













MySQL Checkpoint機制詳解
本文轉載自微信公眾號「數據和云」,作者崔虎龍。轉載本文請聯系數據和云公眾號。
MySQL為了保證數據會做很多checkpoint動作。特別是InnoDB采用Write Ahead Log策略來防止宕機導致的數據丟失:即事務提交時,先寫重做日志,再修改內存數據頁的方式臟數據刷新等。除此之外,還有服務重新啟動。
一.checkpoint介紹
checkpoint是為了解決哪些問題呢?
- 對于數據需要頻繁更新的場景,要實時更新,對于MySQL來說,只處理IO,就能把性能耗盡。
- Redo日志大小也是有限的,通過刷新策略,可以更有效的重復使用文件,不需要開辟新的空間。
- 緩沖區大小有限。數據不刷到硬盤,對于查詢業務,命中率越來越小。
- 數據庫宕機,崩潰恢復期間,需要從上次的檢查點進行恢復,使得效率提升。
- 物理備份日志點。
InnoDB引擎通過LSN(Log Sequence Number)來標記版本,LSN是日志空間中每條日志的結束點,用字節偏移量來表示。每個Page有LSN,每個Redo log有LSN,每個checkpoint也有LSN。
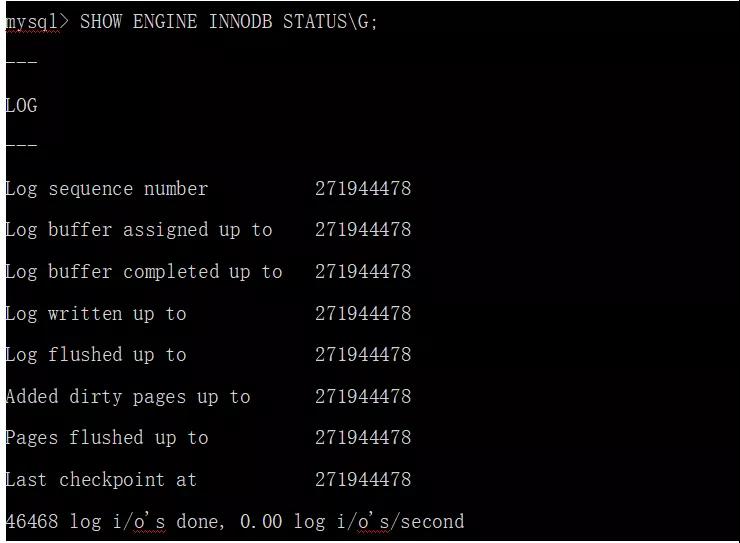
checkpoint會對哪些MySQL實體做操作?
- Dirty page:InnoDB緩沖池中已經在內存中更新的頁面,其中的更改還沒有寫入(刷新)到數據文件。
- Flush:將已緩沖在內存區域或臨時磁盤存儲區域中的數據庫文件的更改寫入。
- Redo log:數據更改信息記錄文件。
二.checkpoint機制
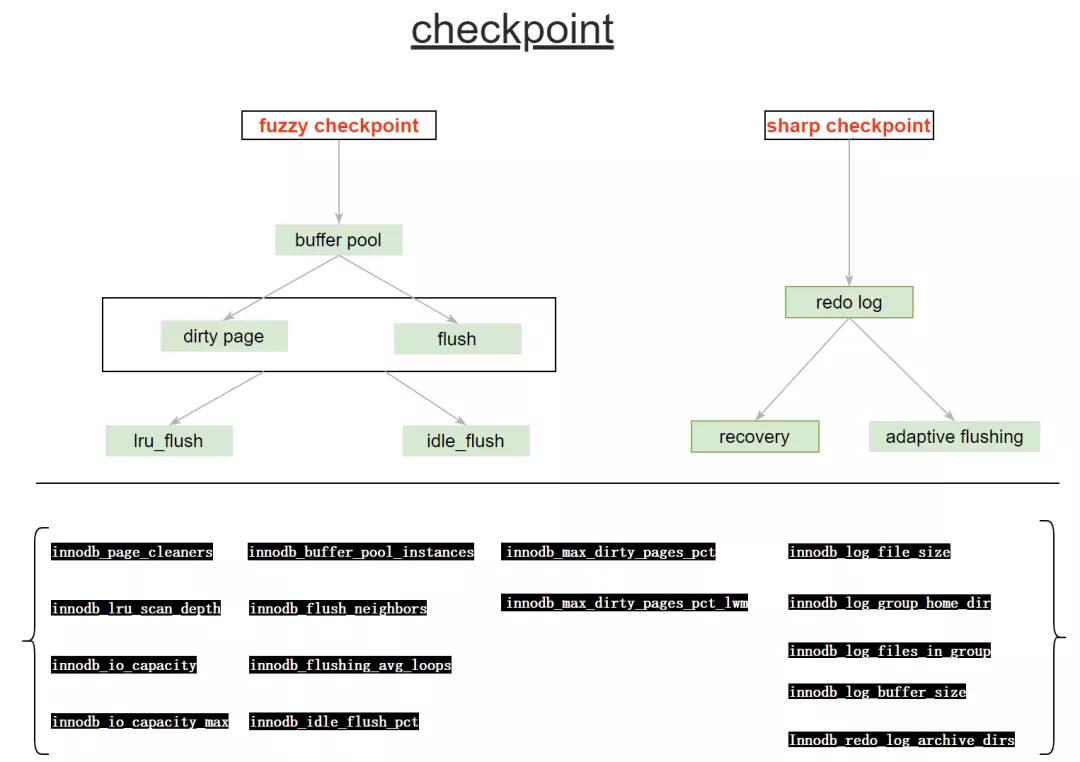
從官方提供的說明中checkpoint分為兩個:
- Fuzzy checkpoint:進行部分臟頁的刷新,有效循環利用Redo日志。
- Sharp checkpoint:發生在關閉數據庫時,將所有臟頁刷回磁盤。
通過以上兩個方式,在不同的情況下觸發checkpoint:
1) flush_lru_list
flush_lru_list checkpoint是在單獨的page cleaner線程中執行的。Buffer Pool的LRU空閑列表中保留一定數量的空閑頁面,來保證Buffer Pool中有足夠的空間應對新的數據庫請求。
在空閑列表不足時,發生flush_lru_list checkpoint,空閑數量閾值是可以配置的。

如innodb_page_cleaners線程的數量超過了緩沖池實例(innodb_buffer_pool_instances)的數量,則innodb_page_cleaners將自動設置為與innodb_buffer_pool_instances相同的值。
2)Dirty Page
臟頁數量太多時,InnoDB引擎會強制進行checkpoint,下面有幾個核心參數控制的checkpoint點。
- 刷新比率

innodb_max_dirty_pages_pct_lwm閾值的目的是控制緩沖池中臟頁的百分比,防止臟頁的數量達到innodb_max_dirty_pages_pct變量定義的閾值(默認值為90)。當緩沖池中的臟頁百分比達到閾值時,InnoDB會主動刷新緩沖池中的頁。
- innodb_max_dirty_pages_pct:
InnoDB會嘗試從緩沖池中刷新數據,這樣臟頁的百分比就不會超過這個值。innodb_max_dirty_pages_pct默認90%。
- innodb_max_dirty_pages_pct_lwm:
定義低水位標記,表示啟用預沖洗以控制臟頁比率的臟頁百分比。0值將完全禁用預刷新行為。配置的值應該總是低于innodb_max_dirty_pages_pct的值。
- innodb_flush_neighbors
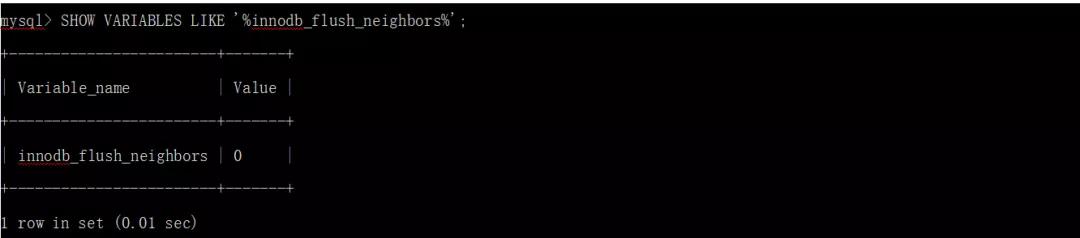
變量定義了從緩沖池中刷新一個頁是否也會刷新相同范圍內的其他臟頁。
默認設置0禁用innodb_flush_neighbors。
設置為1將刷新同一區段中的連續臟頁。
設置為2將刷新同一區段中的臟頁。
當表數據存儲在傳統的HDD存儲設備上時,與在不同時間刷新單個頁相比,在一次操作中刷新相鄰頁可以減少I/O開銷(主要用于磁盤尋道操作)。對于SSD來說:普遍場景在IO方面的處理能力已經非常優秀。可以打開這個參數。
- innodb_lru_scan_depth
變量定義了對于每個緩沖池實例,緩沖池LRU列出的頁面清理器線程掃描的臟頁面的深度。這是一個由頁面page clear thread每秒執行一次的后臺操作。
小于默認值的設置通常適用于大多數工作負載,顯著高于必要值時可能會影響性能。只有在典型工作負載下有空閑I/O容量時,才考慮增加該值。相反,如果寫密集的工作負載使您的I/O容量飽和,則需要降低該值,特別是在大型緩沖池的情況下。
另外,在改變緩沖池實例數量時,考慮調整innodb_lru_scan_depth,因為innodb_lru_scan_depth * innodb_buffer_pool_instances定義了page clear thread每秒執行的工作量。
innodb_flush_neighbors和innodb_lru_scan_depth變量主要用于寫密集型的工作負載。對于大量DML活動,如果刷新不夠激烈,則刷新可能會滯后;如果刷新太激烈,磁盤寫可能會使I/O容量飽和。
- innodb_io_capacity

設置適用于所有的緩沖池實例。當刷新臟頁時,I/O容量將平均分配給緩沖池實例。
注意,如果刷新落后,緩沖池的刷新速率可能會超過InnoDB可用的I/O容量,這是由innodb_io_capacity設置定義的。innodb_io_capacity_max值定義了這種情況下的I/O容量上限,這樣I/O活動的峰值不會占用服務器的整個I/O容量。一般設置有不同的硬盤類型配置 SAS 200~1000 ,SSD 2000~5000 ,PCI-E 10000-50000
3)Adaptive Flushing
當產生大量寫密集型工作負載時,可能會導致吞吐量的突然變化。當InnoDB Redo日志文件滿了,就會出現一個Sharp checkpoint,導致臨時的吞吐量降低。即使innodb_max_dirty_pages_pct閾值未達到,也會出現這種情況。
innodb_adaptive_flushing_lwm變量定義了Redo日志容量的低水位標志。當超過該閾值時,啟用自適應刷新(Adaptive Flushing)。
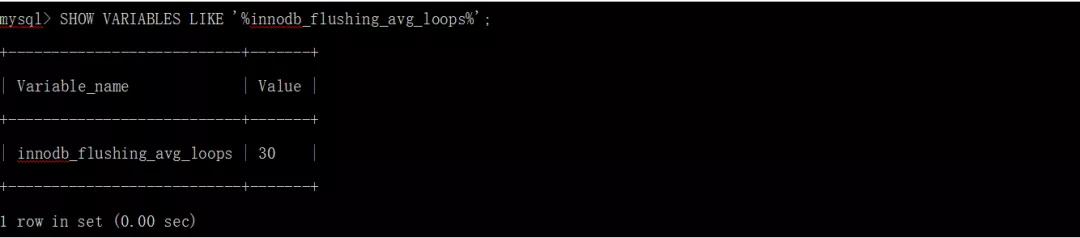
innodb_flushing_avg_loops定義了InnoDB保持先前計算的刷新狀態快照的迭代次數,控制自適應刷新對前臺工作負載變化的響應速度。就是說控制統計前N個page flush速率,避免太快flush。
高的值意味著InnoDB保持先前計算的快照的時間更長,因此自適應刷新響應更慢。如日志空間利用率未達到75%,則應該使用較高的innodb_flushing_avg_loops值來保持盡可能平滑的刷新。對于具有極端負載峰值或日志文件不提供大量空間的系統,應使較小的值允許flush以密切跟蹤工作負載更改,并有助于避免達到75%的日志空間利用率。
4)限制空閑期間的緩沖區刷新
從MySQL 8.0.18開始,你可以使用innodb_idle_flush_pct變量來限制空閑時間段(數據庫頁面不被修改的時間段)的緩沖池刷新速率。innodb_idle_flush_pct的值是innodb_io_capacity設置的百分比,innodb_io_capacity定義了每秒可用于InnoDB的I/O操作次數。innodb_idle_flush_pct的默認值是100,這是innodb_io_capacity設置的100%。為了限制空閑時間的刷新,定義一個innodb_idle_flush_pct小于100的值。
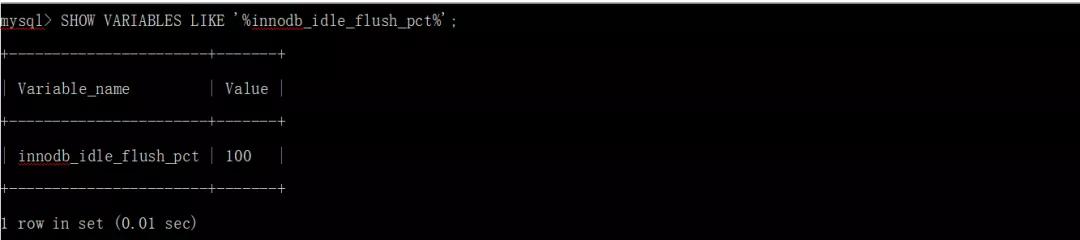
在空閑期間限制頁面刷新可以幫助延長固態存儲設備的壽命,但其的副作用可能包括在長時間的空閑期間之后更長的關閉時間以及在服務器發生故障時更長的恢復時間等問題。
5)Redo 日志
Redo日志在物理上表示為一組文件,通常命名為ib_logfile0和ib_logfile1。重做日志中的數據按照受影響的記錄進行記錄,這些數據統稱為重做。重做日志的數據通過不斷增加的LSN值表示。
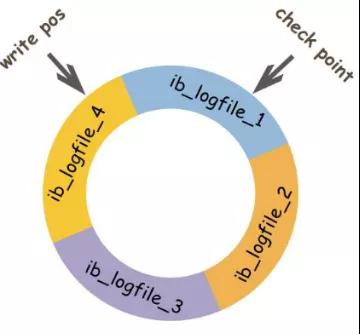
- 用于記錄數據修改后的記錄,順序記錄。
- 在崩潰恢復期間使用的基于磁盤的數據結構,用于糾正不完整事務寫入的數據。
Redo日志的磁盤布局受配置選項innodb_log_file_size、innodb_log_group_home_dir和innodb_log_files_in_group的影響。重做日志操作的性能還受到日志緩沖區的影響innodb_log_buffer_size。
在崩潰恢復期間,InnoDB需查找一個寫入日志文件的檢查點。LSN出現在數據庫的磁盤映像之前對數據庫的所有修改,之后InnoDB從檢查點掃描日志文件,將日志修改應用到數據庫。
Innodb_redo_log_archive_dirs重做日志進行歸檔,主要考慮到備份操作進行時,復制重做日志記錄的備份實用程序有時可能無法跟上重做日志生成的速度,從而導致重寫重做日志記錄而丟失這些記錄。除此之外也可以作為數據恢復的日志記錄。
6)常見檢查點壓力下的日志

出現這個page_cleaner的問題是臟頁產生的太快,導致頁面清理程序清理不過來。
目前解決方式,可以組合以下參數進行調整:
- innodb_lru_scan_depth 值設置小。
- innodb_io_capacity,innodb_io_max_capacity 合理設置。
- innodb_max_dirty_page_pct 也設置的小一些。
- innodb_adaptive_hash_index 關閉。
三.總結
對于MySQL的checkpoint機制來說,是對IO和內存做了平衡操作。
通過調節參數,對于不同的應用系統,都是提升性能的一種方式,普遍情況下采取默認方式。
另一個思路:重做日志可以無限增大,磁盤足夠大,同時緩沖池足夠大,能夠緩存所有數據,那么就不需要將緩沖池中的臟頁頻繁刷新。
關于作者
崔虎龍,云和恩墨MySQL技術顧問,長期服務于金融、游戲、物流等行業的數據中心,設計數據存儲架構,并熟悉數據中心運營管理的流程及規范,自動化運維等。擅長MySQL、Redis、MongoDB數據庫高可用設計和運維故障處理、備份恢復、升級遷移、性能優化。自學通過了MySQL OCP 5.6和MySQL OCP 5.7認證。2年多開發經驗,10年數據庫運維工作經驗,其中專職做MySQL工作8年;曾經擔任過項目經理、數據庫經理、數據倉庫架構師、MySQL技術專家、DBA等職務;涉及行業:金融(銀行、理財)、物流、游戲、醫療、重工業等。















