













一日一技:拼接個URL你也能搞錯,還寫個爬蟲

在寫爬蟲的過程中,我們經常需要解析網站的列表頁。例如下面這個例子:
- <html>
- <head>
- <meta charset="utf-8">
- <title>測試相對路徑</title>
- </head>
- <body>
- <div>
- <h1>書籍列表</h1>
- <ul>
- <li><a href="http://127.0.0.1:8000/book/1.html">第一本書</a></li>
- <li><a href="http://127.0.0.1:8000/book/2.html">第二本書</a></li>
- <li><a href="http://127.0.0.1:8000/book/3.html">第三本書</a></li>
- <li><a href="http://127.0.0.1:8000/book/4.html">第四本書</a></li>
- <li><a href="http://127.0.0.1:8000/book/5.html">第五本書</a></li>
- </ul>
- </div>
- </body>
- </html>
運行效果如下圖所示:
這種情況下,我想獲取每一項的URL非常簡單,直接寫一個XPath就可以了,如下圖所示:
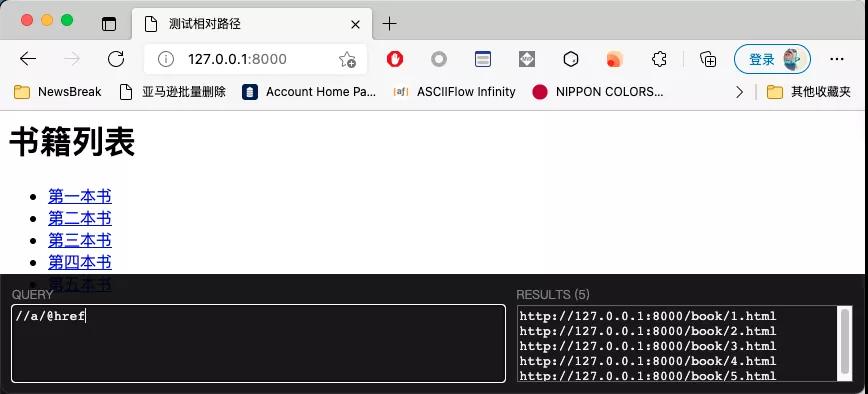
仔細觀察你會發現,每一個連接的URL都是以http://127.0.0.1:8000開頭的。而當前列表頁的地址也是http://127.0.0.1:8000。所以為了簡單起見,標簽里面可以使用相對路徑:
- <html>
- <head>
- <meta charset="utf-8">
- <title>測試相對路徑</title>
- </head>
- <body>
- <div>
- <h1>書籍列表</h1>
- <ul>
- <li><a href="/book/1.html">第一本書</a></li>
- <li><a href="/book/2.html">第二本書</a></li>
- <li><a href="/book/3.html">第三本書</a></li>
- <li><a href="/book/4.html">第四本書</a></li>
- <li><a href="/book/5.html">第五本書</a></li>
- </ul>
- </div>
- </body>
- </html>
運行效果如下圖所示,用XPath只能提取到半截URL:
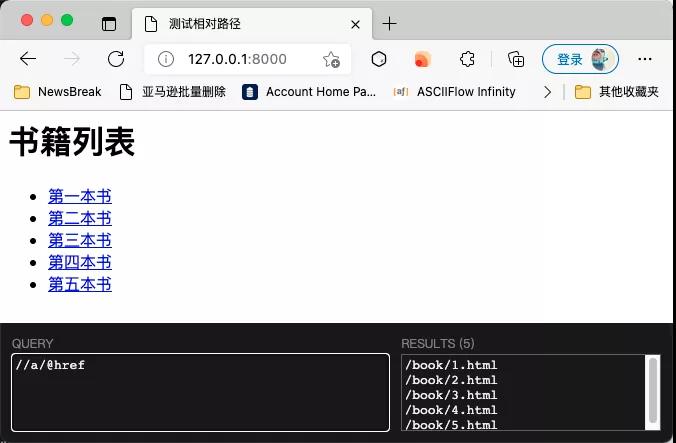
但是瀏覽器可以正確識別這樣的相對地址,并且當你點擊的時候,它能自動跳轉到正確的地址:
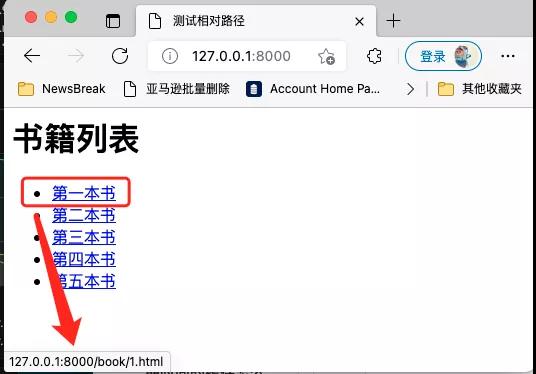
相對路徑如果是以/開頭,那么就會在相對路徑前面拼接上網站的主域名。
但如果當前列表頁的地址跟鏈接的相對路徑有一部分重疊怎么辦?如下圖所示:
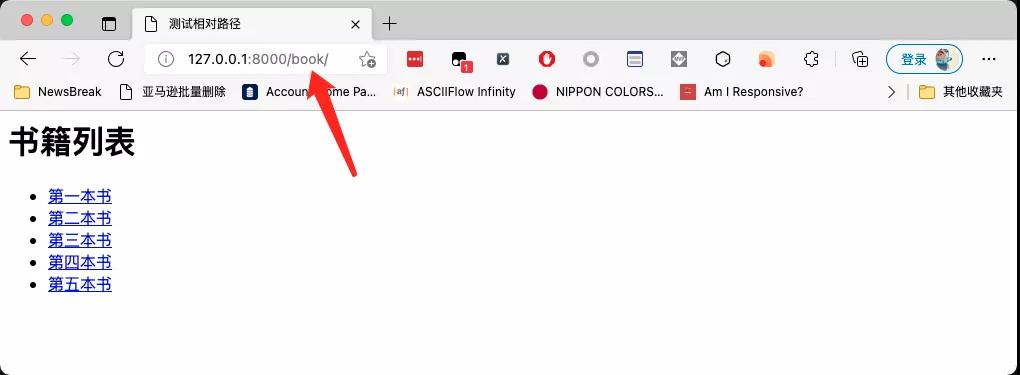
當前頁面的地址是http://127.0.0.1:8000/book。而相對地址是/book/1.html。這種情況下,還可以進一步簡化,在相對路徑的前面不要加斜杠,把HTML改成:
- <html>
- <head>
- <meta charset="utf-8">
- <title>測試相對路徑</title>
- </head>
- <body>
- <div>
- <h1>書籍列表</h1>
- <ul>
- <li><a href="1.html">第一本書</a></li>
- <li><a href="2.html">第二本書</a></li>
- <li><a href="3.html">第三本書</a></li>
- <li><a href="4.html">第四本書</a></li>
- <li><a href="5.html">第五本書</a></li>
- </ul>
- </div>
- </body>
- </html>
運行效果如下圖所示:
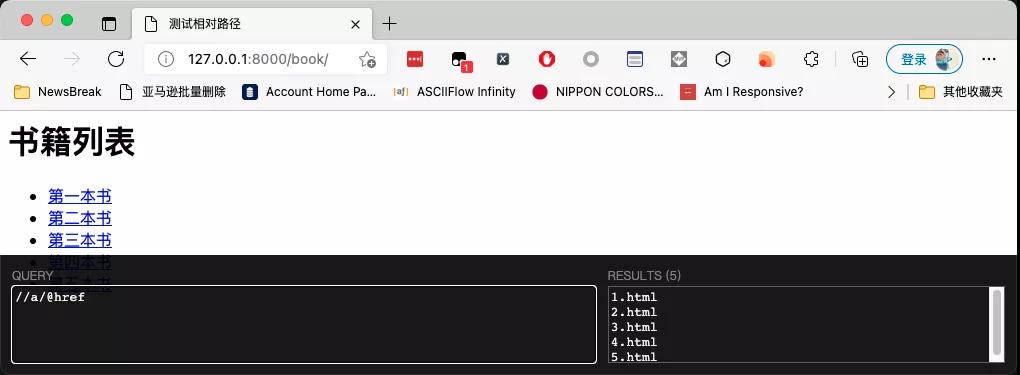
這種情況下,瀏覽器依然能給正確識別,如下圖所示:
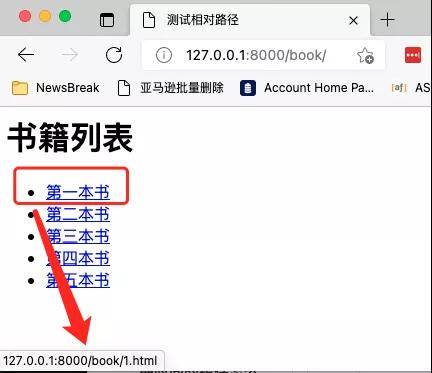
瀏覽器知道,如果相對路徑沒有用/開頭,那么它就會把當前頁面的URL與相對路徑拼接起來。但需要注意的是,在拼接的時候,會取最右側斜杠左邊的部分。而右邊的部分會丟棄。就相當于拼接文件地址的時候,用這個文件所在的文件夾來拼接新的地址。如下圖所示:
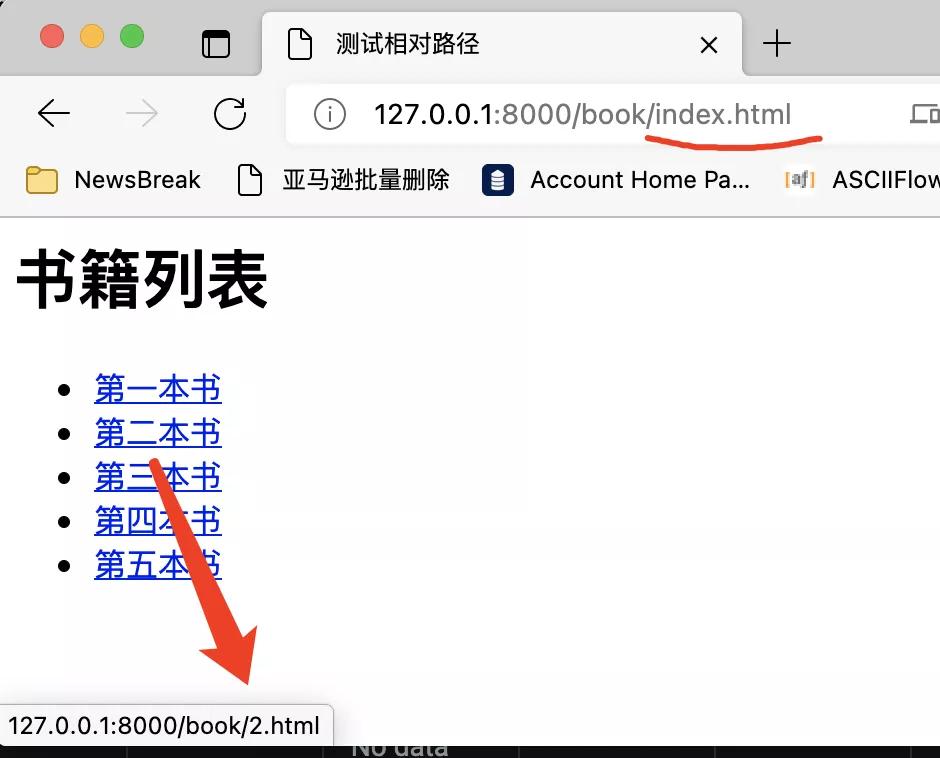
如果你記不住怎么區分的話,你可以使用Python自帶的urllib.parse.urljoin來連接,如下圖所示:
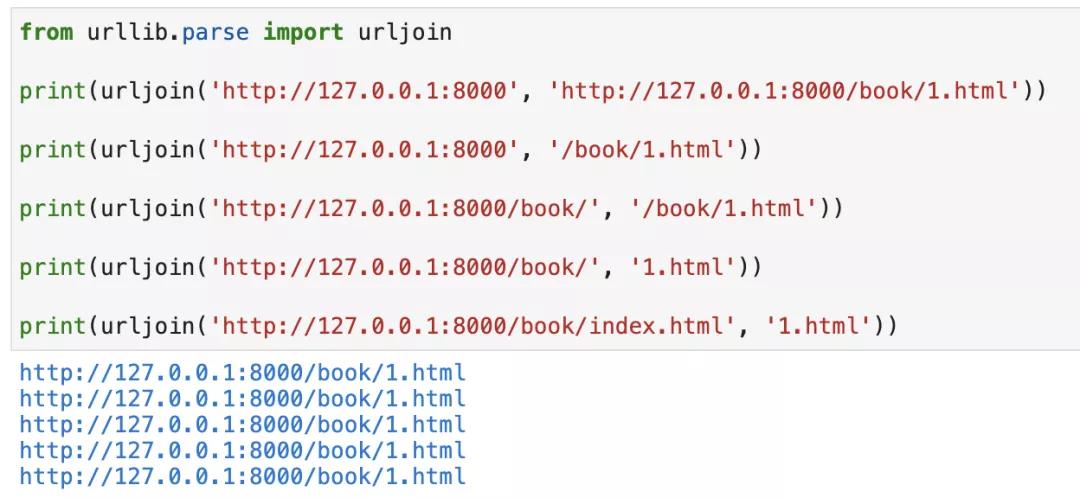
看到這里,你可能覺得我今天又水了一篇文章。這么簡單的東西也值得寫一篇文章來講?
那么我們來看下面這個例子:
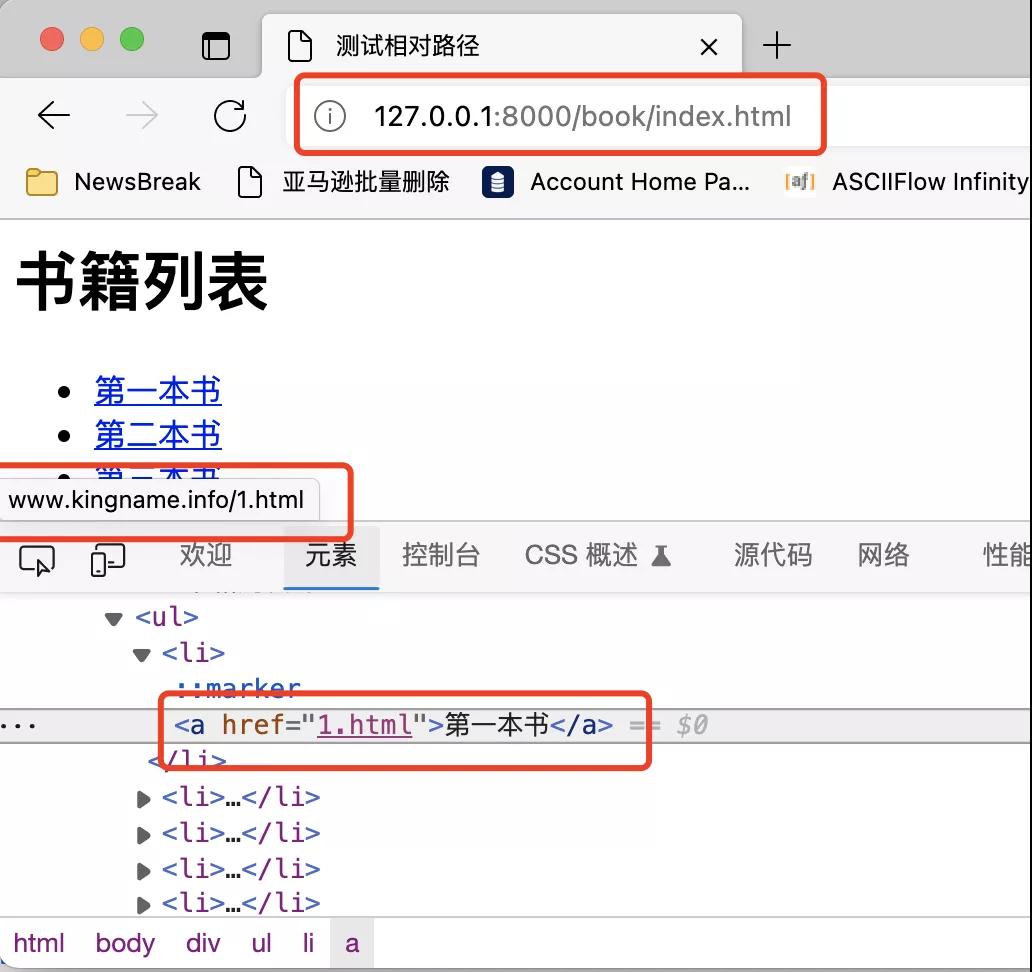
域名是http://127.0.0.1:8000/book/index.html,相對域名是1.html,但為什么瀏覽器自動識別出來的URL是www.kingname.info/1.html?
這個問題的關鍵,在于源代碼里面的標簽:
- <html>
- <head>
- <meta charset="utf-8">
- <title>測試相對路徑</title>
- <base href="http://www.kingname.info">
- </head>
- <body>
- <div>
- <h1>書籍列表</h1>
- <ul>
- <li><a href="1.html">第一本書</a></li>
- <li><a href="2.html">第二本書</a></li>
- <li><a href="3.html">第三本書</a></li>
- <li><a href="4.html">第四本書</a></li>
- <li><a href="5.html">第五本書</a></li>
- </ul>
- </div>
- </body>
- </html>
如果HTML代碼頭部有標簽,那么,它的href屬性的值,會被用來跟相對路徑拼接出一個絕對路徑,而不會再用當前頁面的URL來拼接。
如果你不知道這一點的話,你的爬蟲在拼接子頁面URL的時候可能就會出問題。網站也可以使用這個機制構造出一個蜜罐,根據標簽拼出來的URL才是真正的子頁面地址,而用當前頁面URL去拼接的URL是蜜罐地址,爬蟲訪問進去以后,就會抓到假數據,或者被立即屏蔽。
關于標簽的詳細說明,大家可以閱讀:: The Document Base URL element[1]。
參考文獻
[1] The Document Base URL element: https://developer.mozilla.org/en-US/docs/Web/HTML/Element/base



















