













終于有人把數(shù)據(jù)挖掘講明白了

隨著大型數(shù)據(jù)庫(kù)的建立和海量數(shù)據(jù)的不斷涌現(xiàn),人們迫切需要強(qiáng)有力的數(shù)據(jù)分析工具。但現(xiàn)實(shí)情況往往是“數(shù)據(jù)十分豐富,而信息相當(dāng)貧乏”。
快速增長(zhǎng)的海量數(shù)據(jù)被收集、存放在大型數(shù)據(jù)庫(kù)中,沒有強(qiáng)有力的工具,以人類現(xiàn)有的能力很難理解它們。因此,有人說大數(shù)據(jù)是數(shù)據(jù)“墳?zāi)?rdquo;。當(dāng)采用數(shù)據(jù)挖掘工具進(jìn)行數(shù)據(jù)分析時(shí),可以發(fā)現(xiàn)隱藏在大數(shù)據(jù)之中重要的數(shù)據(jù)內(nèi)容、模式,能對(duì)商務(wù)決策、知識(shí)庫(kù)、科學(xué)和醫(yī)學(xué)研究等做出巨大貢獻(xiàn)。為解決數(shù)據(jù)和信息之間的鴻溝,我們應(yīng)系統(tǒng)地學(xué)習(xí)數(shù)據(jù)挖掘知識(shí),開發(fā)數(shù)據(jù)挖掘工具,將數(shù)據(jù)“墳?zāi)?rdquo;變成知識(shí)“金礦”。
1數(shù)據(jù)挖掘過程
數(shù)據(jù)挖掘(data mining)又譯為資料探勘、數(shù)據(jù)采礦,是指從大量的、不完全的、有噪聲的、模糊的、隨機(jī)的數(shù)據(jù)中提取隱含在其中的、人們事先不知道的但又潛在有用的信息和知識(shí)的過程。
數(shù)據(jù)挖掘的具體過程描述如下:
1)數(shù)據(jù):進(jìn)行數(shù)據(jù)挖掘首先要有數(shù)據(jù),可以根據(jù)任務(wù)的目的選擇數(shù)據(jù)集,并篩選自己需要的數(shù)據(jù),或者根據(jù)實(shí)際情況構(gòu)造自己需要的數(shù)據(jù)。
2)預(yù)處理:確定數(shù)據(jù)集后,就要對(duì)數(shù)據(jù)進(jìn)行預(yù)處理,使數(shù)據(jù)能夠?yàn)槲覀兯谩?shù)據(jù)預(yù)處理可以提高數(shù)據(jù)質(zhì)量,包括準(zhǔn)確性、完整性和一致性。進(jìn)行數(shù)據(jù)預(yù)處理的方法有數(shù)據(jù)清理、數(shù)據(jù)集成、數(shù)據(jù)規(guī)約和數(shù)據(jù)變換等。
3)變換:進(jìn)行數(shù)據(jù)預(yù)處理后,對(duì)數(shù)據(jù)進(jìn)行變換,將數(shù)據(jù)轉(zhuǎn)換成一個(gè)分析模型,這個(gè)分析模型是針對(duì)數(shù)據(jù)挖掘算法建立的。建立一個(gè)真正適合數(shù)據(jù)挖掘算法的分析模型是數(shù)據(jù)挖掘成功的關(guān)鍵。
4)數(shù)據(jù)挖掘:對(duì)經(jīng)過轉(zhuǎn)換的數(shù)據(jù)進(jìn)行挖掘,除了選擇合適的挖掘算法外,其余一切工作都能自動(dòng)地完成。
5)解釋/評(píng)估:解釋并評(píng)估結(jié)果,最終得到知識(shí)。其使用的分析方法一般視數(shù)據(jù)挖掘操作而定,通常會(huì)用到可視化技術(shù)。
數(shù)據(jù)挖掘的具體過程如圖1所示。
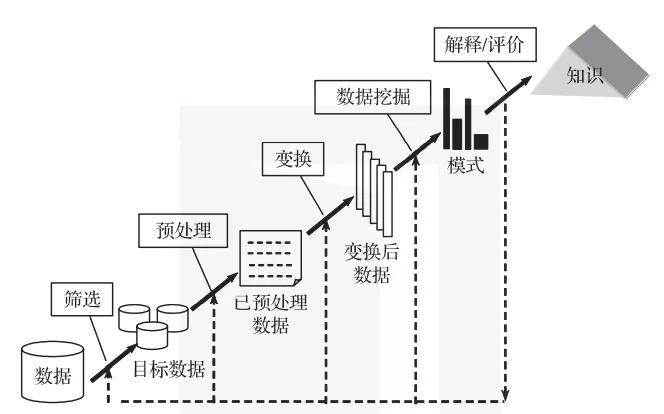
圖1 數(shù)據(jù)挖掘過程
2數(shù)據(jù)挖掘的內(nèi)容
2.1 關(guān)聯(lián)規(guī)則挖掘
從大規(guī)模數(shù)據(jù)中挖掘?qū)ο笾g的隱含關(guān)系稱為關(guān)聯(lián)分析(Associate Analysis)或者關(guān)聯(lián)規(guī)則挖掘(Associate Rule Mining),它可以揭示數(shù)據(jù)中隱藏的關(guān)聯(lián)模式,幫助人們進(jìn)行市場(chǎng)運(yùn)作、決策支持等。
考察一些涉及許多物品的事務(wù)。事務(wù)1中出現(xiàn)了物品甲,事務(wù)2中出現(xiàn)了物品乙,事務(wù)3中同時(shí)出現(xiàn)了物品甲和乙。那么,物品甲和乙在事務(wù)中的出現(xiàn)是否有規(guī)律可循呢?在數(shù)據(jù)庫(kù)的知識(shí)發(fā)現(xiàn)中,關(guān)聯(lián)規(guī)則就是描述這種在一個(gè)事務(wù)中物品同時(shí)出現(xiàn)的規(guī)律的知識(shí)模式。更確切地說,關(guān)聯(lián)規(guī)則通過量化的數(shù)字描述物品甲的出現(xiàn)對(duì)物品乙的出現(xiàn)有多大的影響。
一般采用可信度、支持度、期望可信度、作用度四個(gè)參數(shù)來描述一個(gè)關(guān)聯(lián)規(guī)則的屬性。
在關(guān)聯(lián)規(guī)則的四個(gè)屬性中,支持度和可信度能夠比較直接地形容關(guān)聯(lián)規(guī)則的性質(zhì)。如果不考慮關(guān)聯(lián)規(guī)則的支持度和可信度,那么在事務(wù)數(shù)據(jù)庫(kù)中可以發(fā)現(xiàn)無窮多的關(guān)聯(lián)規(guī)則。事實(shí)上,人們一般只對(duì)滿足一定的支持度和可信度的關(guān)聯(lián)規(guī)則感興趣。因此,為了發(fā)現(xiàn)有意義的關(guān)聯(lián)規(guī)則,需要給定兩個(gè)閾值:最小支持度和最小可信度,前者規(guī)定了關(guān)聯(lián)規(guī)則必須滿足的最小支持度;后者規(guī)定了關(guān)聯(lián)規(guī)則必須滿足的最小可信度。
經(jīng)典故事案例:關(guān)聯(lián)規(guī)則挖掘經(jīng)典的案例即為購(gòu)物籃中的啤酒和尿布的故事。“啤酒與尿布”的故事產(chǎn)生于20世紀(jì)90年代的美國(guó)沃爾瑪超市中,在美國(guó)有嬰兒的家庭中,一般由母親在家中照看嬰兒,年輕的父親前去超市購(gòu)買尿布。父親在購(gòu)買尿布的同時(shí),往往會(huì)順便為自己購(gòu)買啤酒,這樣就會(huì)出現(xiàn)啤酒與尿布這兩件看上去不相干的商品經(jīng)常會(huì)出現(xiàn)在同一個(gè)購(gòu)物籃的現(xiàn)象。
比如對(duì)于如下購(gòu)物籃數(shù)據(jù):
顧客1:{牛奶、果醬、面包}
顧客2:{牛奶、雞蛋、面包、糖}
顧客3:{面包、黃油、牛奶}
我們可以推測(cè)牛奶→面包為一組關(guān)聯(lián)規(guī)則,即顧客購(gòu)買了牛奶,可以推測(cè)該顧客下一步很有可能會(huì)購(gòu)買面包。
2.2 分類
分類算法是數(shù)據(jù)挖掘中的關(guān)鍵技術(shù),它通過對(duì)數(shù)據(jù)訓(xùn)練集的分析研究,發(fā)現(xiàn)分類規(guī)則,從而具備預(yù)測(cè)新數(shù)據(jù)類型的能力。分類也是監(jiān)督式機(jī)器學(xué)習(xí)方法,根據(jù)訓(xùn)練集學(xué)習(xí)模型,進(jìn)一步利用模型對(duì)新數(shù)據(jù)的類別標(biāo)簽進(jìn)行預(yù)測(cè)。分類算法主要包括兩個(gè)階段:①構(gòu)建模型階段,通過分析學(xué)習(xí)已知的訓(xùn)練數(shù)據(jù)集,訓(xùn)練并構(gòu)建一個(gè)準(zhǔn)確率可以接受的模型,該模型用于描述特定的數(shù)據(jù)類集;②使用階段,使用訓(xùn)練后的模型對(duì)未知數(shù)據(jù)對(duì)象進(jìn)行分類。具體過程如下所示。
- 第一步:類別標(biāo)簽學(xué)習(xí)建模(參見圖2)。
- 第二步:類別標(biāo)簽分類測(cè)試(參見圖3)。
分類標(biāo)簽預(yù)測(cè)與數(shù)值預(yù)測(cè)的區(qū)別如下:數(shù)值預(yù)測(cè)根據(jù)訓(xùn)練集學(xué)習(xí)模型,進(jìn)一步利用模型對(duì)新數(shù)據(jù)的數(shù)值進(jìn)行預(yù)測(cè),區(qū)別于分類標(biāo)簽預(yù)測(cè),數(shù)值預(yù)測(cè)的輸出為連續(xù)的數(shù)值。

圖2 分類學(xué)習(xí)建模

圖3 分類測(cè)試
數(shù)值預(yù)測(cè)學(xué)習(xí)的流程如下。
第一步:數(shù)值預(yù)測(cè)學(xué)習(xí)建模(參見圖4)。
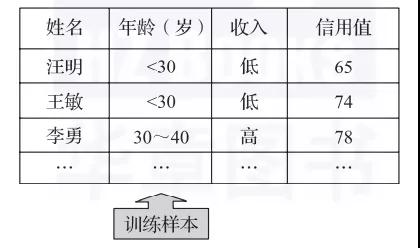
圖4 數(shù)值預(yù)測(cè)學(xué)習(xí)建模
第二步:數(shù)值預(yù)測(cè)測(cè)試(參見圖5)。
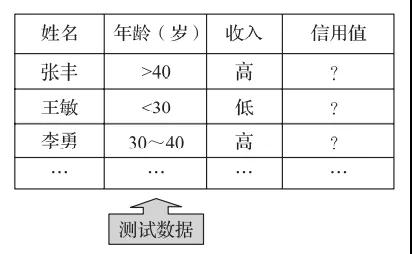
圖5 數(shù)值預(yù)測(cè)測(cè)試
下面來看一個(gè)分類標(biāo)簽預(yù)測(cè)案例和一個(gè)數(shù)值預(yù)測(cè)案例。
(1)分類標(biāo)簽預(yù)測(cè)案例:?jiǎn)T工離職預(yù)測(cè)
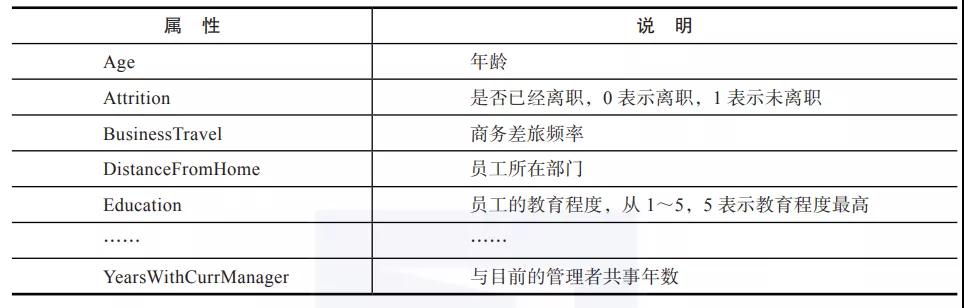
根據(jù)給定的影響員工離職的因素和員工是否離職的記錄,建立一個(gè)模型預(yù)測(cè)有可能離職的員工,具體數(shù)據(jù)如表1所示。其中,Attrition表示類別標(biāo)簽,也就是需要預(yù)測(cè)的離散數(shù)據(jù)。
表1 員工離職數(shù)據(jù)
(2)數(shù)值預(yù)測(cè)案例:房?jī)r(jià)預(yù)測(cè)
作為一個(gè)典型的數(shù)值預(yù)測(cè)案例,房?jī)r(jià)預(yù)測(cè)一直備受關(guān)注。簡(jiǎn)言之,房?jī)r(jià)預(yù)測(cè)就是綜合房屋銷售價(jià)格以及房屋的基本信息建立模型,從而預(yù)測(cè)其他房屋的銷售價(jià)格。
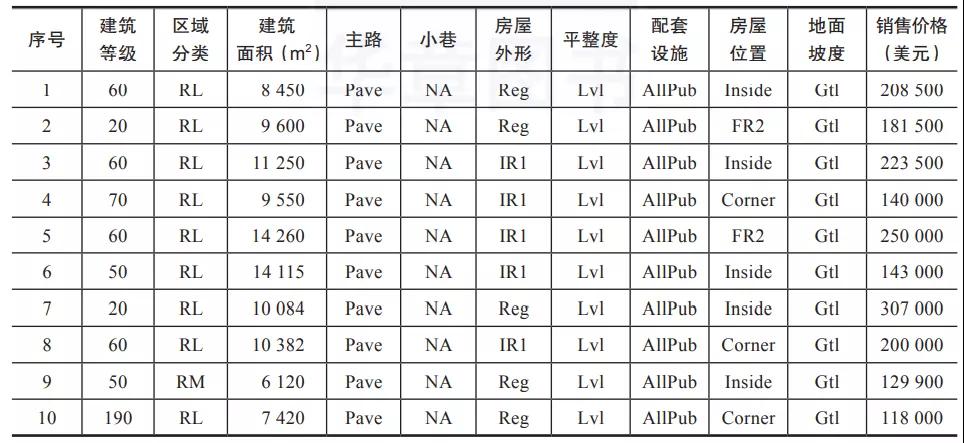
我們以Kaggle平臺(tái)房?jī)r(jià)預(yù)測(cè)的部分?jǐn)?shù)據(jù)集(見表2)為例進(jìn)行說明。如表2所示,房屋的基本信息主要包括建筑等級(jí)、區(qū)域分類、建筑面積、主路、小巷、房屋外形、平整度、配套設(shè)施、房屋位置、地面坡度和銷售價(jià)格,等等。其中,“銷售價(jià)格”便是需要預(yù)測(cè)的連續(xù)數(shù)值。
表2 Kaggle房?jī)r(jià)預(yù)測(cè)數(shù)據(jù)集示例
2.3 聚類
聚類為非監(jiān)督式機(jī)器學(xué)習(xí)方法,不需要提供具有標(biāo)簽的訓(xùn)練集,而是直接以某種聚類準(zhǔn)則將數(shù)據(jù)劃分到不同類別中。聚類分析的結(jié)果通常受聚類準(zhǔn)則的影響,圖6所示的聚類準(zhǔn)則如果設(shè)為“花色相同”和“符號(hào)相同”,則得到兩種不同的聚類結(jié)果。
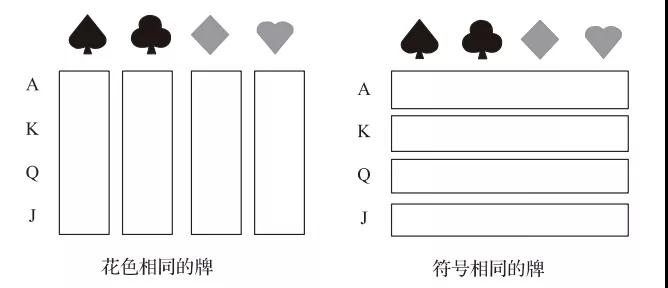
圖6 聚類準(zhǔn)則影響結(jié)果示意
2.4 回歸
回歸分析(regression analysis)是一個(gè)統(tǒng)計(jì)預(yù)測(cè)模型,用于描述和評(píng)估應(yīng)變量與一個(gè)或多個(gè)自變量之間的關(guān)系,包括一元線性回歸、多元線性回歸、非線性回歸、邏輯回歸等。具體來說,可以利用回歸模型來實(shí)現(xiàn)數(shù)值預(yù)測(cè)的任務(wù),比如前面提到的房?jī)r(jià)預(yù)測(cè)任務(wù)。
當(dāng)自變量為非隨機(jī)變量、因變量為隨機(jī)變量時(shí),分析它們的關(guān)系稱為回歸分析;根據(jù)回歸分析可以建立變量間的數(shù)學(xué)表達(dá)式,稱為回歸方程。回歸方程反映自變量在固定條件下因變量的平均狀態(tài)變化情況。相關(guān)分析是以某一指標(biāo)來度量回歸方程所描述的各個(gè)變量間關(guān)系的密切程度。
回歸分析方法常用于解釋市場(chǎng)占有率、銷售額、品牌偏好及市場(chǎng)營(yíng)銷效果。把兩個(gè)或兩個(gè)以上定距或定比例的數(shù)量關(guān)系用函數(shù)形式表示出來,就是回歸分析要解決的問題。
本文摘編于《數(shù)據(jù)挖掘:原理與應(yīng)用》,經(jīng)出版方授權(quán)發(fā)布。(書號(hào):9787111696308)轉(zhuǎn)載請(qǐng)保留文章來源。



















