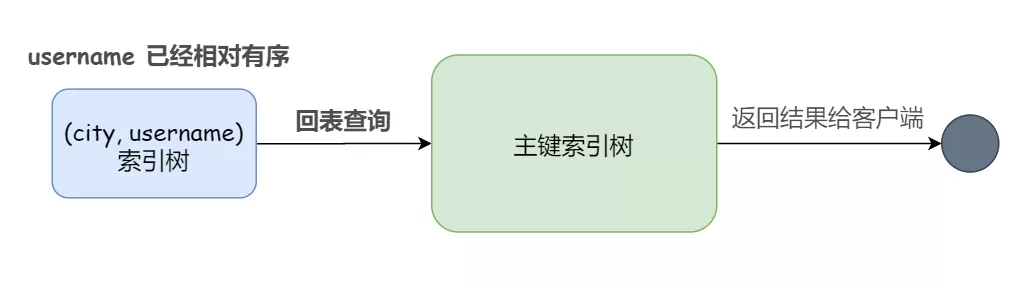
可以看到,這個查詢過程不需要 sort_buffer,也不需要排序,整個流程被大大縮短了。
再用 explain 分析下這條語句:

從圖中可以看到,Extra 字段中沒有 Using filesort 了,也就是不需要排序了。
而且由于 (city,username) 這個聯(lián)合索引本身有序,所以這個查詢也不用把 4000 行全都讀一遍,只要找到滿足條件的前 1000 條記錄就可以退出了。也就是說,在我們這個例子里,只需要掃描 1000 次就可以了。
說到這里,不知道有沒有小伙伴能夠察覺點什么
回表查詢!
是的,說了這么多,回表查詢這個東西一直都在啊,完全可以用上 覆蓋索引 來去掉回表過程啊~
不就是要回表取出 username、city 和 age 這三個字段的值嗎,咱就直接創(chuàng)建一個 city、name 和 age 的聯(lián)合索引,對應的 SQL 語句就是:
alter table user add index idx_city_username_age(city, username, age);
這樣,整個流程就被進一步簡化:
1)從聯(lián)合索引 (city, username, age) 樹上找到第一個滿足 city='南京' 條件的記錄,把這條記錄作為結果集的一部分直接返回;
2)從聯(lián)合索引 (city, username, age) 樹上取下一個記錄,同樣將這條記錄作為結果集的一部分直接返回
3)重復執(zhí)行步驟 2,直到查到第 1000 條記錄,或者是不滿足 city='南京' 條件時循環(huán)結束
如下圖所示:
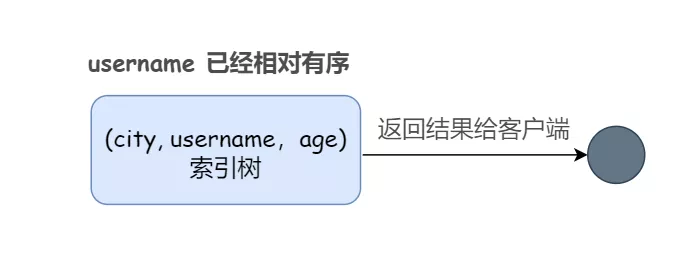
當然了,使用覆蓋索引性能上會快很多,但是索引的維護也是需要代價的,這里需要自己做一個權衡取舍~
最后放上這道題的背誦版:
?? 面試官:SQL 優(yōu)化了解過嗎?
?? 小牛肉:我來說一下 order by 語句的優(yōu)化。
- order by 的基本原理其實就是 MySQL 會給每個線程分配一塊內存也就是 sort_buffer 用于排序,sort_buffer 中存儲的是 select 涉及到的所有的字段,可以稱為全字段排序吧。排序這個動作,可能在內存中完成,也可能需要使用外部排序,這取決于排序所需的內存和 sort_buffer 的大小,由參數 sort_buffer_size 決定。如果要排序的數據量小于 sort_buffer_size,排序就在內存中完成。但如果排序數據量太大,內存放不下,就需要利用磁盤臨時文件來輔助排序。
- 這里其實可以優(yōu)化下,只存放排序相關的字段,而不是 select 涉及的所有字段,這樣 sort_buffer 中存放的東西就多一點,就盡可能避免使用磁盤進行外部排序,或者說使得劃分的磁盤文件相對變少,減少磁盤訪問。這種排序稱為 rowid 排序。如果表中單行的長度超過 max_length_for_sort_data 定義的值,那 MySQL 就認為單行太大(那么數據量肯定就越大,sort_buffer 可能不夠用),由全字段排序改為 rowid 排序。
以上是我們說的關于 order by 的兩個參數優(yōu)化,還可以根據索引進行一些優(yōu)化
- 以 select a, b, c from table where a = xxxx order by b 為例,我們?yōu)椴樵儣l件 a 和排序條件 b 建立聯(lián)合索引,聯(lián)合索引就是 a 是從小到大絕對有序的,如果 a 相同,再按 b 從小到大排序,這樣就不需要排序了,直接避免了排序這個操作。
- 還可以進一步優(yōu)化,由于聯(lián)合索引 (a, b) 中沒有 c 的值,所以從聯(lián)合索引樹上獲取符合條件的對應主鍵 id 后,還需要回表查詢取出 a b c 的值,這個回表查詢的過程可以通過建立 (a,b,c) 覆蓋索引來避免。

















