同事亂用分頁 MySQL 卡爆,我真是醉了...

背景
一天晚上10點半,下班后愉快的坐在在回家的地鐵上,心里想著周末的生活怎么安排。
突然電話響了起來,一看是我們的一個開發同學,頓時緊張了起來,本周的版本已經發布過了,這時候打電話一般來說是線上出問題了。
果然,溝通的情況是線上的一個查詢數據的接口被瘋狂的失去理智般的調用,這個操作直接導致線上的MySql集群被拖慢了。
好吧,這問題算是嚴重了,下了地鐵匆匆趕到家,開電腦,跟同事把Pinpoint上的慢查詢日志撈出來。看到一個很奇怪的查詢,如下
- 1 POST domain/v1.0/module/method?order=condition&orderType=desc&offset=1800000&limit=500
domain、module 和 method 都是化名,代表接口的域、模塊和實例方法名,后面的offset和limit代表分頁操作的偏移量和每頁的數量,也就是說該同學是在 翻第(1800000/500+1=3601)頁。初步撈了一下日志,發現 有8000多次這樣調用。
這太神奇了,而且我們頁面上的分頁單頁數量也不是500,而是 25條每頁,這個絕對不是人為的在功能頁面上進行一頁一頁的翻頁操作,而是數據被刷了(說明下,我們生產環境數據有1億+)。詳細對比日志發現,很多分頁的時間是重疊的,對方應該是多線程調用。
通過對鑒權的Token的分析,基本定位了請求是來自一個叫做ApiAutotest的客戶端程序在做這個操作,也定位了生成鑒權Token的賬號來自一個QA的同學。立馬打電話給同學,進行了溝通和處理。
分析
其實對于我們的MySQL查詢語句來說,整體效率還是可以的,該有的聯表查詢優化都有,該簡略的查詢內容也有,關鍵條件字段和排序字段該有的索引也都在,問題在于他一頁一頁的分頁去查詢,查到越后面的頁數,掃描到的數據越多,也就越慢。
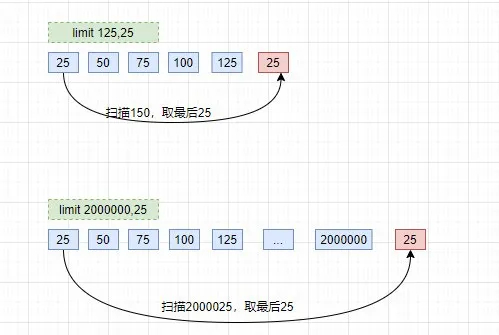
我們在查看前幾頁的時候,發現速度非常快,比如 limit 200,25,瞬間就出來了。但是越往后,速度就越慢,特別是百萬條之后,卡到不行,那這個是什么原理呢。先看一下我們翻頁翻到后面時,查詢的sql是怎樣的:
- 1 select * from t_name where c_name1='xxx' order by c_name2 limit 2000000,25;
這種查詢的慢,其實是因為limit后面的偏移量太大導致的。比如像上面的 limit 2000000,25 ,這個等同于數據庫要掃描出 2000025條數據,然后再丟棄前面的 20000000條數據,返回剩下25條數據給用戶,這種取法明顯不合理。
大家翻看《高性能MySQL》第六章:查詢性能優化,對這個問題有過說明:
分頁操作通常會使用limit加上偏移量的辦法實現,同時再加上合適的order by子句。但這會出現一個常見問題:當偏移量非常大的時候,它會導致MySQL掃描大量不需要的行然后再拋棄掉。
數據模擬
那好,了解了問題的原理,那就要試著解決它了。涉及數據敏感性,我們這邊模擬一下這種情況,構造一些數據來做測試。
1、創建兩個表:員工表和部門表
- 1 /*部門表,存在則進行刪除 */
- 2 drop table if EXISTS dep;
- 3 create table dep(
- 4 id int unsigned primary key auto_increment,
- 5 depno mediumint unsigned not null default 0,
- 6 depname varchar(20) not null default "",
- 7 memo varchar(200) not null default ""
- 8 );
- 9
- 10 /*員工表,存在則進行刪除*/
- 11 drop table if EXISTS emp;
- 12 create table emp(
- 13 id int unsigned primary key auto_increment,
- 14 empno mediumint unsigned not null default 0,
- 15 empname varchar(20) not null default "",
- 16 job varchar(9) not null default "",
- 17 mgr mediumint unsigned not null default 0,
- 18 hiredate datetime not null,
- 19 sal decimal(7,2) not null,
- 20 comn decimal(7,2) not null,
- 21 depno mediumint unsigned not null default 0
- 22 );
2、創建兩個函數:生成隨機字符串和隨機編號
- 1 /* 產生隨機字符串的函數*/
- 2 DELIMITER $
- 3 drop FUNCTION if EXISTS rand_string;
- 4 CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
- 5 BEGIN
- 6 DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmlopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
- 7 DECLARE return_str VARCHAR(255) DEFAULT '';
- 8 DECLARE i INT DEFAULT 0;
- 9 WHILE i < n DO
- 10 SET return_str = CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
- 11 SET ii = i+1;
- 12 END WHILE;
- 13 RETURN return_str;
- 14 END $
- 15 DELIMITER;
- 16
- 17
- 18 /*產生隨機部門編號的函數*/
- 19 DELIMITER $
- 20 drop FUNCTION if EXISTS rand_num;
- 21 CREATE FUNCTION rand_num() RETURNS INT(5)
- 22 BEGIN
- 23 DECLARE i INT DEFAULT 0;
- 24 SET i = FLOOR(100+RAND()*10);
- 25 RETURN i;
- 26 END $
- 27 DELIMITER;
3、編寫存儲過程,模擬500W的員工數據
- 1 /*建立存儲過程:往emp表中插入數據*/
- 2 DELIMITER $
- 3 drop PROCEDURE if EXISTS insert_emp;
- 4 CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
- 5 BEGIN
- 6 DECLARE i INT DEFAULT 0;
- 7 /*set autocommit =0 把autocommit設置成0,把默認提交關閉*/
- 8 SET autocommit = 0;
- 9 REPEAT
- 10 SET ii = i + 1;
- 11 INSERT INTO emp(empno,empname,job,mgr,hiredate,sal,comn,depno) VALUES ((START+i),rand_string(6),'SALEMAN',0001,now(),2000,400,rand_num());
- 12 UNTIL i = max_num
- 13 END REPEAT;
- 14 COMMIT;
- 15 END $
- 16 DELIMITER;
- 17 /*插入500W條數據*/
- 18 call insert_emp(0,5000000);
4、編寫存儲過程,模擬120的部門數據
- 1 /*建立存儲過程:往dep表中插入數據*/
- 2 DELIMITER $
- 3 drop PROCEDURE if EXISTS insert_dept;
- 4 CREATE PROCEDURE insert_dept(IN START INT(10),IN max_num INT(10))
- 5 BEGIN
- 6 DECLARE i INT DEFAULT 0;
- 7 SET autocommit = 0;
- 8 REPEAT
- 9 SET ii = i+1;
- 10 INSERT INTO dep( depno,depname,memo) VALUES((START+i),rand_string(10),rand_string(8));
- 11 UNTIL i = max_num
- 12 END REPEAT;
- 13 COMMIT;
- 14 END $
- 15 DELIMITER;
- 16 /*插入120條數據*/
- 17 call insert_dept(1,120);
5、建立關鍵字段的索引,這邊是跑完數據之后再建索引,會導致建索引耗時長,但是跑數據就會快一些。
- 1 /*建立關鍵字段的索引:排序、條件*/
- 2 CREATE INDEX idx_emp_id ON emp(id);
- 3 CREATE INDEX idx_emp_depno ON emp(depno);
- 4 CREATE INDEX idx_dep_depno ON dep(depno);
測試
測試數據
- 1 /*偏移量為100,取25*/
- 2 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 3 from emp a left join dep b on a.depno = b.depno order by a.id desc limit 100,25;
- 4 /*偏移量為4800000,取25*/
- 5 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 6 from emp a left join dep b on a.depno = b.depno order by a.id desc limit 4800000,25;
執行結果
- 1 [SQL]
- 2 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 3 from emp a left join dep b on a.depno = b.depno order by a.id desc limit 100,25;
- 4 受影響的行: 0
- 5 時間: 0.001s
- 6 [SQL]
- 7 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 8 from emp a left join dep b on a.depno = b.depno order by a.id desc limit 4800000,25;
- 9 受影響的行: 0
- 0 時間: 12.275s
因為掃描的數據多,所以這個明顯不是一個量級上的耗時。另外,MySQL 系列面試題和答案全部整理好了,微信搜索Java技術棧,在后臺發送:面試,可以在線閱讀。
解決方案
1、使用索引覆蓋+子查詢優化
因為我們有主鍵id,并且在上面建了索引,所以可以先在索引樹中找到開始位置的 id值,再根據找到的id值查詢行數據。
- 1 /*子查詢獲取偏移100條的位置的id,在這個位置上往后取25*/
- 2 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 3 from emp a left join dep b on a.depno = b.depno
- 4 where a.id >= (select id from emp order by id limit 100,1)
- 5 order by a.id limit 25;
- 6
- 7 /*子查詢獲取偏移4800000條的位置的id,在這個位置上往后取25*/
- 8 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 9 from emp a left join dep b on a.depno = b.depno
- 10 where a.id >= (select id from emp order by id limit 4800000,1)
- 11 order by a.id limit 25;
執行結果
執行效率相比之前有大幅的提升:
- 1 [SQL]
- 2 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 3 from emp a left join dep b on a.depno = b.depno
- 4 where a.id >= (select id from emp order by id limit 100,1)
- 5 order by a.id limit 25;
- 6 受影響的行: 0
- 7 時間: 0.106s
- 8
- 9 [SQL]
- 10 SELECT a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 11 from emp a left join dep b on a.depno = b.depno
- 12 where a.id >= (select id from emp order by id limit 4800000,1)
- 13 order by a.id limit 25;
- 14 受影響的行: 0
- 15 時間: 1.541s
2、起始位置重定義
記住上次查找結果的主鍵位置,避免使用偏移量 offset
- 1 /*記住了上次的分頁的最后一條數據的id是100,這邊就直接跳過100,從101開始掃描表*/
- 2 SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 3 from emp a left join dep b on a.depno = b.depno
- 4 where a.id > 100 order by a.id limit 25;
- 5
- 6 /*記住了上次的分頁的最后一條數據的id是4800000,這邊就直接跳過4800000,從4800001開始掃描表*/
- 7 SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 8 from emp a left join dep b on a.depno = b.depno
- 9 where a.id > 4800000
- 10 order by a.id limit 25;
執行結果
- 1 [SQL]
- 2 SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 3 from emp a left join dep b on a.depno = b.depno
- 4 where a.id > 100 order by a.id limit 25;
- 5 受影響的行: 0
- 6 時間: 0.001s
- 7
- 8 [SQL]
- 9 SELECT a.id,a.empno,a.empname,a.job,a.sal,b.depno,b.depname
- 10 from emp a left join dep b on a.depno = b.depno
- 11 where a.id > 4800000
- 12 order by a.id limit 25;
- 13 受影響的行: 0
- 14 時間: 0.000s
這個效率是最好的,無論怎么分頁,耗時基本都是一致的,因為他執行完條件之后,都只掃描了25條數據。
但是有個問題,只適合一頁一頁的分頁,這樣才能記住前一個分頁的最后Id。如果用戶跳著分頁就有問題了,比如剛剛刷完第25頁,馬上跳到35頁,數據就會不對。《MySQL 開發 36 條軍規》有必要看下。
這種的適合場景是類似百度搜索或者騰訊新聞那種滾輪往下拉,不斷拉取不斷加載的情況。這種延遲加載會保證數據不會跳躍著獲取。
3、降級策略
看了網上一個阿里的dba同學分享的方案:配置limit的偏移量和獲取數一個最大值,超過這個最大值,就返回空數據。
因為他覺得超過這個值你已經不是在分頁了,而是在刷數據了,如果確認要找數據,應該輸入合適條件來縮小范圍,而不是一頁一頁分頁。
這個跟我同事的想法大致一樣:request的時候 如果offset大于某個數值就先返回一個4xx的錯誤。
小結
當晚我們應用上述第三個方案,對offset做一下限流,超過某個值,就返回空值。第二天使用第一種和第二種配合使用的方案對程序和數據庫腳本進一步做了優化。
合理來說做任何功能都應該考慮極端情況,設計容量都應該涵蓋極端邊界測試。另外,關注公眾號Java技術棧,在后臺回復:面試,可以獲取我整理的 Java 系列面試題和答案,非常齊全。
另外,該有的限流、降級也應該考慮進去。比如工具多線程調用,在短時間頻率內8000次調用,可以使用計數服務判斷并反饋用戶調用過于頻繁,直接給予斷掉。
哎,大意了啊,搞了半夜,QA同學不講武德。
不過這是很美好的經歷了。