圖解 Flink 的 Checkpoint 機制

Flink是一個分布式的流處理引擎,而流處理的其中一個特點就是7X24。那么,如何保障Flink作業的持續運行呢?Flink的內部會將應用狀態(state)存儲到本地內存或者嵌入式的kv數據庫(RocksDB)中,由于采用的是分布式架構,Flink需要對本地生成的狀態進行持久化存儲,以避免因應用或者節點機器故障等原因導致數據的丟失,Flink是通過checkpoint(檢查點)的方式將狀態寫入到遠程的持久化存儲,從而就可以實現不同語義的結果保障。通過本文,你可以了解到什么是全局一致性檢查點,Flink內部如何通過檢查點實現Exactly Once的結果保障。
什么是Checkpoint(檢查點)
為了保證state容錯,Flink提供了處理故障的措施,這種措施稱之為checkpoint(一致性檢查點)。checkpoint是Flink實現容錯的核心功能,主要是周期性地觸發checkpoint,將state生成快照持久化到外部存儲系統(比如HDFS)。這樣一來,如果Flink程序出現故障,那么就可以從上一次checkpoint中進行狀態恢復,從而提供容錯保障。另外,通過checkpoint機制,Flink可以實現Exactly-once語義(Flink內部的Exactly-once,關于端到端的exactly_once,Flink是通過兩階段提交協議實現的)。下面將會詳細分析Flink的checkpoint機制。
檢查點的生成
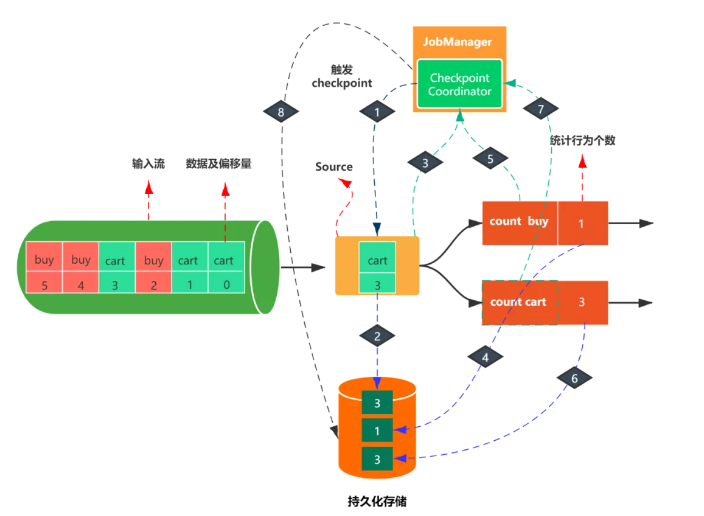
如上圖,輸入流是用戶行為數據,包括購買(buy)和加入購物車(cart)兩種,每種行為數據都有一個偏移量,統計每種行為的個數。
第一步:JobManager checkpoint coordinator 觸發checkpoint。
第二步:假設當消費到[cart,3]這條數據時,觸發了checkpoint。那么此時數據源會把消費的偏移量3寫入持久化存儲。
第三步:當寫入結束后,source會將state handle(狀態存儲路徑)反饋給JobManager的checkpoint coordinator。
第四步:接著算子count buy與count cart也會進行同樣的步驟
第五步:等所有的算子都完成了上述步驟之后,即當 Checkpoint coordinator 收集齊所有 task 的 state handle,就認為這一次的 Checkpoint 全局完成了,向持久化存儲中再備份一個 Checkpoint meta 文件,那么整個checkpoint也就完成了,如果中間有一個不成功,那么本次checkpoin就宣告失敗。
檢查點的恢復
通過上面的分析,或許你已經對Flink的checkpoint有了初步的認識。那么接下來,我們看一下是如何從檢查點恢復的。
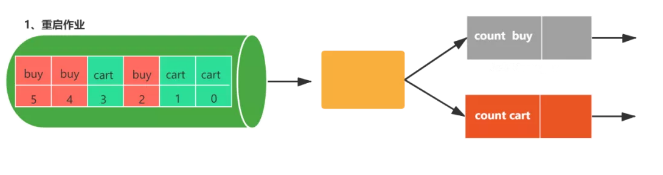
- 任務失敗

- 重啟作業
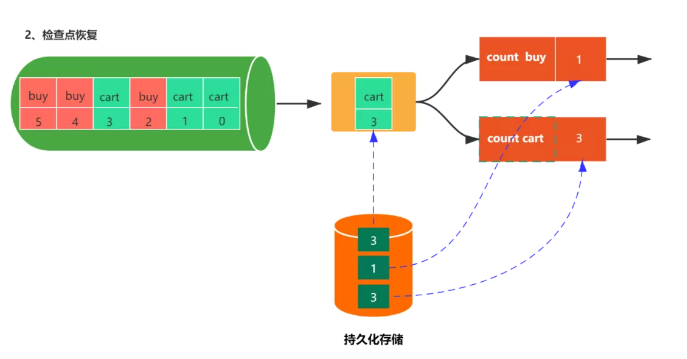
- 恢復檢查點
繼續處理數據
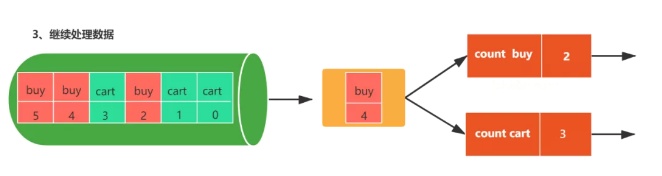
上述過程具體總結如下:
- 第一步:重啟作業
- 第二步:從上一次檢查點恢復狀態數據
- 第三步:繼續處理新的數據
Flink內部Exactly-Once實現
Flink提供了精確一次的處理語義,精確一次的處理語義可以理解為:數據可能會重復計算,但是結果狀態只有一個。Flink通過Checkpoint機制實現了精確一次的處理語義,Flink在觸發Checkpoint時會向Source端插入checkpoint barrier,checkpoint barriers是從source端插入的,并且會向下游算子進行傳遞。checkpoint barriers攜帶一個checkpoint ID,用于標識屬于哪一個checkpoint,checkpoint barriers將流邏輯是哪個分為了兩部分。對于雙流的情況,通過barrier對齊的方式實現精確一次的處理語義。
關于什么是checkpoint barrier,可以看一下CheckpointBarrier類的源碼描述,如下:
- /**
- * Checkpoint barriers用來在數據流中實現checkpoint對齊的.
- * Checkpoint barrier由JobManager的checkpoint coordinator插入到Source中,
- * Source會把barrier廣播發送到下游算子,當一個算子接收到了其中一個輸入流的Checkpoint barrier時,
- * 它就會知道已經處理完了本次checkpoint與上次checkpoint之間的數據.
- *
- * 一旦某個算子接收到了所有輸入流的checkpoint barrier時,
- * 意味著該算子的已經處理完了截止到當前checkpoint的數據,
- * 可以觸發checkpoint,并將barrier向下游傳遞
- *
- * 根據用戶選擇的處理語義,在checkpoint完成之前會緩存后一次checkpoint的數據,
- * 直到本次checkpoint完成(exactly once)
- *
- * checkpoint barrier的id是嚴格單調遞增的
- *
- */
- public class CheckpointBarrier extends RuntimeEvent {...}
可以看出checkpoint barrier主要功能是實現checkpoint對齊的,從而可以實現Exactly-Once處理語義。
下面將會對checkpoint過程進行分解,具體如下:
圖1,包括兩個流,每個任務都會消費一條用戶行為數據(包括購買(buy)和加購(cart)),數字代表該數據的偏移量,count buy任務統計購買行為的個數,coun cart統計加購行為的個數。
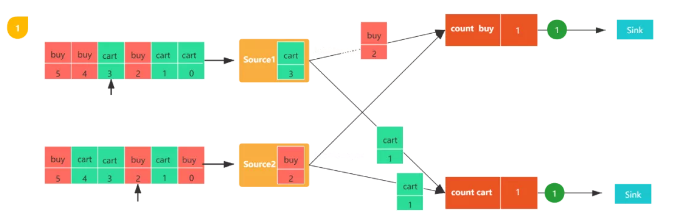
圖2,觸發checkpoint,JobManager會向每個數據源發送一個新的checkpoint編號,以此來啟動檢查點生成流程。
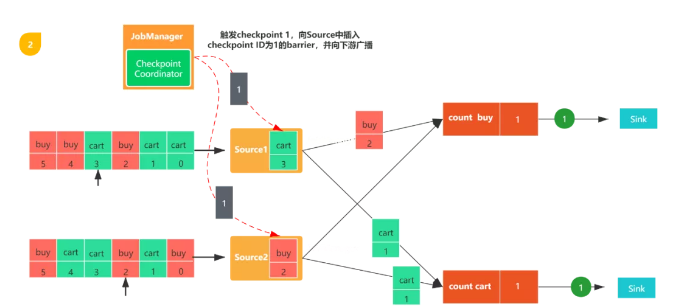
圖3,當Source任務收到消息后,會停止發出數據,然后利用狀態后端觸發生成本地狀態檢查點,并把該checkpoint barrier以及checkpoint id廣播至所有傳出的數據流分區。狀態后端會在checkpoint完成之后通知任務,隨后任務會向Job Manager發送確認消息。在將checkpoint barrier發出之后,Source任務恢復正常工作。
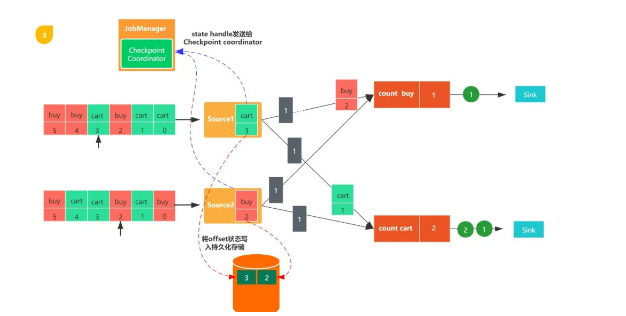
圖4,Source任務發出的checkpoint barrier會發送到與之相連的下游算子任務,當任務收到一個新的checkpoint barrier時,會繼續等待其他輸入分區的checkpoint barrier到來,這個過程稱之為barrier 對齊,checkpoint barrier到來之前會把到來的數據線緩存起來。
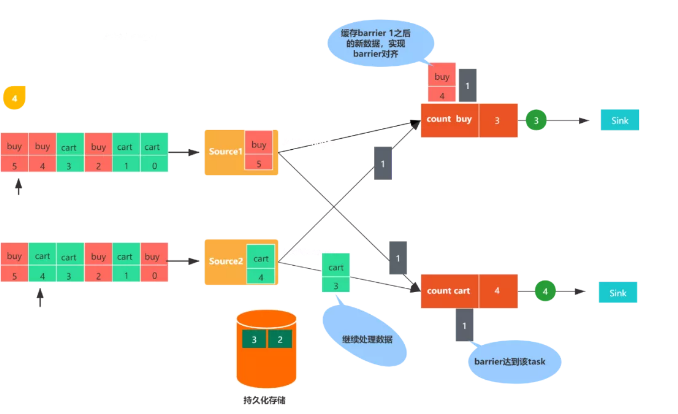
圖5,任務收齊了全部輸入分區的checkpoint barrier之后,會通知狀態后端開始生成checkpoint,同時會把checkpoint barrier廣播至下游算子。

圖6,任務在發出checkpoint barrier之后,開始處理因barrier對齊產生的緩存數據,在緩存的數據處理完之后,就會繼續處理輸入流數據。
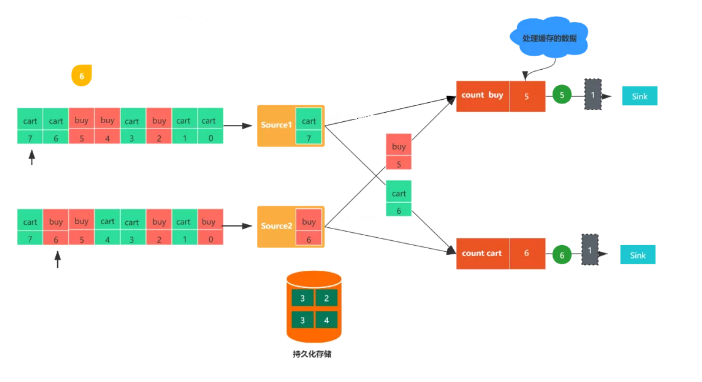
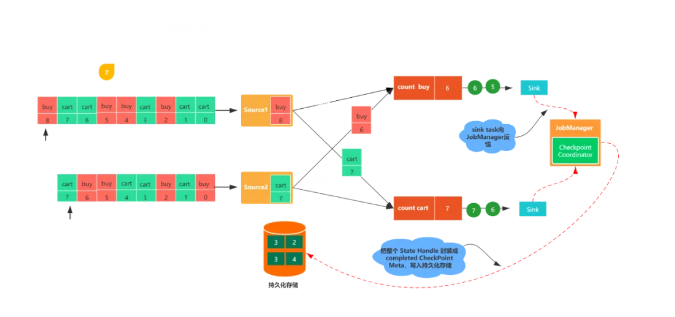
圖7,最終checkpoint barrier會被傳送到sink端,sink任務接收到checkpoint barrier之后,會向其他算子任務一樣,將自身的狀態寫入checkpoint,之后向Job Manager發送確認消息。Job Manager接收到所有任務返回的確認消息之后,就會將此次檢查點標記為完成。
使用案例
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- // checkpoint的時間間隔,如果狀態比較大,可以適當調大該值
- env.enableCheckpointing(1000);
- // 配置處理語義,默認是exactly-once
- env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
- // 兩個checkpoint之間的最小時間間隔,防止因checkpoint時間過長,導致checkpoint積壓
- env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
- // checkpoint執行的上限時間,如果超過該閾值,則會中斷checkpoint
- env.getCheckpointConfig().setCheckpointTimeout(60000);
- // 最大并行執行的檢查點數量,默認為1,可以指定多個,從而同時出發多個checkpoint,提升效率
- env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
- // 設定周期性外部檢查點,將狀態數據持久化到外部系統中,
- // 使用該方式不會在任務正常停止的過程中清理掉檢查點數據
- env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
總結
本文首先從Flink的狀態入手,以圖解加文字的形式詳細解釋了Flink的checkpoint機制,并給出了使用Checkpoint時的程序配置。